CNN真的需要下采样(上采样)吗?
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:akkaze-郑安坤
https://zhuanlan.zhihu.com/p/94477174
本文已由作者授权,未经允许,不得二次转载
背景介绍
在常见的卷积神经网络中,采样几乎无处不在,以前是max_pooling,现在是strided卷积。
以vgg网络为例,里面使用到了相当多的max_pooling
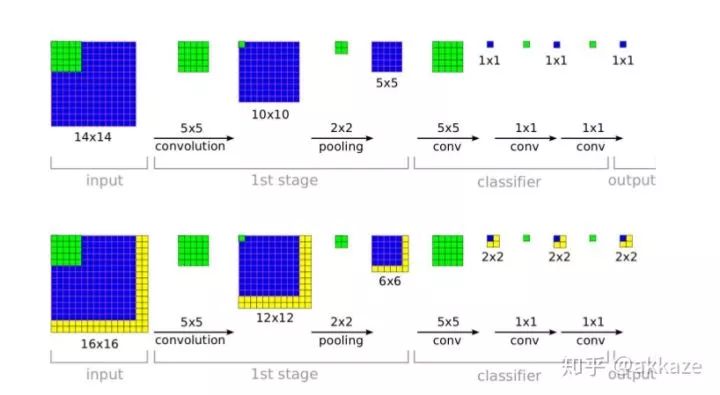
同样,在做语义分割或者目标检测的时候,我们用到了相当多的上采样,或者转置卷积
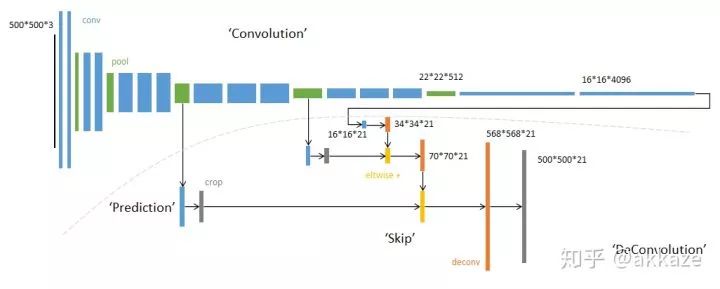
以前,我们在分类网络的最后几层使用fc,后来fc被证明参数量太大泛化性能不好,被global average pooling替代掉了,最早出现在network in network中,
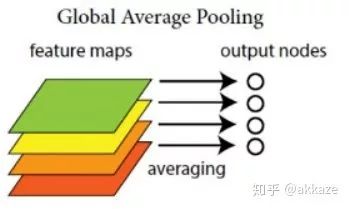
从此,分类网络的范式变为(Relu已经被隐式带在了onv和deconv里面),
Input-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->GAP-->Conv1x1-->Softmax-->Output而分割网络的范式变为(最近的一些文章也在考虑用upsample+conv_1x1代替deconv),
Input-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->Conv-->DownSample_x_2-->Deconv_x_2-->Deconv_x_2-->Deconv_x_2-->Softmax-->Output这里暂时不考虑任何shortcut。
可是,我们不得不去想,下采样,上采样真的是必须的吗?可不可能去掉呢?
空洞卷积和大卷积核的尝试
一个很自然的想法,下采样只是为了减小计算量和增大感受野,如果没有下采样,要成倍增大感受野,只有两个选择,空洞卷积和大卷积核。所以,第一步,在cifar10的分类上,我尝试去掉了下采样,将卷积改为空洞卷积,并且膨胀率分别递增,模型结构如下所示,

