一周论文 | 解读2016年最值得读的三篇NLP论文 + 在线Chat实录
本期 PaperWeekly 将继续分享和解读 3 篇 2016 年最值得读的自然语言处理领域 paper,分别是:
1. LightRNN Memory and Computation-Efficient Recurrent Neural Network
2. Text understanding with the attention sum reader network
3. Neural Machine Translation with Reconstruction
➊
LightRNN: Memory and Computation-Efficient Recurrent Neural Networks
论文链接
https://papers.nips.cc/paper/6512-lightrnn-memory-and-computation-efficient-recurrent-neural-networks.pdf
作者
Xiang Li, Tao Qin, Jian Yang, Tie-Yan Liu
单位
Nanjing University of Science and Technology & Microsoft Research Asia
关键词
LightRNN, Word Embedding, Language Model
文章来源
NIPS 2016
问题
在词典规模比较大的情况下,传统 RNN 模型有着模型大训练慢的问题,本文提出的 LightRNN 模型通过采用两个向量组合在一起表示一个词的方法,降低实际训练向量的数目,进而解决上述问题。
模型
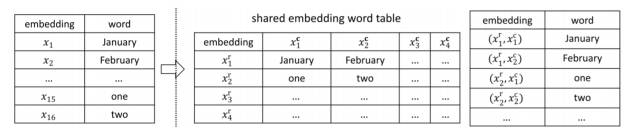
LightRNN 的核心思想是将一个词用两个共享的向量来表示。如下图所示,我们将所有的词分配到下面一个二维词表中,表中第i行所有词语的对应的行向量为 x(i,r),第 j 列词语对应的列向量为 x(j,c)。故第 i 行第 j 列的词语由 x(i,r)和 x(j,c)两部分共同表示,该方法在论文中被称为两部共享嵌入(2-Component shared embedding)。
每一行词语的行向量,每一列词语的列向量均是共享的,因此对于大小为 |V| 的词典,只需要 2√|V| 个不同的向量就可以表示所有词语,这大大缩小了模型的体积,加快模型的训练速度。
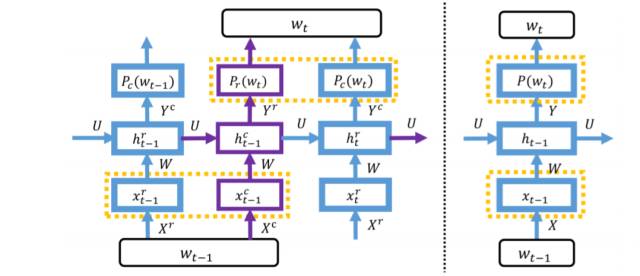
通过上面的介绍我们知晓了可以通过两个向量来表示一个词语,接下来将介绍如何将这种新奇的词表示方法引入到 RNN 模型中。本文的想法其实非常简单,如下图所示,将一个词的行向量和列向量按照顺序分别送入 RNN 中即可。以本文中的语言模型任务为例,为了计算下一个词是 w_t 的概率,我们需要先根据前文计算下一个词的行向量是 w_t 的行向量的概率,再根据前文和 w_t 的行向量计算下一个词的列向量是 w_t 的列向量的概率。行向量概率和列向量概率的乘积便是下一个词是 w_t 的概率。
现在我们已经清楚了这种新颖的词语表示方法以及如何将这种词语表示方法应用到语言模型中。但仍然存在一个关键的问题,即如何生成上图中的二维词表。本文提出了一种 Bootstrap 过程的方法,具体步骤如下:1. 冷启动,随机将词语分配到二维词表中。2. 训练 Embedding 到 LightRNN 收敛为止。 3. 固定上述训练好的 Embedding,再重新分配词语在表中的位置来最小化损失函数。然后回到步骤 2。(该过程可以转化成最小权完美匹配问题,文中采用相关论文中的近似算法来解决该问题。)
通过一些在 ACLW 和 BillionW 数据集上的语言模型实验,可以观察到相比之前的语言模型,LightRNN 在训练速度上有两倍的提升,模型缩小了数十倍,且实验效果还略有提升。
资源
[ACLW]
https://www.dropbox.com/s/m83wwnlz3dw5zhk/large.zip?dl=0
[BillionW]
http://tiny.cc/1billionLM
相关工作
语言模型相关工作
1. Blackout: Speeding up recurrent neural network language models with very large vocabularies
2. Character-aware neural language models
**本文采用的最小权完美匹配问题的近似算法**
Linear time 1/2-approximation algorithm for maximum weighted matching in general graphs
简评
本文提出的 LightRNN 方法大幅度提升了模型的训练速度,缩小了模型的大小,对于苦于模型训练过慢、显存不足的人来说是一大福音。此外,本文提出的模型在一定程度上可以学到词语之间的一些共享信息,进而提升模型的效果。目前本文的方法仅在语言模型上进行了实验,显然此方法同样适合扩展到机器翻译、问答等任务上,期待该模型在其他任务上的应用。
完成人信息
王宝鑫,科大讯飞,destin.bxwang@gmail.com
实录
问:从文中 Figure5 展示的图片来看,每一行的词可以看出存在一些语义或形式方面的共同之处,但是列向量之间很难看出有什么共性体现。那么关于列向量的作用如何理解?这是否跟网络的结构有关系?
