CMU 提出全新 GAN 结构,GAN 自此迈入预训练大军!

文|林锐
众所周知,现在 GAN 的应用是越来越宽泛了,尤其是在 CV 领域。不仅可以调个接口生成新头像图一乐,也可以用 GAN 做数据增强让模型更加健壮。
在CV领域,不像分类、目标检测等任务可以使用预训练好的backbone来加速训练、提升精度,GAN的训练基本上是从头开始!!因为GAN的判别器好坏直接影响生成器的梯度,判别器太好将导致生成器的梯度消失,网络就没法训练了。
本文的作者为了打破这种局限性,今年 CVPR'2022的一篇Oral 引入了叫做 Vision-aided GAN(以下简称VAG)的全新结构,使得 GAN 也能够采用预训练+精调的范式。此外,VAG 只用1%的训练数据就达到了与StyleGAN相匹配的水准,使得训练难度显著降低。
论文题目:
Ensembling Off-the-shelf Models for GAN Training
论文链接:
https://arxiv.org/abs/2112.09130
Github:
https://github.com/nupurkmr9/vision-aided-gan
![]() 背景
背景![]()
 背景
背景首先简要介绍GAN网络的训练模式。

2014年,Goodfellow发明了GAN网络,GAN的训练过程分为:
1.先固定住生成器,接着训练判别器,使这个判别器能够分辨生成的数据和真实的数据。
2.一定step后固定住判别器,接着训练生成器,使生成器生成的图片骗过判别器。一定step后继续此循环,直到达到纳什平衡的状态。
为什么不一开始就用一个预训练的最优判别器呢? 因为判别器太强将导致梯度消失,这也就是为什么GAN网络一般是从头开始训练。

