机器之心 & ArXiv Weekly Radiostation
本周重要论文包括腾讯深度学习推荐系统首次入选 OSDI 顶会;罗彻斯特大学和 Adobe Research 的研究者提出新模型 CM-GAN,可以修复大面积缺失图像。
-
Ekko: A Large-Scale Deep Learning Recommender System with Low-Latency Model Update
-
Wave equations estimates and the nonlinear stability of slowly rotating Kerr black holes
-
Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
-
Why do tree-based models still outperform deep learning on tabular data?
-
Bioadhesive ultrasound for long-term continuous imaging of diverse organs
-
ETHSeg: An Amodel Instance Segmentation Network and a Real-world Dataset for X-Ray Waste Inspection
-
Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
-
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Ekko: A Large-Scale Deep Learning Recommender System with Low-Latency Model Update
-
作者:Chijun Sima 、 Yao Fu 等
-
论文地址:https://www.usenix.org/system/files/osdi22-sima.pdf
摘要:
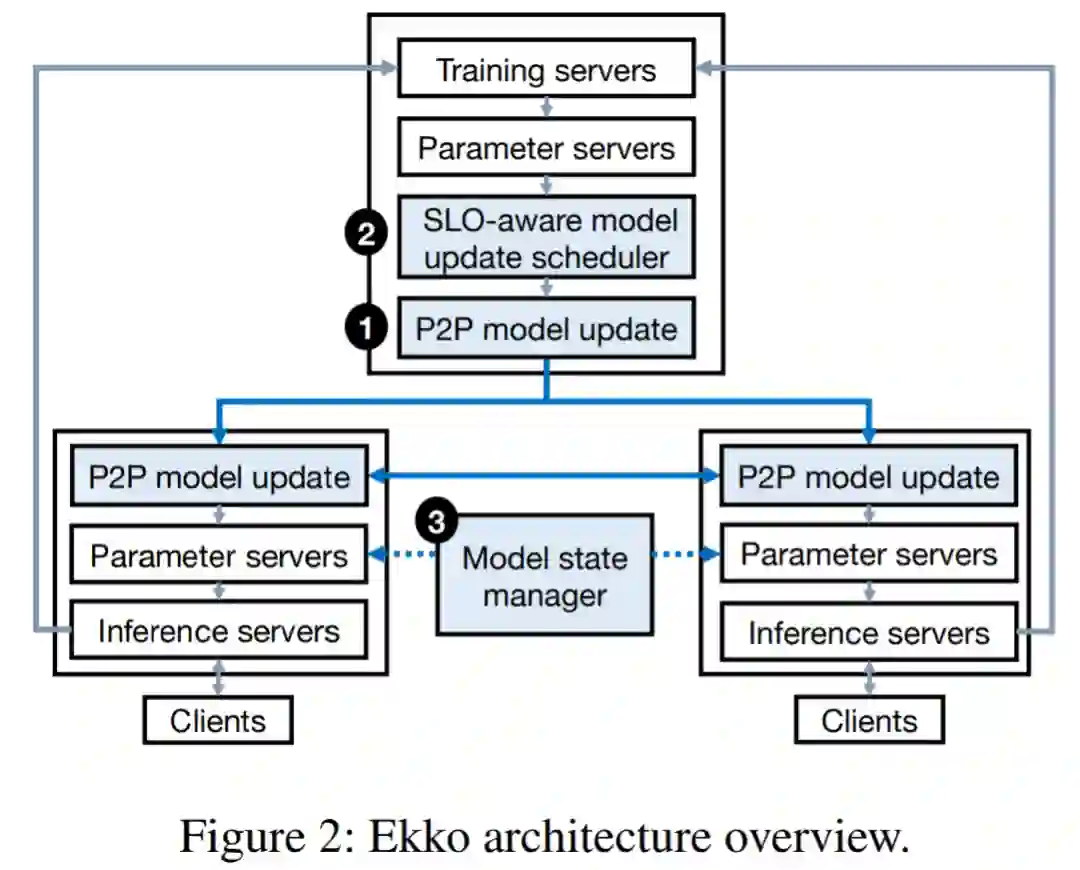
腾讯与爱丁堡大学等科研机构合作完成了一项研究,推出了一种既不牺牲 SLO(服务等级目标) 又能实现低延迟模型更新的大规模深度学习推荐系统—Ekko,其速度比当前 SOTA DLRS 系统实现数量级提升,并且早已部署在了腾讯的生产环境中,为用户提供各类推荐服务。
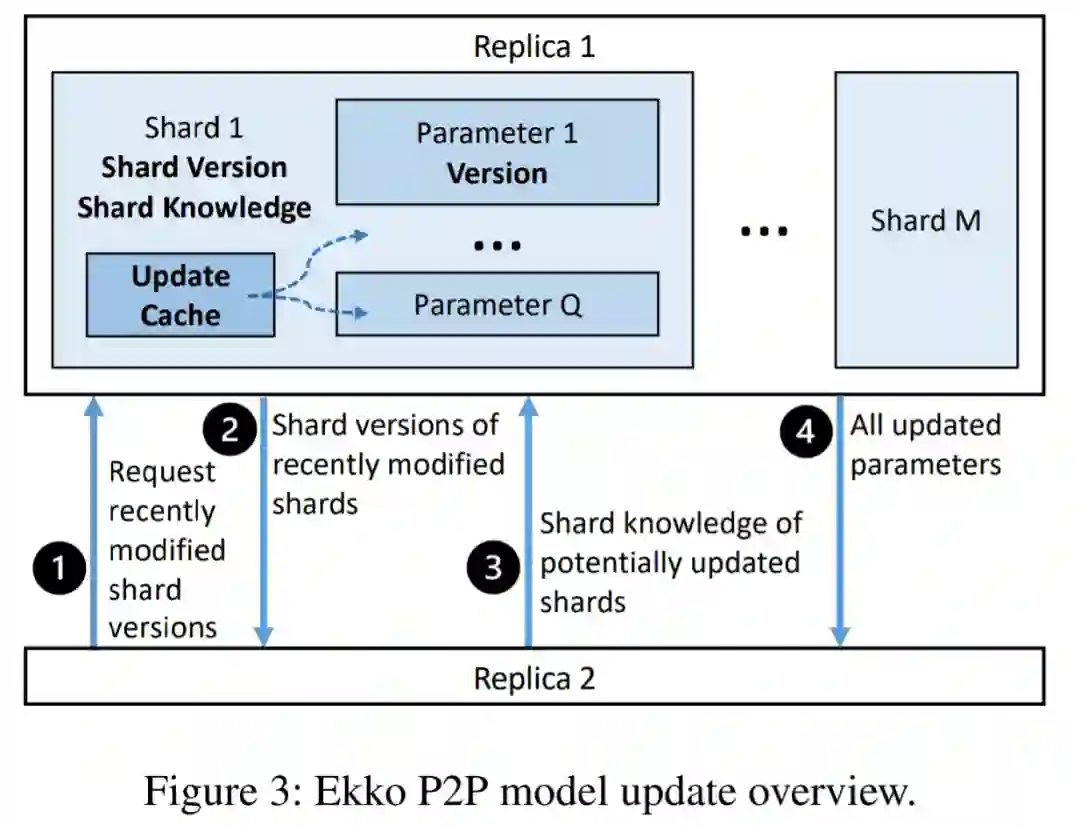
