↑↑↑关注后星标机器学习与推荐算法
目前,对于基于向量召回,那就不得不提到双塔。为什么双塔在工业界这么常用?双塔上线有多方便,真的是谁用谁知道,user塔做在线serving,item塔离线计算embeding建索引,推到线上即可。
下面我就给大家介绍一些来自
微软、Facebook、Baidu、YouTube
的经典双塔模型。
![]()
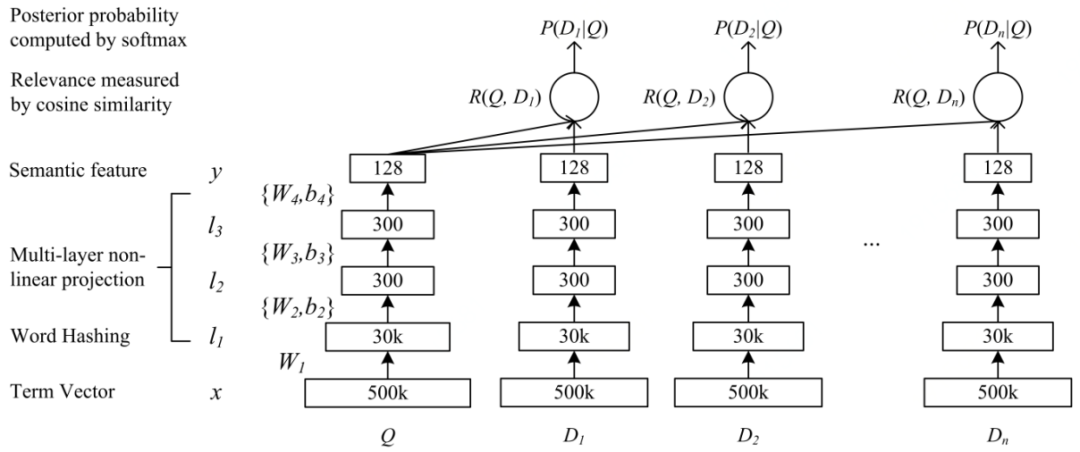
先说双塔模型的鼻祖,这是微软在CIKM2013发表的一篇工作,它主要是用来解决NLP领域语义相似度任务的。Word hashing真的是DSSM的骚操作了,不同于现有的RNN,Bert等模型,该方法直接把文本映射成了远低于vocab size的向量中,然后输入DNN,输出得到一个128维的低维语义向量。
Query和document的语义相似度就可以用这两个向量的cosine相似度来表示,进一步我们可以通过softmax对不同的document做排序。这就是最初的DSSM。如果把把document换成item或是广告,就演变成了一个推荐模型。
说来说去,主要就是实时性好,cos的表达是有限的,很难提取交叉特征,所以双塔还是比较适用于召回场景。
![]()
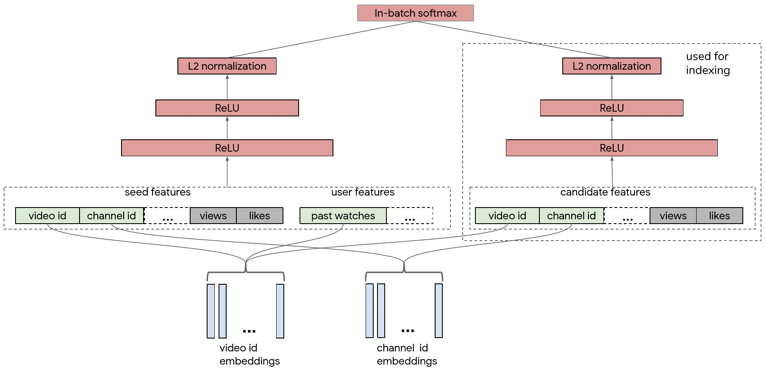
YouTube最新正在使用的视频召回双塔模型。这个模型在整体上就是最普通的双塔。左边是user塔,输入包括两部分,第一部分seed是user当前正在观看的视频,第二部分user的feature是根据user的观看历史计算的,比如说可以使用user最近观看的k条视频的id emb均值,这两部分融合起来一起输入user侧的DNN。右边是item塔,将候选视频的feature作为输入,计算item的 embedding。之后再计算相似度,做排序就可以了。
YouTube这个模型最大的不同是,它的训练是基于
流数据
的,每一天都会产生新的训练数据。因此,负样本的选择只能在batch内进行,batch内的所有样本作为彼此的负样本去做batch softmax。这种采样的方式带来了非常大的bias。一条热门视频,它的采样概率更高,因此会更多地被当做负样本,这不符合实际。因此这篇工作的核心就是减小batch内负采样带来的bias。