答:这个问题很有意思,一开始我看到 Figure5 中的例子时,并没有想太多,很多论文中都有类似的展示,作者一般会把其中效果比较好的,可解释性比较强的部分拿出来给大家展示。所以一开始,我默认作者只是选择性把同一行语义相关性比较强的例子拿出来了,而同一列语义相关性比较强的则没有拿出来。 事实上,本文模型中的行向量和列向量作用确实有所不同,LightRNN 是先通过预测下一个词的行数来确定下一个词的大体范围,再预测下一个词的列数来确定下一个词具体是什么。也正是因为这个先后过程,导致了同一行的词语具有语义上的相似之处(范围相接近)。举个栗子来说,Barack Obama was born on <wt>,对于这个句子,预测下一个词 wt 的时候,模型会首先预测它的行数,这一行中会出现大量的时间类词语,接下来通过前文和行向量,模型再进一步预测 wt 的列数来确定是哪一个时间,August。上面简单解释了下行向量和列向量作用的不同之处,同时也说明了同一行之间语义相似会使模型效果更好。归根结底,真正使行中词语聚类的原因是通过 Bootstrap 过程来对词语重分配导致的,重分配词语来最小化损失函数,会倾向于使同一类词语聚集在一行。
问:除了梯度下降训练 Embedding 参数外,还需要不断地用 MCMF 重分配词语在二维表中的位置。是否有一些其他的策略可以改进或者加快这个训练过程?
答:这主要是因为二维表中的词语采用随机初始化的分配方式,随机分配的如果不合适的话,同一行词语之间彼此毫无语义关联,会使模型在预测下一个词行数的时候就产生较大分歧,导致了第一轮训练困难的情况。因此,第一次分配二维表中的词语时,或许可以提前采用一些手段做些预处理。类似于用预训练的 word embedding 来聚类,把同一类的词分配在同一个行里。或者用一些 Topic Model 把相同主题的词语分配在同一行,都有可能加快训练过程。其他的地方,例如重分配词语位置的方法,以及行列向量的组合方式等都有可能有改进的空间,这些地方我目前还没有太好的想法,大家等下自由交流阶段也可以多提提自己的想法 。
问:在词表很大的情况下,也就是说无法在内存当中存下每个词在词表中的概率的情况下,怎么高效地重分配词表呢,分配词表的算法不取全局最优解对最终的影响估计有多大呢,有没有什么形式化的表示可以说明影响的大小呢 ?
答:实际上我之前也想过这个问题,因为在重分配的过程中,每个词在词表的概率占用的空间还是很大的,是 O(V^2)。不过相对于显存来说,鉴于内存实在是比较便宜,这个问题的影响一般应该不大。内存如果放不下而采用从硬盘读写的方法,应该会极大地降低模型训练速度,反倒得不偿失。而重分配过程中,实际上分配词表的方法一直都不是最优解。首先本文采用的是一个 1/2 近似的 MCMF 算法,并不能达到最优解。其次,本文中的优化目标函数实际上也并不能真正的使模型在固定 Embedding 的情况下,Loss 最小。因为本文一直基于一个假设,便是每次只改动一个词语的位置,计算对应的 Loss。而当所有位置都变化的情况下,前文的表示已经改变,也不能再用之前已经训练好的 RNN 的状态来计算 loss 了。这也是我之前说的,重分配词语位置的方法还可以改进的原因,但对于具体的改进方法,目前我还没有什么好的想法。欢迎大家等一下详细来讨论。
问:这篇文章的做法是将一个词拆分成一个 table 中的行列向量的表示,并分别预测行部份和列部分,那如果我将一个词表示成 table 中行列向量的拼接,一次性地预测和输入,效果会怎样呢,在实验前有没有一些理论上的依据可以评估呢。
答:这是我之前提到的另一个改进的可能了,改进行列向量的组合方式。你提出的这种方法,输出预测部分,将输出的结果分割,然后分别预测行列号。在没有实验之前,很难评价效果是好是坏。但是我个人不是很认可这种处理方式。因为这样缺少了一步我觉得比较关键的过程,即通过前文和行来预测列。行列交替预测有两个优点,一个是缩小搜索空间。另一方面是可以通过词语重分配使相近词语处于同一行,增强 rare word 的表示能力。
问:行列组合生成 word embedding 的做法是否可以扩展为更高维,例如 3 维(行、列、层)的 Embedding Component 组合?感觉可以进一步压缩 Embedding 体积。