他们首先设计了一种高效的点对点模型更新传播算法。现有参数服务器往往采用 primary-backup 数据复制协议来实现模型更新,但当处理大规模模型更新时,这种方式因长更新延迟和 leader 瓶颈而导致扩展性不足。因此,研究者探索通过点对点的方式来进行模型更新传播,利用更新 DLRS 模型过程中的稀疏性和时间局部性来提高更新模型的吞吐量,降低更新模型的延迟。
其次,Ekko 提供了一个 SLO 保护机制。Ekko 允许模型更新在不需要离线模型验证也能达到推理集群,不过这种设计会导致 SLO 在生产环境中容易受到网络拥塞和有偏更新的影响。因此,为了处理网络拥塞,研究者设计了一个 SLO 感知的模型更新调度器,其计算指标包括更新新鲜度优先级、更新重要性优先级和模型优先级。这些指标都能预测模型更新对推理 SLO 的影响,基于它们,调度器在线计算每个模型更新的优先级。研究者将调度器集成到参数服务器,而不改变 Ekko 中点到点模型更新传播的去中心化架构。
最后,Ekko 使用一种新颖的推理模型状态管理器来处理有偏更新,该管理器为每组推理模型创建了一个基线模型。然后,基线模型接收少量用户流量,并作为推理模型的真值。同时,管理器持续为基线和推理模型监控与质量相关的 SLO。当有偏模型更新破坏了推理模型的状态时,管理器会通知见证服务器将模型回滚到健康状态。
研究者利用测试台和大规模生产集群对它进行了评估。其中测试台实验结果表明,与 SOTA 参数服务器相比,Ekko 将模型更新延迟最高降低了 7 倍。研究者进一步使用 40TB 的模型和地理分布区域内的 4600 多台服务器上进行大规模生产实验,结果表明,Ekko 在实现 2.4 秒传播更新的同时每秒执行 10 亿次更新。Ekko 仅将总网络带宽的 3.0% 用于同步,余下部分用于训练和推理。这种秒级延迟性能比 SOTA DLRS 基础设施(如 TFRA 和 Check-N-Run)实现的分钟级延迟快了几个数量级。
推荐:
每秒 10 亿次更新、实现秒级同步延迟,腾讯深度学习推荐系统首次入选 OSDI 顶会。
论文 2:Wave equations estimates and the nonlinear stability of slowly rotating Kerr black holes
-
作者:Elena Giorgi、Sergiu Klainerman、J´er´emie Szeftel
-
论文地址:https://arxiv.org/pdf/2205.14808.pdf
摘要:
在今年 5 月发表的一篇多达 912 页论文《 Wave equations estimates and the nonlinear stability of slowly rotating Kerr black holes 》中,来自哥伦比亚大学的 Szeftel、Elena Giorgi 和普林斯顿大学的 Sergiu Klainerman 证明了缓慢旋转的克尔黑洞确实是稳定的。