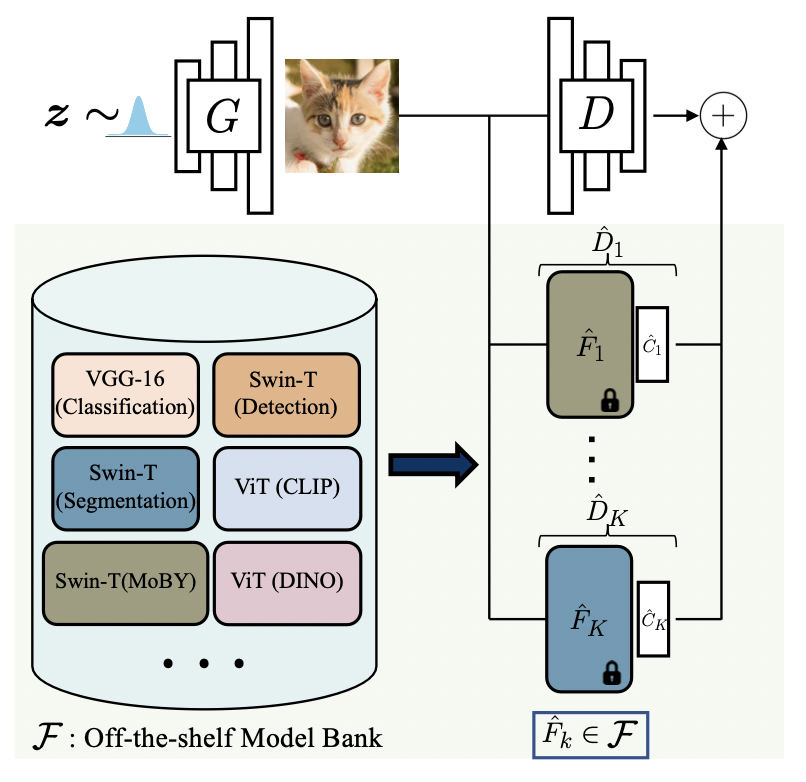
本文的作者提出的 VAG 结构不但克服了GAN网络训练中常见的过拟合的问题,还避免了因判别器过强引发的梯度消失。因此VAG能使用预训练过的大型模型作为判别器来提高训练精度、简化训练过程,可谓神奇。下图为VAG模型结构图。
![]() 实现方法
实现方法![]()
1.训练思路
这张结构图表达的训练思想非常简单,首先搭建好一个的预训练模型库,然后从模型库中取出若干个模型再接上分类头组成的新判别器,再跟初始GAN网络的判别器并联。因此模型的训练Loss就变成了下面的样子。
也就是说并联的判别器会跟原始判别器一起去训练,由于原始的判别器不够强,所以能一定程度上避免梯度消失,又因为新的判别器是用大数据集训练好的模型,其中蕴含的丰富特征也让GAN网络不至于在某个数据集上过拟合。
2.预训练模型选择
细心的同学也能发现,loss中存在一个系数K,这个K是指在总量为N的预训练模型库中选择K个模型加入到训练中来,这个选择也不是乱选的啊,那必须是要有备而来。
作者先做了K=1情况下的GAN训练实验,在模型库中选一个模型,固定住参数,然后接上一个可训练的分类头,去判断传导进网络的图片是真的还是假的。这个二分类的结果称为Linear Probe Accuracy(以下简称LPA),并比较了不同LPA的模型和最终GAN网络训练评价指标FID的相关性,下图为实验结果。
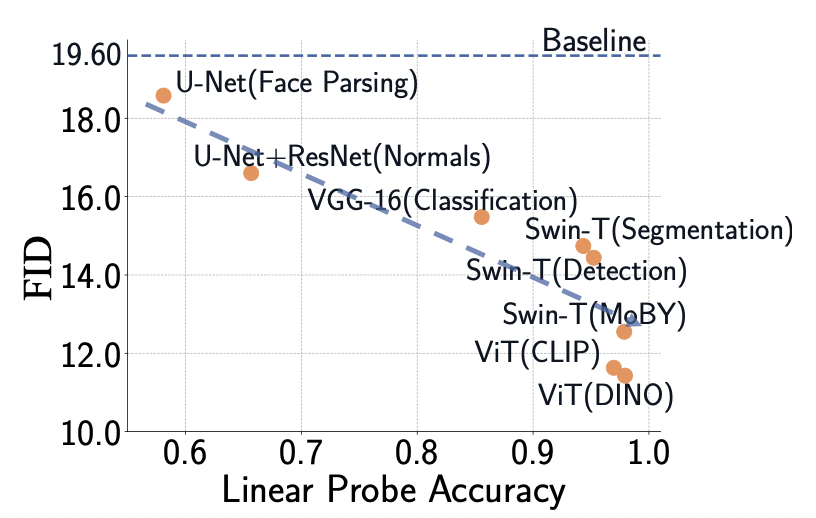
由上图可知,LPA和FID基本上称线性关系,Acc越高,FID也越好。那么当K不等于1的情况下要怎么样把更多的模型加到训练里去呢?作者采用K-progressive model selection策略来逐步添加模型到原始结构里,并在这个基础上达到了SOTA的效果。如何挑选要添加的模型后面实验有进一步解释。
![]() 实验
实验![]()
1.模型有效性
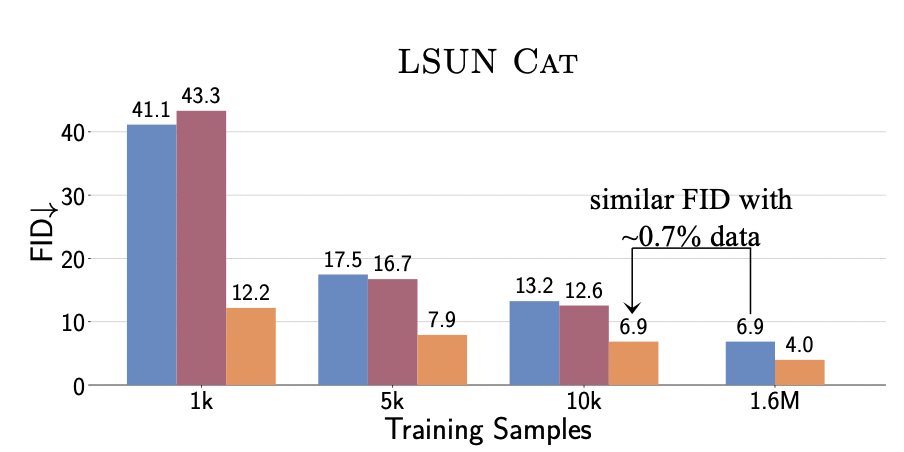
首先下图显式地展现了在GAN网络中引入预训练模型后,只需要用极少量的数据就能达到SOTA的效果,用100%的数据训练实现了新的SOTA。
2.K-progressive Model Selection的有效性
首先从下图中可以看出来,逐步把预训练的模型添加到网络训练中后,GAN的FID在大部分数据集中都能得到显著的提升。说明增加预训练模型的方式是有效的,作者进一步分析了如何去做Model Selection。
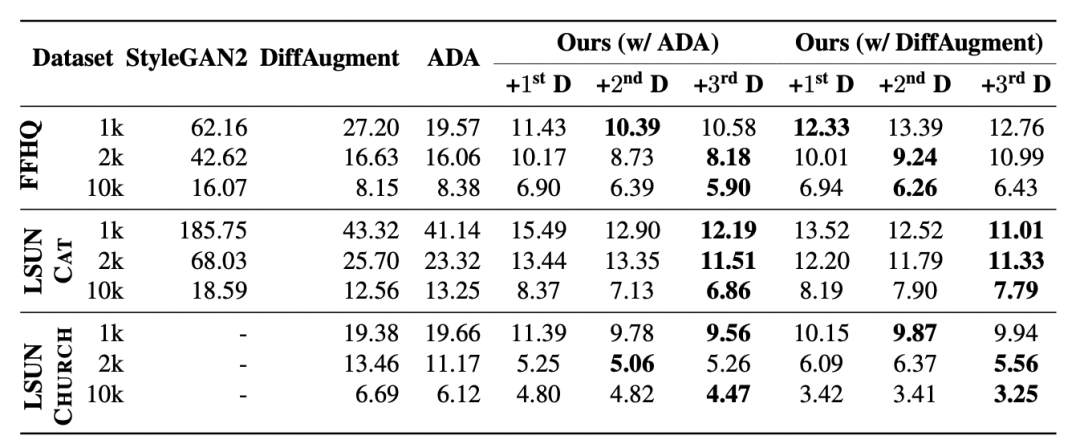
下图展现了3种不同添加model的方式,第一行是逐渐加入在此数据集下LPA最好、次好的模型,第二行是随机选择,第三行是选择最差、次差的模型,很明显逐渐加入最好的那一批模型最终的训练效果最好。

![]() 总结
总结![]()
作者提出了Vision-aided GAN的结构,率先引入了预训练的模型辅助GAN训练并取得了新的SOTA,为之后的GAN网络训练提供了新的范式。
小编认为这篇文章的思路很直观,但是在实验中如何平衡新引入的GAN判别器Loss和原始判别器Loss是一个很难的抉择问题,因为在训练过程中,由于原始判别器Loss始终处于一个主导地位,很有可能模型直接摆烂完全不优化第二部分判别器的Loss,所以能把这种方法做work的才是真正的大佬呀。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【入群】
后台回复关键词【入群】