![]()
这篇工作的两个核心亮点是hard negative mining和embedding ensemble。
Hard negative mining
是指,他们发现如果将随机负样本这种比较easy的样本与上次召回中排名101-500名的比较hard的样本以100:1的比例去训练模型(为什么是101-500?),得到的效果会比较好。
Embedding ensemble
是指,可以将不同负样本训练得到的模型做融合来进行召回。融合的方式可以是相似度结果的直接加权或者是模型的串行融合,比如先用easy负样本训练模型进行初步的筛选,再用hard负样本训练模型进行最终的召回。
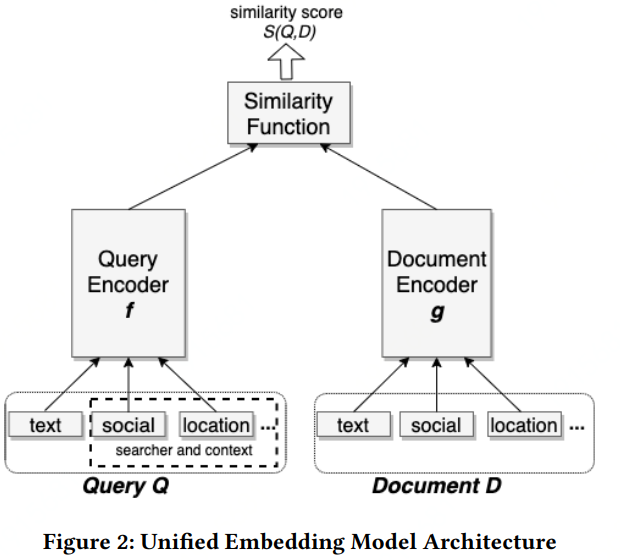
另外他们还提到虽然使用unified的特征,就是输入中包含社交特征和位置特征,来进行召回效果会比较好,但是召回结果在一定程度上也会损失文本的匹配,因此也可以先通过只输入文本特征的模型来做筛选再用输入unified特征的模型来召回,这样可以保证文本的匹配。
![]()
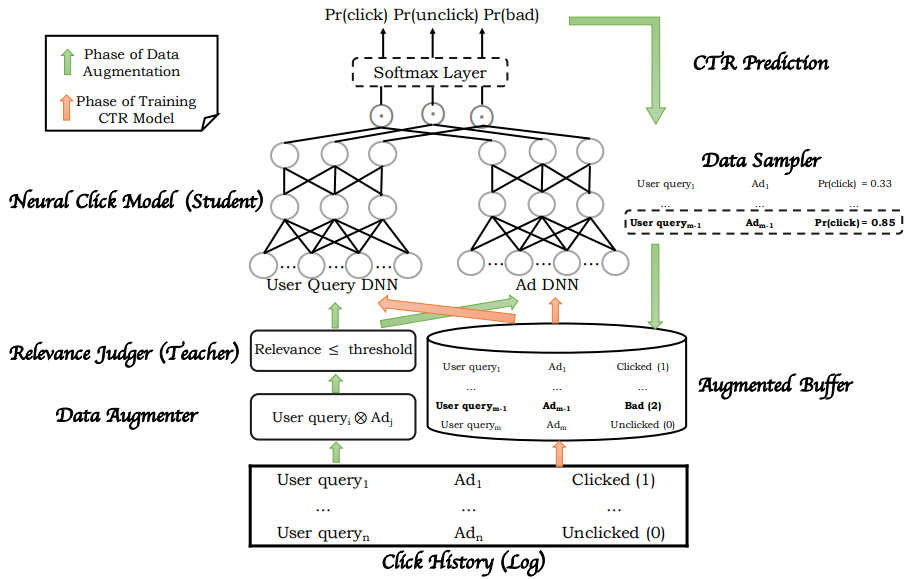
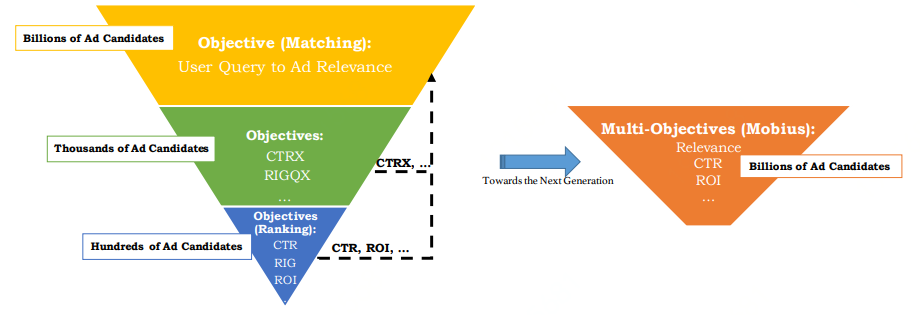
百度可不止有简单可依赖的模型,也有复杂可依赖的。整个框架分为两个阶段,
数据增强阶段
是绿色箭头的部分,采样并利用样本中的用户请求与广告构造出更多样本,教师网络计算相似度后将低相似度的样本输入学生网络去预测CTR,通过采样的方式得到高CTR低相似度的样本存入buffer,这类样本我们称之为bad case。
第二个阶段是橙色箭头表示的
CTR模型训练阶段
,将原先采样得到的原始样本也存入buffer,利用buffer中的三种样本去训练CTR模型。虽然百度提出了这样一种框架,但是召回和排序的直接统一在实现的过程中还是比较困难的,因为面临的候选广告集数量太大,在性能方面还是难以保证。但是Mobius的这种将商业指标提前引入召回阶段的思想是非常具有探索价值的,比如文章中提到将cosine相似度直接乘上一个商业指标作为系数,就是一个很简单的方式。
![]()
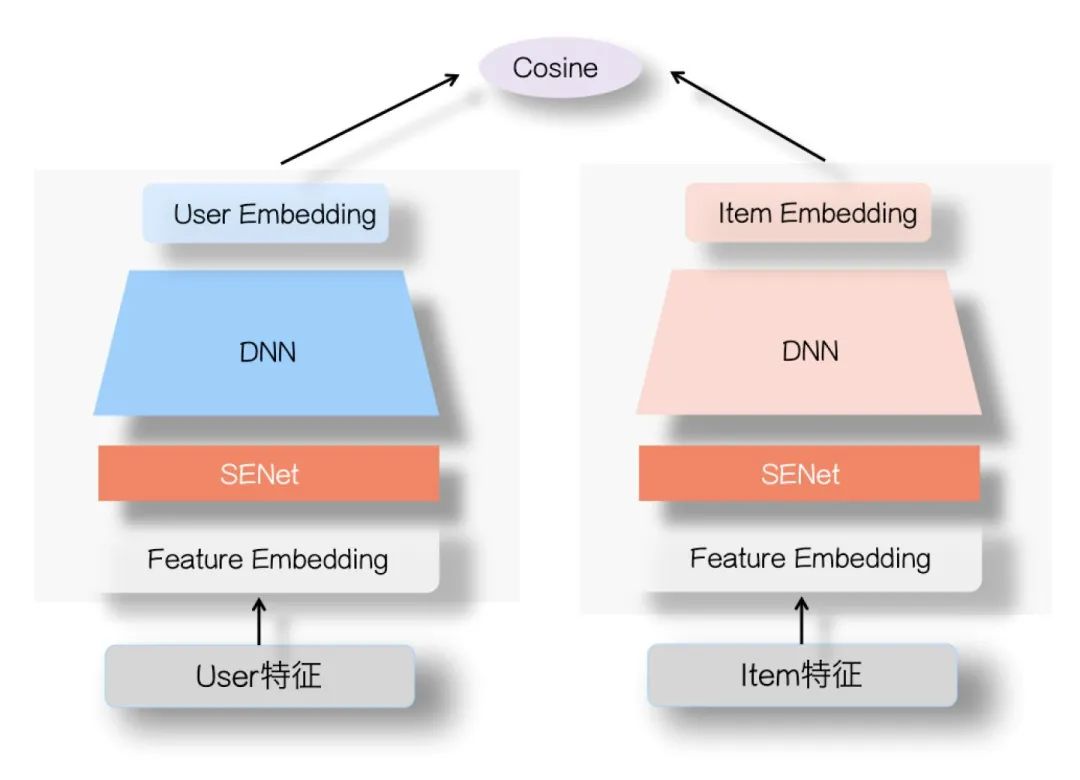