来自苏黎世联邦理工学院的数学家 Demetrios Christodoulou 表示,「这个新结果确实构成了广义相对论数学发展的一个里程碑。」
华人数学家丘成桐对这一项研究也同样给与很高的评价,称这项研究是自 1990 年代初以来,首个在广义相对论领域获得重大突破的研究。这一问题确实是一个非常棘手的问题,然而,新论文尚未经过同行评审。不过他们在 2021 年发表的论文已经过审,既完整又令人兴奋。
三位研究者依赖的策略被称为反证法,以前也在相关工作中使用过。大致思路是这样的:研究者假设与他们自己试图证明的相反,即克尔解决方案不会永远存在,这就意味着在一个最长时间之后就会失效。然后,他们使用了一些数学技巧,即对偏微分方程的分析,这是广义论的核心,将克尔解决方案扩展到声称的最长时间之外。
换言之,研究者证明了,无论最长时间的值是多少,它总是可以被扩展的。因此,研究者最初的假设是矛盾的,也就意味着猜想本身一定是正确的。研究人员称他们是建立在其他人的工作之上。此前曾出现过四次认真的尝试,他们的成功是幸运的。因而,他将这项新的贡献视为「整个领域的胜利」。
论文 3:Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
-
作者:Haitian Zheng 、 Zhe Lin 、 Jingwan Lu 等
-
论文地址:https://arxiv.org/pdf/2203.11947.pdf
摘要:
来自罗彻斯特大学和 Adobe Research 的研究者提出了一种新的生成网络:CM-GAN(cascaded modulation GAN),该网络可以更好地合成整体结构和局部细节。CM-GAN 中包括一个带有傅里叶卷积块的编码器,用于从带有空洞的输入图像中提取多尺度特征表征。CM-GAN 中还有一个双流解码器,该解码器在每个尺度层都设置一个新型级联的全局空间调制块。
在每个解码器块中,研究者首先应用全局调制来执行粗略和语义感知的结构合成,然后进行空间调制来进一步以空间自适应方式调整特征图。此外,该研究设计了一种物体感知训练方案,以防止空洞内产生伪影,从而满足现实场景中物体移除任务的需求。该研究进行了广泛的实验表明,CM-GAN 在定量和定性评估方面都显著优于现有方法。
新架构 CM-GAN 可以很好地综合整体结构和局部细节,如下图 1 所示。
推荐:
图像大面积缺失,也能逼真修复,新模型 CM-GAN 兼顾全局结构和纹理细节。
论文 4:Why do tree-based models still outperform deep learning on tabular data?