这是一个典型的四层的VGG结构,每层卷积的dilation_rate分别为1,2,4,8。在训练了80个epoch后,测试集准确率曲线如下所示 ,
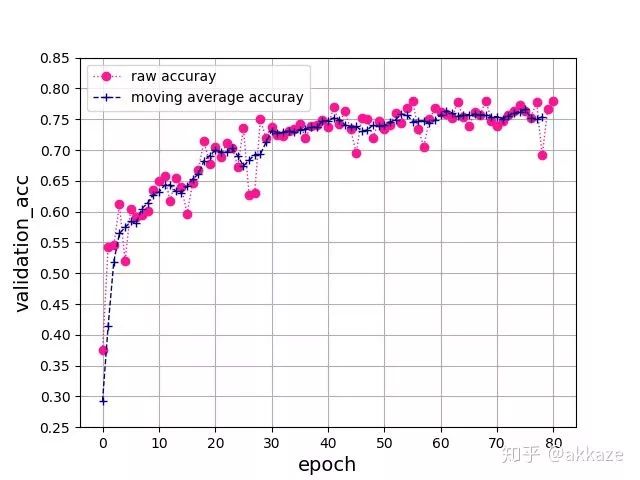
最终的准确率达到了76%,相同参数的vgg结构的卷积网络能够达到的准确率基本就在这附近。
从另一种思路出发,为了扩大卷积的感受野,也可以直接增加卷积的kernel_size,与上面对比,保持dilationrate为1不变,同时逐层增大卷积的kernel_size,分别为3,5,7,9,训练80个epoch后得到如下准确率曲线,
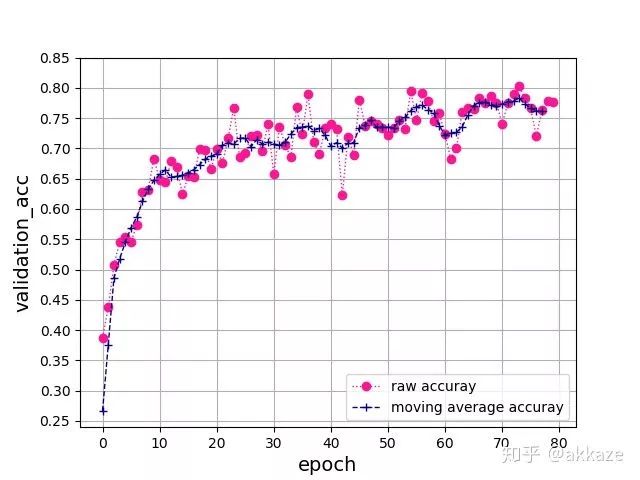
和之前改变dilation_rate的方式比较,收敛过程很一致,略微震荡一点,但是最终的结果很一致,都在76%上下,这说明影响最终精度的因素只有感受野和每层的通道数。
为了说明下采样在性能方面没有提升,用有下采样的网络对对比。即在不修改其他任何参数的情况下,对原本使用dilation的卷积层使用下采样,stride都设置为2,同样训练80个epoch,收敛结果如下,
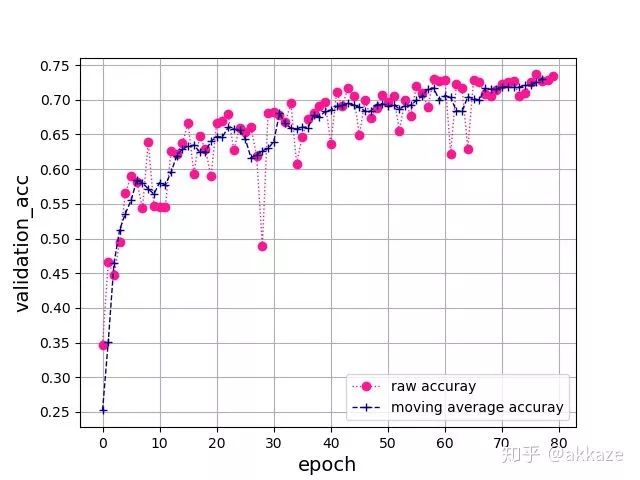
最终收敛到了73%上下,比上面两个实验低了大约3个点,这说明下采样的信息损失确实不利于CNN的学习。
把三种参数的结果放在一起对比,更能够说明问题,
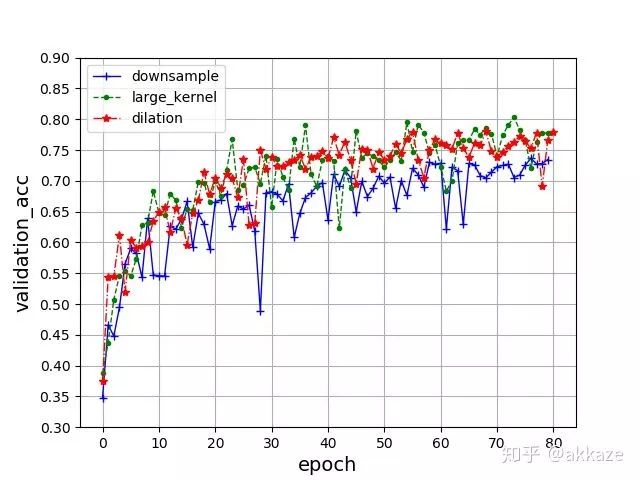
为了验证这种想法的通用性,使用resnet18结构的网络,并在原本需要下采样的卷积层使用dilation_rate不断增大的空洞卷积替代。训练80个epoch后,最终得到的准确率曲线如下 所示,
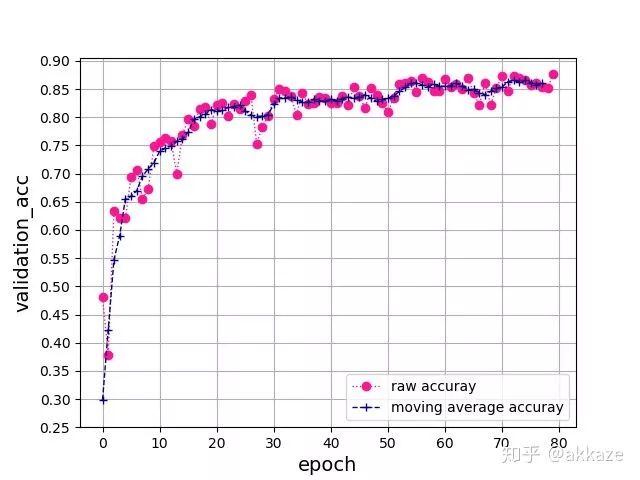
