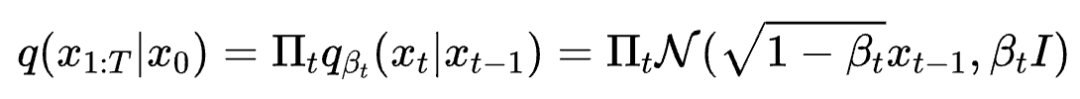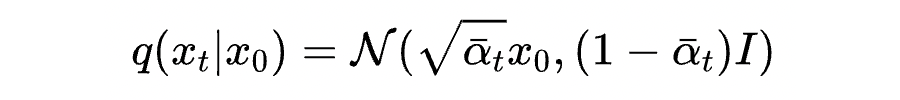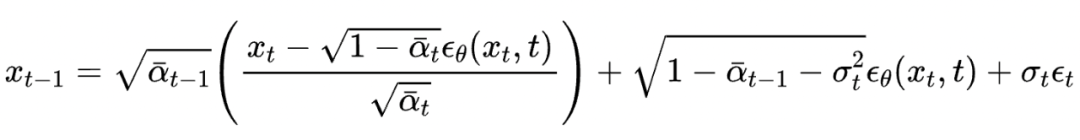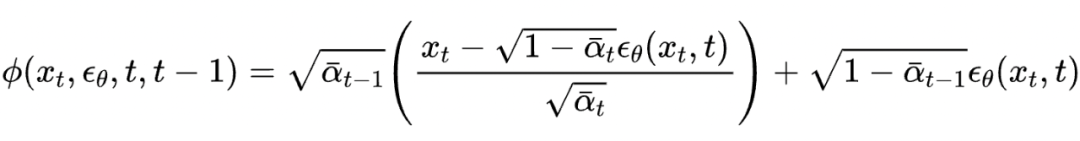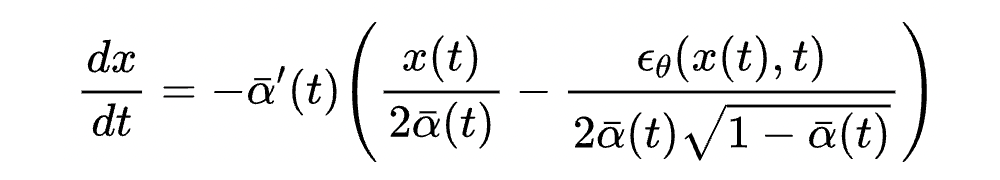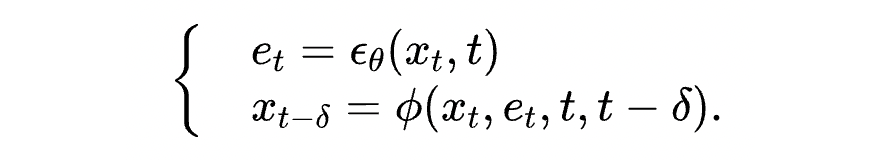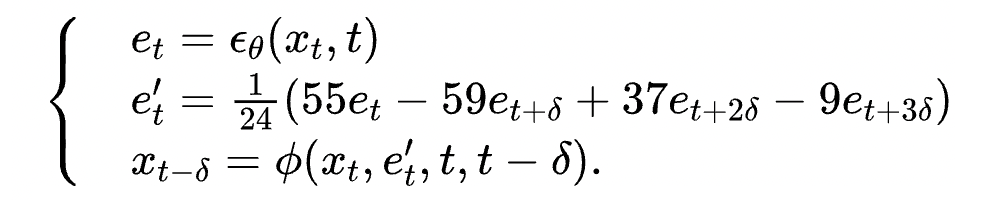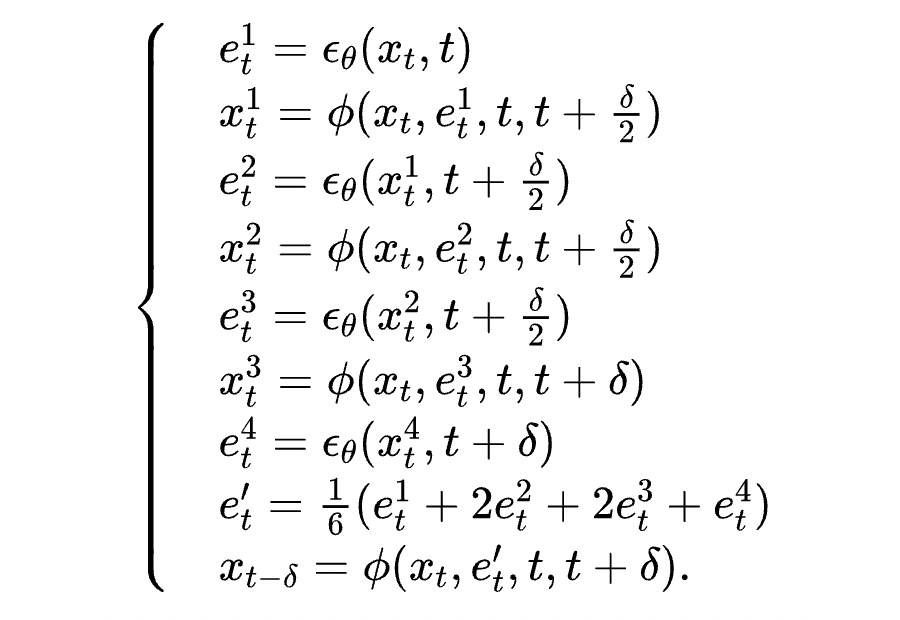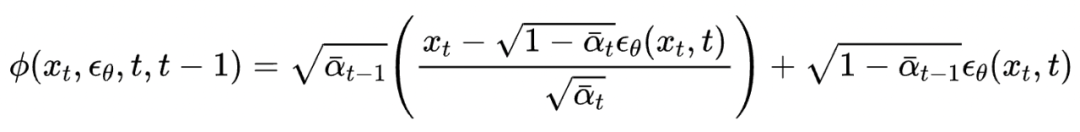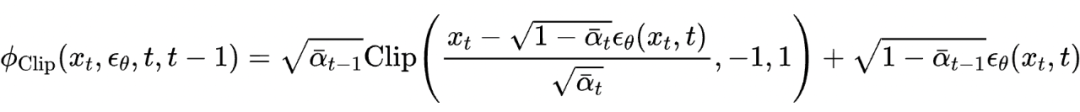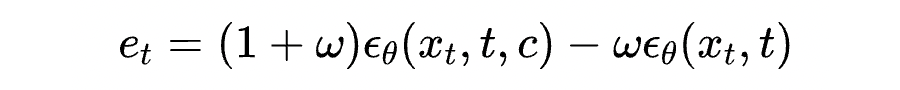这也很大程度上解决了第二个问题,因为不需要整体改变迭代公式,这保证了迭代生成的轨迹和原始 DDIM 迭代公式相似。而 DDIM 的迭代公式恰恰可以保证生成数据和训练数据符合相同的分布。因此迭代过程可以大概率落在训练数据集中的高密度区域,不会跑出原始数据分布。先连续化再离散的策略则破坏了这种一致性,这也是 DDIM 能好于直接套用四阶数值方法的原因。
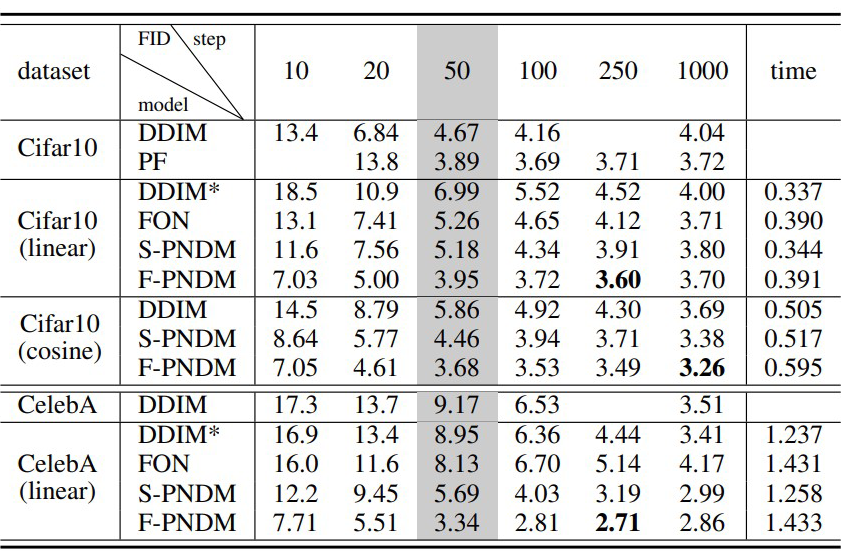
我们的方法融合了 DDIM 和高阶数值方法方法的优点,既保证了拟合分布,也提升了收敛速度。实验结果如下图所示:
这里, 为添加的条件, 控制条件指导的强度。这样简单替换就可将我们的方法用于加速条件生成。由此可以看到,我们的方法和 DDIM 保持了一致,都可以非常方便地进一步对包括 和 在内的中间项进行调整和优化,从而可以被应用到广泛的落地场景中。可以说,我们的类数值方法 PNDM 为扩散模型的落地扫除了计算速度上的重要障碍。目前,PNDM 被 AI 内容生成独角兽公司 Stability AI 的 AI 绘图平台 stable diffusion [2,7] 用作默认加速采样算法,并被包括 AI 开源平台 huggingface 的 diffusers [8] 和浙大语音合成项目 DiffSinger [9] 等多个开源库收录和使用。欢迎大家都来多多关注和使用我们的开源项目。
参考文献
[1] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems 33 (2020): 6840-6851. [2] Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 10684-10695. [3] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising Diffusion Implicit Models. International Conference on Learning Representations. 2021. [4] Zhang Q, Chen Y. Fast Sampling of Diffusion Models with Exponential Integrator. arXiv preprint arXiv:2204.13902, 2022. [5] Saharia C, Chan W, Saxena S, et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv preprint arXiv:2205.11487, 2022. [6] Ho J, Salimans T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022. [7] https://github.com/CompVis/stable-diffusion [8] https://github.com/huggingface/diffusers [9] https://github.com/MoonInTheRiver/DiffSinger