-
作者:Léo Grinsztajn 、 Edouard Oyallon 、 Gaël Varoquaux
-
论文地址:https://hal.archives-ouvertes.fr/hal-03723551/document
摘要:
来自法国国家信息与自动化研究所、索邦大学等机构的研究者提出了一个表格数据基准,其能够评估最新的深度学习模型,并表明基于树的模型在中型表格数据集上仍然是 SOTA。
该研究为表格数据创建了一个新的基准(选取了 45 个开放数据集),并通过 OpenML 共享这些数据集,这使得它们易于使用。
该研究在表格数据的多种设置下比较了深度学习模型和基于树的模型,并考虑了选择超参数的成本。该研究还分享了随机搜索的原始结果,这将使研究人员能够廉价地测试新算法以获得固定的超参数优化预算。
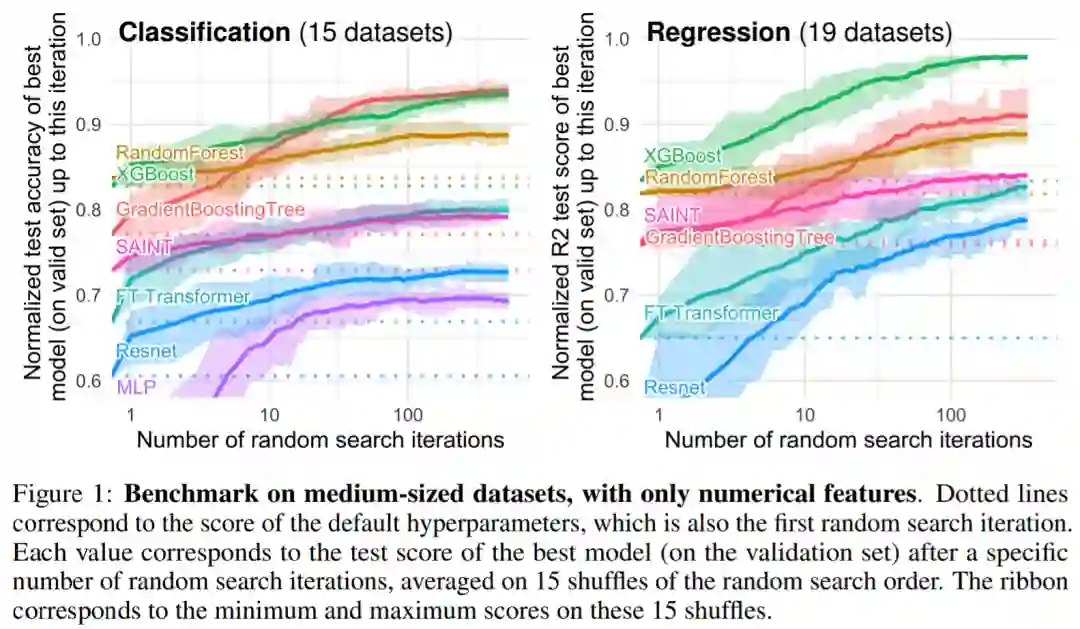
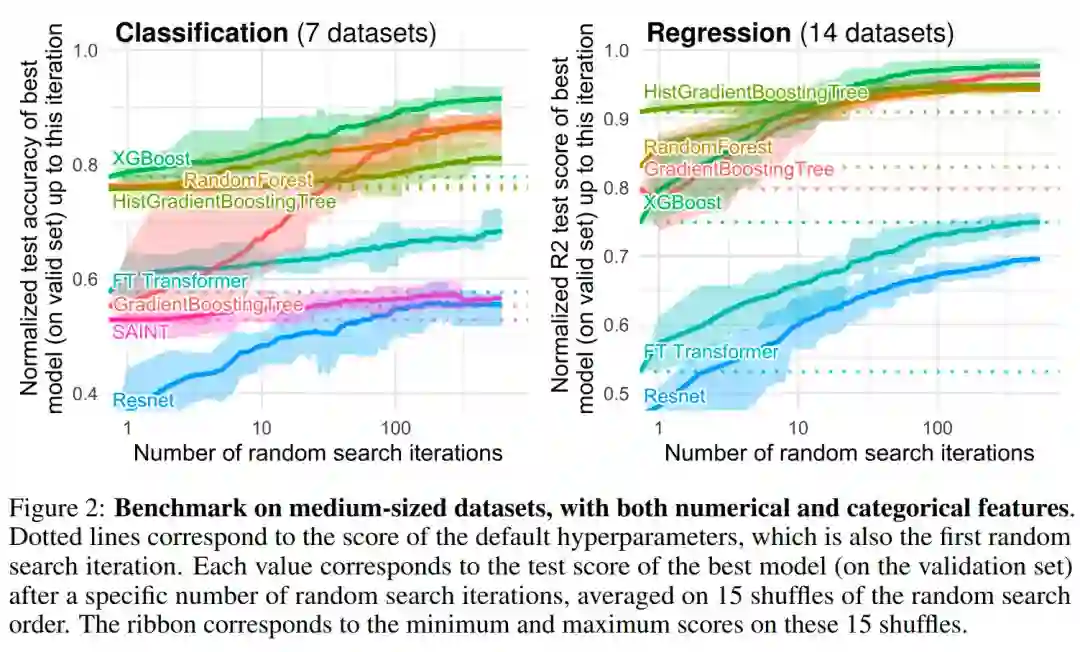
在基于树的模型中,研究者选择了 3 种 SOTA 模型:Scikit Learn 的 RandomForest,GradientBoostingTrees (GBTs) , XGBoost 。该研究对深度模型进行了以下基准测试:MLP、Resnet 、FT Transformer、SAINT 。
图 1 和图 2 给出了不同类型数据集的基准测试结果:
推荐:
在表格数据上,为什么基于树的模型仍然优于深度学习?
论文 5:Bioadhesive ultrasound for long-term continuous imaging of diverse organs
-