在没有其他任何调参的情况下,最后收敛到了87%的准确率。
小卷积核的尝试
我们知道,大卷积核的感受野通常可以通过叠加多个小卷积核得到,vggnet首先发现5x5卷积可以用两个3x3卷积代替,极大减少了参数量。
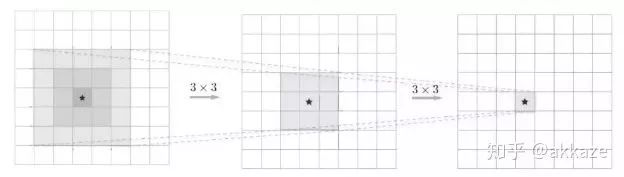
同样的7x7卷积可以用三个3x3卷积级联,9x9可以用四个3x3卷积级联。
为了获得和上面四层卷积网络相同的感受野,我设计了一个十层的只有3x3卷积的网络,每层之间依然有非线性。因为层数多了很多,为了确定中间层的通道数,我做了几组实验。同时,为了不极大增加参数量,我又在卷积中间插入depthwise卷积,这样保持对应感受野上的通道数不变,而参数量不至于增加很多。训练结果,
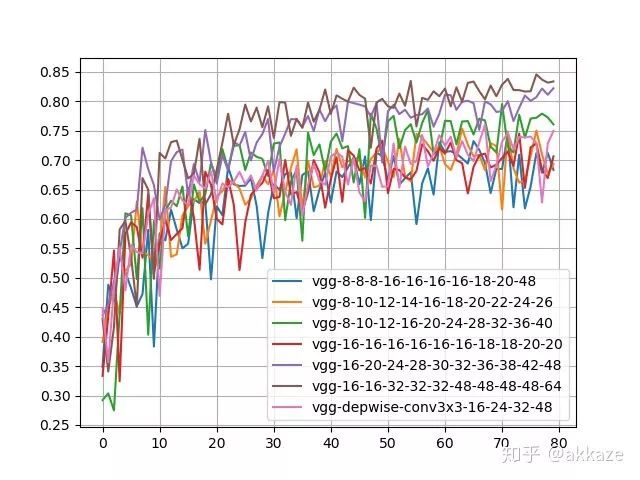
可以看到,只有三个网络结构在精度上优于之前的设计,而这三个网络的参数量都是之前的数倍。使用depthwise卷积的网络参数量并没有增加太多,但是精度还是略低于之前的设计。
为了说明问题,增加每层的通道数,比如之前16-32-48-64的设计,改为64-128-256-512的设计,基本上对于这个深度的网络来说,容量已经接近上界了,结果如下,
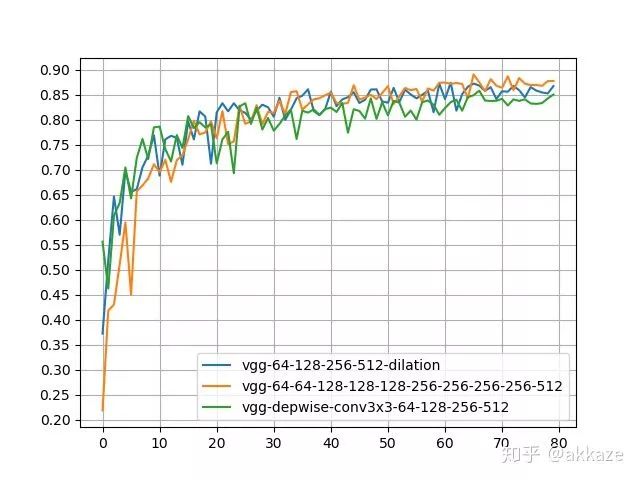
可以看到,空洞卷积网络依然以较小的参数领先于depthwise卷积和3x3卷积混合网络,并以数倍更少的参数优势,在精度上略低于3x3级联网络。
这个实验表明,对于CNN而言,深度之外,感受野以及该感受野上的通道数,真正决定了网络的性能。
这和语音中的wavenet是相似的,
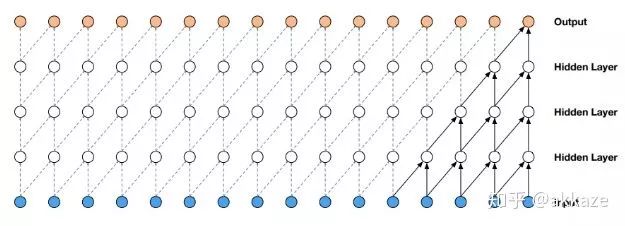
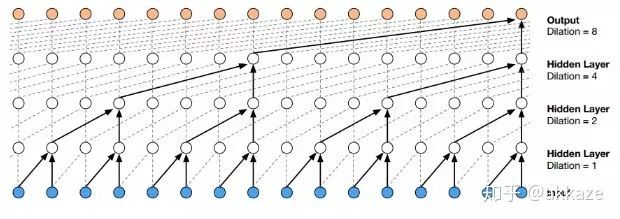