参考上图,其实很简单,就是在用户侧塔和Item侧塔,在特征Embedding层上,各自加入一个SENet模块就行了,两个SENet各自对User侧和Item侧的特征,进行动态权重调整,强化那些重要特征,弱化甚至清除掉(如果权重为0的话)不重要甚至是噪音的特征。其余部分和标准双塔模型是一样的。20年年底,我们在业务数据测试,加入SENet的双塔模型,与标准双塔模型比,在多个业务指标都有提升,在个别指标有较大的效果提升。而且,如果引入ID类特征,这种优势会更明显。
那么,为什么SENet双塔模型是有效的呢?我是这么看的:在前面,我们谈过双塔模型有个内生性的问题,就是为了速度快,这种两侧分离结构,必然会导致效果损失。而如果归因的话,比较重要的一个原因,是User侧特征和Item侧特征交互太晚,在高层交互,会造成细节信息,也就是具体特征信息的损失,影响两侧特征交叉的效果。站在这个前提下,我们再审视下FM模型和DNN双塔模型各自的特点。
在面临海量候选数据进行粗筛的场景下,它的速度太快了,效果说不上极端好,但是毕竟是个有监督学习过程,一般而言也不差,实战价值很高,这个是根本。若一个应用场景有如下需求:应用面临大量的候选集合,首先需要从这个集合里面筛选出一部分满足条件的子集合,缩小筛查范围。那么,这种应用场景就比较适合用双塔模型。
那双塔模型这么方便就没有什么缺点吗?当然有,它在一定程度上牺牲掉模型的部分精准性,而且这个代价是结构内生的,也就是说它这种结构必然会面临这样的问题。
![]()
是"塔"!是"塔"!就是它,我们的双塔!
SENet双塔模型:在推荐领域召回粗排的应用及其它
https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf
https://dl.acm.org/doi/pdf/10.1145/3298689.3346996
https://dl.acm.org/doi/pdf/10.1145/3394486.3403305
http://research.baidu.com/Public/uploads/5d12eca098d40.pdf
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。