作者:CHONGHE WANG、XIAOYU CHEN 等
-
论文地址:https://www.science.org/doi/10.1126/science.abo2542
摘要:
近日,发表在顶级科学期刊《Science》的一篇论文中,MIT 的工程师们展示了他们的超声波成像贴片。这种贴片大概只有邮票大小,但可以贴在皮肤上并连续 48 小时成像。
![]()
研究人员将这些贴片贴在志愿者身上,并向他们展示了这些设备产生的血管和心脏、肺、胃等深层器官的高分辨率实时图像。当志愿者进行各种活动(包括坐、站、慢跑和骑自行车)时,这些贴片保持了很强的粘附力,并捕捉到了器官的变化。
目前的设计要求把贴片连接到将反射声波转换成图像的仪器上。不过,研究人员指出,即使以目前的形式,这种贴片也可以立即应用,例如应用于医院的病人,类似于心脏监测心电图贴片。它可以针对内部器官连续成像,而不需要技术人员长时间将探头固定在原位。
研究小组目前正在研究这种贴片的无线版本,如果这个目标得以实现,超声波贴片就可以制成可穿戴的成像产品,患者可以从医院带回家,甚至可以在药店购买。
推荐:
把 B 超探头做成贴纸贴在身上,48 小时不间断成像,MIT 新研究登上 Science。
论文 6:ETHSeg: An Amodel Instance Segmentation Network and a Real-world Dataset for X-Ray Waste Inspection
-
-
论文地址:https://openaccess.thecvf.com/content/CVPR2022/papers/Qiu_ETHSeg_An_Amodel_Instance_Segmentation_Network_and_a_Real-World_Dataset_CVPR_2022_paper.pdf