wavenet使用空洞因果卷积来降低计算量,原始wavenet的性能并没有问题,但是计算量和参数量指数增长。
稀疏化方面的思考
小卷积核叠加和大卷积核的方法为了获得和空洞卷积相同的性能,付出了参数上的巨大代价,而空洞卷积本身是稀疏的(大多数元素都是0),这促使我们思考,是否可以用稀疏化解决参数巨大的问题。
CNN的稀疏化最近研究很多,一般的卷积稀疏化见下图,并注意到每层卷积的卷积参数都是四维的,即输入通道数,输出通道数,x方向的卷积尺寸,y方向的卷积尺寸。
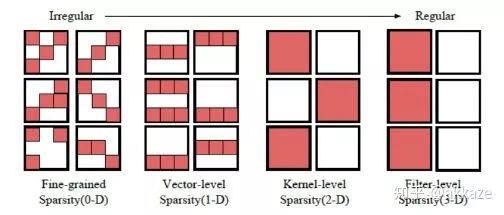
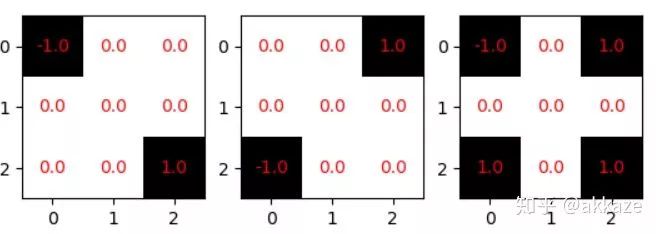
我们常见的其实是通道维度的稀疏化,这相当于减少通道数,也最容易加速,但是更有意义的稀疏化,我认为是卷积核内部的稀疏化,如下图所示,
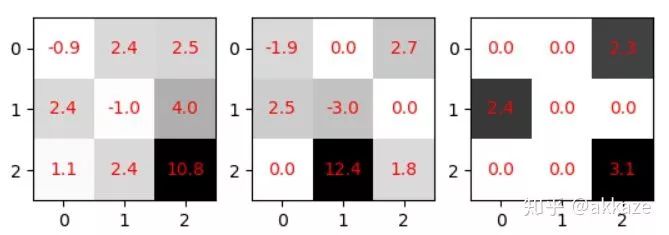
这种稀疏化能减少参数量(因为零值是没有意义的),但是因为不利于工程实现,所以目前没有明显的加速效果。
近期的研究表明,CNN里大多数卷积核都是稀疏的,大约有50%以上都是稀疏的,也就是说有50%以上参数都是冗余的。如果能去掉冗余参数,那么大卷积核和多层小卷积核也能证明在感受野和特定感受野上的通道数对CNN性能的决定性影响,在不增加额外模型参数的前提下。
尽管很容易预测,但是接下来,我们还会证明这两种方法的参数冗余。
10层3x3级联网络的可训练参数量是86404,4层空洞卷积网络参数量是25474,4层大卷积核网络参数量是172930。使用tensorfllow内置的稀疏化功能,其官方github地址为model_optimization,原理即在训练过程中,按一定的准则将卷积核的一些元素置为零,然后finetune。