答:本文作者虽然也提到了这种可能性,即用 3 维的组合。但是我个人也不看好这种方法。实际上,我最近也在尝试用二维的组合方式来训练语言模型,模型非常难以收敛,只有一个好的词表分配方法才能使模型达到比较好的效果,而我们采用三维的组合方式,减少了模型的复杂度,会让模型更加难以训练。应该说,减少了模型的参数,很难说现实中有一种很好地词表组合方式,使模型训练的很好。
➋
Text understanding with the attention sum reader network
论文链接
https://arxiv.org/abs/1603.01547
作者
Rudolf Kadlec, Martin Schmid, Ondrej Bajgar, Jan Kleindienst
单位
IBM Watson
关键词
Machine Reading Comprehension
文章来源
ACL2016
问题
针对 context—question-answer 数据集,使用注意力机制直接在原文本上获取问题的答案。网络结构简单, 计算量小,并取得 state of the art 的结果。
模型
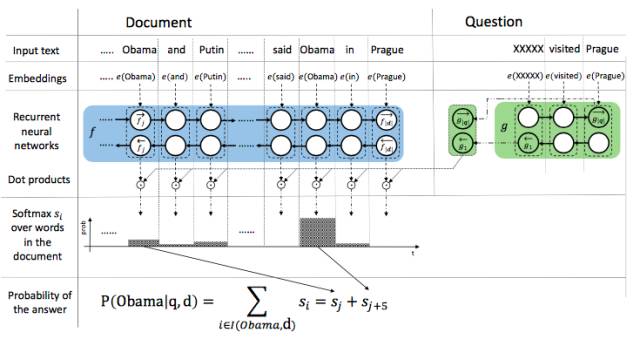
Attention sum reader network 的核心思想是通过注意力机制的权重计算出哪个词为答案词汇。如上图所示,在使用 embedding 将文本和 query 中的词分别映射成向量之后,使用单层的双向 GRU 将文本中的词编码,每个 time step 两个方向编码的拼接来代表当前 time step 的词的向量。使用另一个单层双向 GRU 对 query 进行编码,两个方向最后一步输出拼接为 query 的编码向量。
将每一个词的向量表示与 query 的向量点积,之后归一化得到的结果作为每一个词的注意力权重,同时将相同词的权重合并。最后每个词的权重即为答案是这个词的概率,最大概率的词就是答案。在实际计算过程中,只选择了候选答案中的词进行计算,因此减少了计算量。
从结果上来看,论文发表时模型在 CNN/Daily Mail 和 CBT 的数据集上取得了 SOTA 的结果。
资源
[CBT dataset]
http://www.thespermwhale.com/jaseweston/babi/CBTest.tgz
[AS Reader implementation]
https://github.com/rkadlec/asreader
相关工作
Attentive and Impatient Reader
1. Teaching machines to read and comprehend
2. A Thorough Examination of the CNN / Daily Mail Reading Com- prehension Task
Memory Networks
The goldilocks principle: Reading children’s books with explicit memory representations
Dynamic Entity Representation
Dynamic Entity Representation with Max-pooling Im-proves Machine Reading
Pointer Networks
Pointer Networks
简评
1. 本文的模型相比于 Attentive Reader 和 Impatient Reader 更加简单,没有那么多繁琐的 attention 求解过程,只是用了点乘来作为 weights,却得到了比 Attentive Reader 更好的结果,从这里我们看得出,并不是模型越复杂,计算过程越繁琐就效果一定越好,更多的时候可能是简单的东西会有更好的效果。
2. 文中直接利用 attention 机制选择答案,模型就比较偏爱出现次数多的词,这就隐含了出现次数比较多的词作为答案的可能性大的假设,所以从根本上本文是基于 task 的研究而不是从理论出发的。
简评摘录于西土城的搬砖日常的[知乎文章](https://zhuanlan.zhihu.com/p/23462480#!),这篇文章上还有详细的本论文相关模型的分析,推荐大家读一下。
完成人信息
李宸宇 chenyu.li@duke.edu
实录
问:文章的答案都是从文本中找,那如果答案是一句话呢,或者说是我们常见到的从四个句子里选一个,那么效果是否会怎么样,如果说从在模型后边接一个生成模型,就是文中的模型选出关键字,然后利用这些关键字来生成一个句子,会不会更好一些?