摘要:
近些年来,社会的发展带来了生活垃圾的爆发性增长,实行垃圾分类既可以减少对自然环境的破坏,同时对垃圾中的可回收资源进行回收再利用,也带来更大经济效益。垃圾分类的的检查工作是其中的重要一环,只有正确的分类才能提升回收效率和避免环境污染。传统的分类检查方法依赖于人工的翻阅。而现有的图像检查方法也需要打开垃圾袋并且把垃圾摊开。这些检查方法存在两大缺点:
翻开垃圾袋的过程比较繁琐,且对于接触垃圾的人存在污染、传播疾病的风险;
复杂繁多的垃圾容易产生视线遮挡,容易出现遗漏和错判。
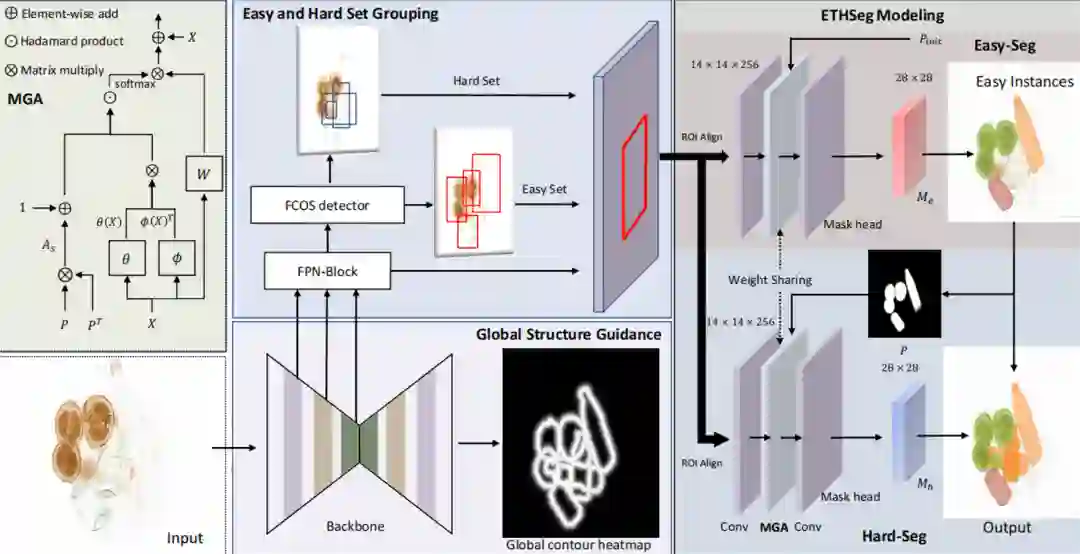
提出了第一个基于 X 光图片的、实例级别的垃圾分割数据集 (WIXRay)。数据集中包含 5,038 张 X 光图片,共 30,845 个垃圾物品实例。对于每个实例,我们标注了高质量的类别、bbox 以及实例级别的分割。
在现有实例分割方法的基础上针对 X 光垃圾图片遮挡严重、有穿透效果的特点进行改进,提出了从易到难的策略,设计了 Easy-to-Hard Instance Segmentation Network (ETHSeg),利用高置信度的预测结果来帮助严重重叠区域的难预测物体的分割。另外,我们还增加了一个全局轮廓模块来更好地利用 X 光下物体的轮廓信息。
Easy-to-Hard 分割网络 (ETHSeg)
推荐:
将 X 光图片用于垃圾分割,港中大(深圳)探索大规模智能垃圾分类。
论文 7:Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?