对于10层3x3级联网络,选择稀疏率为25%,这样稀疏化后的参数量为21601,对于大卷积核网络,选择常数稀疏率为15%,稀疏化的参数量为25940,这样稀疏化后它们的参数都比空洞卷积网络更少。为保证网络不会继续收敛了,训练1000个epoch,稀疏化从第200个epoch开始,稀疏化后的训练结果如下所示,
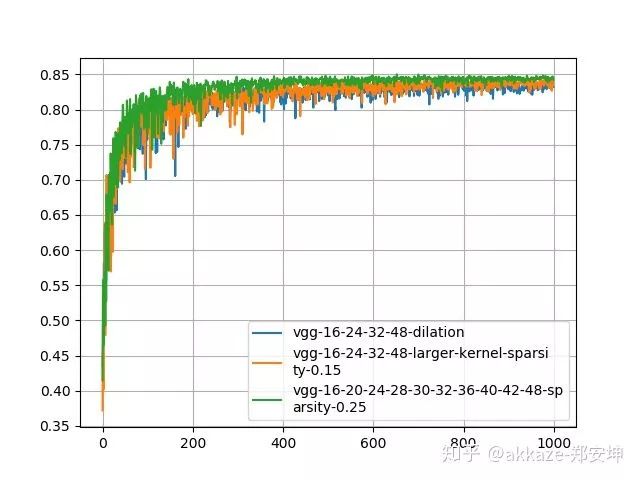
可以明显的看到稀疏化后的3x3级联网络的性能是最好的,同时它的参数也是最少的,同时大卷积核的性能次之,这个时候空洞卷积的性能反而略低。
保持同样的参数和稀疏度,在cifar100上训练的结果如下所示,
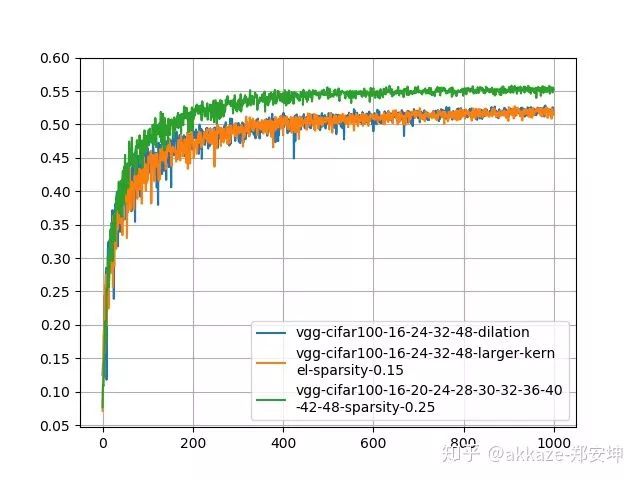
这个时候级联3x3网络的性能已经远超其他两个网络了(对于cifar100上的baseline取多少合适,大家可以参阅一些文章或博客)。
稀疏化极限的思考
我们上面的讨论基本就是,只要能保住某个感受野,稀疏化也是可行的,但是又不禁想知道稀疏化的极限在哪里,对于3x3的卷积核,在保住感受野的情况下,最少必须有两个非零元素,但是这样一来卷积核就退化了,从各向同性退化为各向异性,
学过线性代数的同学都知道,在二维线性空间至少有两个基底向量,才能合成各种方向的梯度。退化成前面两个的情况下,卷积核的二维性质也许就损失掉了,当然如果能级联前面两个,那么在第二层的输出中感受野便又具有了方向性,方向性也许也是感受野的一个重要描述。
maxpooling的额外讨论
这促使我们思考,采样真的是必要的吗?当然,从工程的角度看,采样能极大减小feature map的尺寸,从而大大降低计算量,但这个实验表明,采样对提高cnn的性能并没有帮助,max pooling有抑制噪声的作用,所以有用,但max pooling可以用不下采样的方式实现,这和经典的中值滤波类似。