-
作者:Yi Tay 、 Mostafa Dehghani、 Samira Abnar 等
-
论文地址:https://arxiv.org/pdf/2207.10551.pdf
摘要:
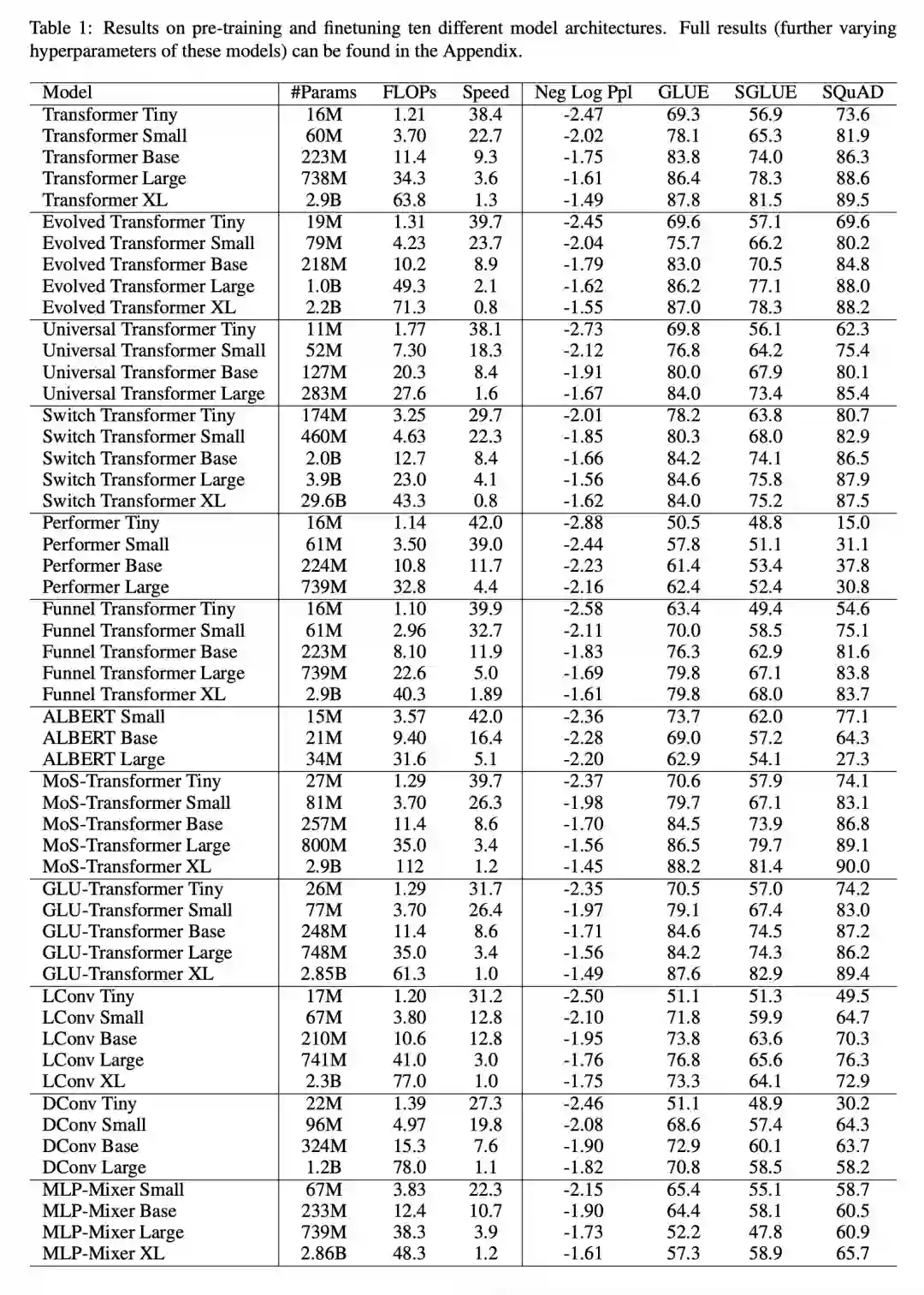
在最近的一篇论文中,谷歌的研究者试图了解归纳偏差 (体系架构) 对语言模型标度律的影响。为此,研究者在多个计算区域和范围内 (从 150 万到 400 亿参数) 预训练和微调了 10 种不同的模型架构。总体来说,他们预训练和微调了 100 多种不同体系架构和大小的不同模型,并提出了在缩放这十种不同体系架构方面的见解和挑战。
他们还注意到,缩放这些模型并不像看起来那么简单,也就是说,缩放的复杂细节与本文中详细研究的体系架构选择交织在一起。例如,Universal Transformers (和 ALBERT)的一个特性是参数共享。因此,与标准的 Transformer 相比,这种体系架构的选择不仅在性能方面,而且在计算指标如 FLOP、速度和参数量方面显著扭曲了缩放行为。
表 1 展示了本文的主要结果,包括可训练参数量、FLOP (单次前向传递)和速度 (每秒步数) 等,此外还包括了验证困惑度 (上游预训练) 和 17 个下游任务的结果。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Recognizing and Extracting Cybersecurtity-relevant Entities from Text. (from Tim Finin)
2. Unravelling Interlanguage Facts via Explainable Machine Learning. (from Fabrizio Sebastiani)
3. Smoothing Entailment Graphs with Language Models. (from Mark Steedman)
4. Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning. (from Yossi Matias, Craig Boutilier)
5. GTrans: Grouping and Fusing Transformer Layers for Neural Machine Translation. (from Jian Yang, Haoyang Huang)
6. Composable Text Control Operations in Latent Space with Ordinary Differential Equations. (from Xiaodong He, Shuguang Cui)
7. Building an Efficiency Pipeline: Commutativity and Cumulativeness of Efficiency Operators for Transformers. (from Jimmy Lin)
8. Improving Distantly Supervised Relation Extraction by Natural Language Inference. (from Qi Li)
9. What Can Transformers Learn In-Context? A Case Study of Simple Function Classes. (from Percy Liang)
10. Efficient Fine-Tuning of Compressed Language Models with Learners. (from James J. Clark)
1. Automatic dense annotation of large-vocabulary sign language videos. (from Andrew Zisserman)
2. TAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation. (from Larry S. Davis)