这也说明,cnn的每一层卷积都在编码空间相关性,浅层特征编码短距离相关性,更深的卷积层编码更远距离的空间相关性,而到了某一层,再也没有统计意义上的空间相关性了(这取决于有意义的物体在图像中的尺寸),到这一层就可以用GAP聚合空间特征了。
分割网络的设计
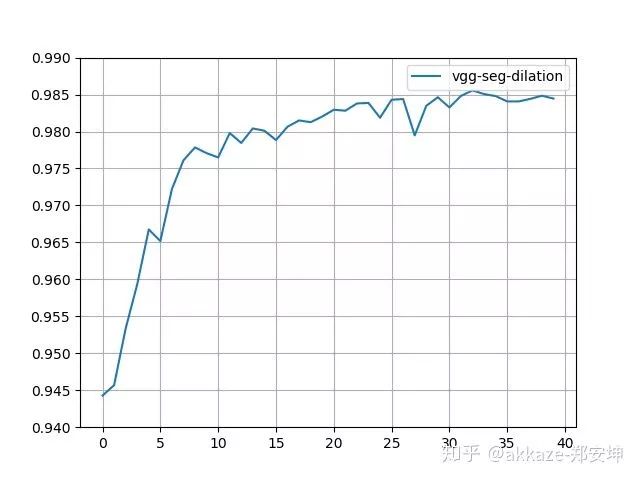
在之前分类网络的基础上,去掉最后面的global average pooling和fully connected,换成conv1x1(相信很多人都知道,fc层形式上可以转换成conv1x1,本以为只是工程上的trick,没想到有本质联系),直接变成分割网络,在我制作的数据集m2nist上,训练结果如下所示,
使用训练好的模型进行预测,可视化后的结果如下:

后续讨论,对网络设计的可能影响
如果没有了采样层,分类网络的范式将如下所示
Input-->Conv(dilate_rate=1)-->Conv(dilate_rate=2)-->Conv(dilate_rate=4)-->Conv(dilate_rate=8)-->GAP-->Conv1x1-->Softmax-->Output分割网络的范式将如下所示,
Input-->Conv(dilate_rate=1)-->Conv(dilate_rate=2)-->Conv(dilate_rate=4)-->Conv(dilate_rate=8)-->Conv(dilate_rate=16)-->Conv(dilate_rate=32)-->Softmax-->Output不再有decoder阶段,因为到了decoder,上采样只是为了恢复分辨率,在无采样的网络结构里,在最大感受野处,即之前加入global average pooling的地方可以直接接softmax进行pixel level的分类,这还需要更多实验。
除此之外,在其他网络中,在网络的任何部分中,都可以使用没有采样的子网络,比如hrnet的旁支网络。
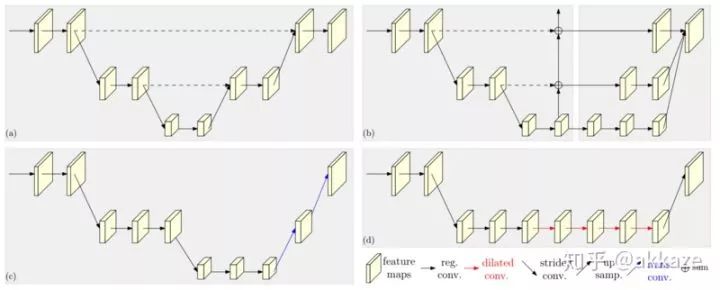
对跨层连接的思考
如果没有了采样,那么所有feature map的分辨率都是一样的,跨层连接也不会再区分bottom-up和up-bottom,所有的跨层连接本质上都是在融合不同感受野的特征(这里待议,bottom-up应该是在融合分辨率,常用在输出侧,up-bottom应该是在融合来自不同感受野的特征,常用在特征提取侧,当没有了分辨率的变换,bottom-up就不再被需要了)。
对目标检测的可能影响
如果没有了分辨率的变化,那么检测完全可以在网络深层的某个感受野处叉开成为三支,分别检测大中小物体,这个思想和tridentnet有类似之处
据我所知,我是第一个提出能够完全用dilated convolution结合global avergage pooling来实现图像分类或者分割的,并注意到这种方法能够带来性能提升。但是请意识到dilated convolution也不是必须,一个更大kernel size的卷积就可以替换它,但这势必会引入更多参数,可能导致过拟合,当然这可以用稀疏化的办法解决,但是稀疏卷积目前不适合工程化,因为效率并不高。
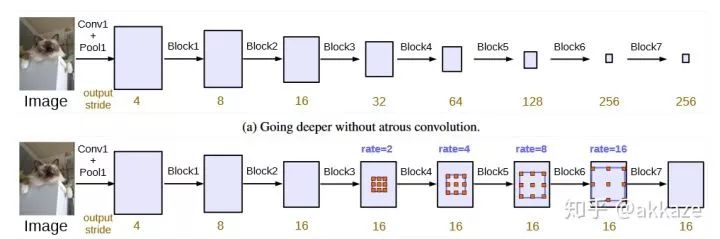
类似的想法最早出现在deeplab的相关论文Rethinking Atrous Convolution for Semantic Image Segmentation中,这篇文章中,空洞卷积主要是通过移除网络最后几层的降采样操作以及对应的滤波器核的上采样操作,来提取更紧凑的特征,并且不增加新的额外学习参数。
总结一下本文。
虽然不利于加速,但是卷积核天生就应该是稀疏的,下采样损失了分辨率,一定会损失精度。深度之外,只有感受野和与之对应的通道数最重要。
数学本质的思考(这部分按需自行忽略,以后打算单独讨论)
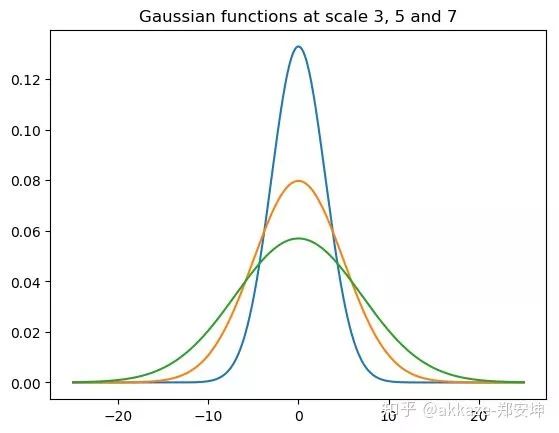
这篇文章的另一个作用,对于数学家分析CNN更加方便,不用再建模下采样,只用证明卷积核稀疏性可以建模图像识别,并且因为没有了采样,卷积也就变成了连续空间上的卷积,(同时,激活函数也是可以软化的),卷积核大小可以用函数支撑空间来描述(类似于高斯核的有效半径)。下图即高斯核函数 

一句话说来,CNN是一种利用卷积实现二维泛函空间到二维泛函空间映射的神经网络。
以一维为例,这就相当于把(-1,1)上的有界函数f映射到有界函数g的一个泛函,

为什么用卷积呢?众所周知,卷积是最简单的这样一个泛函

并且它有着诸多良好的性质,最重要的是,卷积有平移不变性,

它也有缩放不变性,

它有结合率和交换率

所以对于任意一个算子 


但是直接寻找并不容易,那么就用一系列卷积去逼近它,其中

那么,cnn的策略就很明显了,通过拟合的方式,用一组卷积去逼近任意泛函(注意,这个时候缩放不变性被非线性激活破坏了)。
为什么使用小卷积核之狄拉克函数与高斯函数
我们知道狄拉克函数

它 是一个广义函数,也就是说不是普通意义上的函数,当高斯核函数的有效半径无限趋近于0的时候,便得到了狄拉克函数。
它的卷积有如下性质

这可以看成是1x1卷积,
它的n阶导数有如下性质

也就是说和它的n阶导数做卷积便得到了自己的n阶导数。
这个函数在应用中必定是实现不了的,但是让我们来看看高斯函数,它的导数是什么样子,
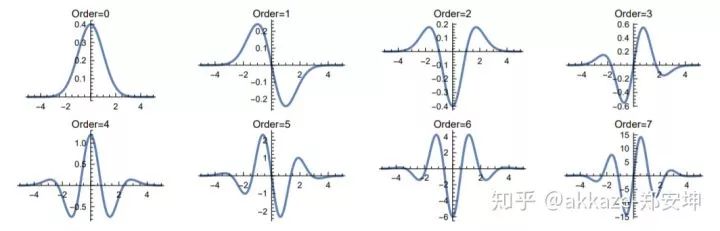
可以看出来这些函数的有效半径惊人的一致。如果使用这些函数,理论上可以使用卷积近似任意微分算子,而微分算子是性质非常好的线性算子。
所以,为什么使用小卷积核,因为只有高斯函数的有效半径趋近于0的时候,它才能近似狄拉克函数,它的导数才能近似于狄拉克函数的导数。
(小卷积核的意义待议,这里提供另一个思考方式,因为图像不是普通函数,卷积在频率空间变成乘法,小卷积核更容易产生高频(类比高斯核函数),所以卷积后更容意放大高频信息,(其实,这和上面的解释并不完全冲突)使得高频信息不容易被非线性的激活函数抹去,而高频信息对于图像来说,有非常重要的作用,比如说边缘,比如说角点)。
稍大卷积核的意义
其实高斯核还有一个性质,与被高斯核作用后(相当于高斯平均)后求n阶导数,相当于与高斯核的n阶导数作卷积,也就是说,

同时,高斯核还有以下性质

所以,我们有高斯核作为基底向量,有

这样求相当与求解一系列线性系数 

那么这样稍大卷积核的意义就是变换在高斯平均后的空间里的微分算子,而且卷积核越大,这个平滑效应越强。
而在图像领域,因为计算机和信息论离散化的表现形式,我们使用采样和量化来处理它,并以此减少计算量
请持续关注本文的源代码github仓库
未完待续,也许是在另一篇文章里。。
CVer 推荐阅读
重磅!CVer-学术交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