3. Revisiting the Critical Factors of Augmentation-Invariant Representation Learning. (from Xiangyu Zhang)
4. Explicit Occlusion Reasoning for Multi-person 3D Human Pose Estimation. (from Alan Yuille)
5. Global-Local Self-Distillation for Visual Representation Learning. (from Tinne Tuytelaars)
6. High Dynamic Range and Super-Resolution from Raw Image Bursts. (from Jean Ponce, Julien Mairal)
7. Matching with AffNet based rectifications. (from Jiří Matas)
8. Vision-Centric BEV Perception: A Survey. (from Yu Qiao, Ruigang Yang, Dinesh Manocha)
9. Augmenting Vision Language Pretraining by Learning Codebook with Visual Semantics. (from C.-C. Jay Kuo)
10. Statistical Attention Localization (SAL): Methodology and Application to Object Classification. (from C.-C. Jay Kuo)
1. Flow Annealed Importance Sampling Bootstrap. (from Bernhard Schölkopf)
2. Boosted Off-Policy Learning. (from Thorsten Joachims)
3. Link Prediction on Heterophilic Graphs via Disentangled Representation Learning. (from Charu Aggarwal)
4. A Hybrid Complex-valued Neural Network Framework with Applications to Electroencephalogram (EEG). (from Xiaogang Wang)
5. Bayesian regularization of empirical MDPs. (from Inderjit Dhillon)
6. AdaCat: Adaptive Categorical Discretization for Autoregressive Models. (from Pieter Abbeel)
7. Semi-supervised Learning of Partial Differential Operators and Dynamical Flows. (from Lior Wolf)
8. Robust Graph Neural Networks using Weighted Graph Laplacian. (from Sandeep Kumar)
9. De-biased Representation Learning for Fairness with Unreliable Labels. (from Yang Wang)
10. Understanding the classes better with class-specific and rule-specific feature selection, and redundancy control in a fuzzy rule based framework. (from Nikhil R. Pal)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com