答:你说的很对,这篇文章所做的任务就是给答案的一部分然后从里面扣掉一个词 模型的目的是从原文中找出这个词,答案是一句话的这篇文章没有涉及,你说的先预测关键字再生成句子可能效果会不错 就是可能要分两步训练模型 一个用来预测关键字 一个用关键字生成句子,在生成句子的时候也可以将文章的信息和问题的信息通过特征向量引入模型 具体模型怎样设计 实验效果如何还是要做实验才可以知道。
问:模型介绍有一点和论文的描述有出入我帮忙强调下,对 document 的 embedding 和对 query 的 embedding 是不同的,对 document 每个 word 都 embed 成 vector,而 query 整体 embed 成一个 vector 相应的后续的 concat 两者也会有些差异。
答:可能我在写 note 的时候没有写清楚 所有的句子都是要先把每一个单词 embed 到 vector,再用 gru 进行 encode(编码),然后对于文本中的单词,双向 gru 在当前词输出拼在一起成为这一个词的新的向量表示,对于问题直接用双向 gru 最后的输出拼接作为问题的向量表示,最后用这两组向量进行接下来的运算,这是这篇文章的做法。
问:关键字生成模型——这个很难吧,context 缺乏啊:用文档 D 做 context 还是 Query 改写呢?
答:我的想法是可以采用原来语料库里面的数据 自己构建一个关键字字库,训练一个模型使用真正的关键字生成句子,然后将两个模型拼接在一起,然后根据原来语料库+答案关键字 生成答案句子?
问:我现在在做机器人,对 Q&A 感兴趣。“Attention sum reader network 的核心思想是通过注意力机制的权重计算出哪个词为答案词汇。”这句话能再解释下吗?我是个初学者,不太明白。
答:因为 attention 一开始的时候是先用一套机制算出每一个词向量的权重,然后用权重乘词向量的和作为最后的文本表示 在这里只需要算出每个词的权重 把相同词的权重加在一起 得到权重最高的词就是答案。
➌
Neural Machine Translation with Reconstruction
论文链接:
https://arxiv.org/pdf/1611.01874v2.pdf
作者
Zhaopeng Tu, Yang Liu, Lifeng Shang, Xiaohua Liu, Hang Li
单位
Noah's Ark Lab, Huawei Technologies; Tsinghua University
关键词
NMT, autoencoder, reconstructor, reranking
文章来源
AAAI 2017
问题
在传统 attention-based NMT model 上增加一个 reconstructor 模块,用 auto-encoder 的思路,使得 source sentence 翻译之后的 translation 能够重建出 source sentence,改善翻译不充分的问题(over-translation/under-translation)。
模型
现有的 NMT 模型容易出现重复翻译以及部分词语未翻译的情况,因此翻译不够充分;同时在做 decoding 的时候根据 likelihood 去搜索最好的翻译句子并不是一个很好的方法,实验表明 likelihood 倾向于短的句子,在 beam search 时如果把 beam size 不断变大,那么 search 出来最后选择的句子会很短,bleu 就会很差。为了改善上面的两个问题,这篇文章提出用一种 autoencoder 的思路,希望用 decoder 的 hidden 尽可能地重建出 source 的词语,那么 decoder 所 embed 的信息就是相对丰富的,也能得到更好的翻译。其实就是给 NMT 一个更强的约束,而这个约束也非常合理,和 semi-supervised learning for NMT 出发点非常类似。
模型非常简单,直接上图,增加的 reconstructor 模块和 decoder 长的一样:
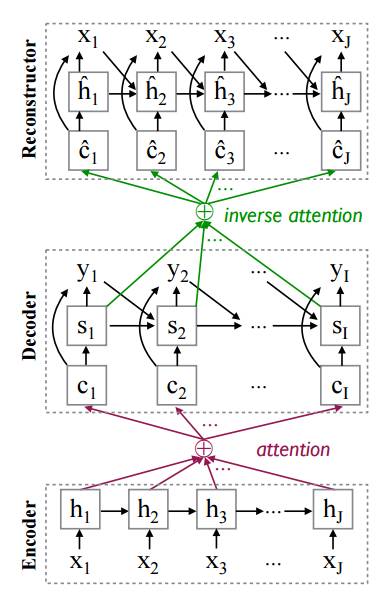
其中 x 的 embedding 和 encoder 中的 embedding 是共享的,而 hidden 是 reconstructor 中单独的参数,inverse attention 的做法也是和原来的 attention 做法是一样。那么整个模型的 training 目标就是:
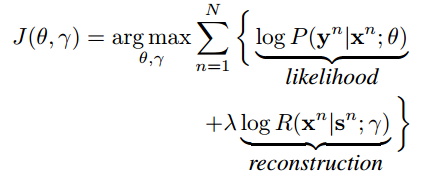
在做 testing 的时候,也是用这个目标,不同的是:先通过 beam search 根据 likelihood P 得到一些 candidate,然后用 reconstructor 去算每个 candidate 对应的 reconstruction score R,根据 P+\lambda R 去选择最终的 translation,相当于是做一个 reranking。流程如下:
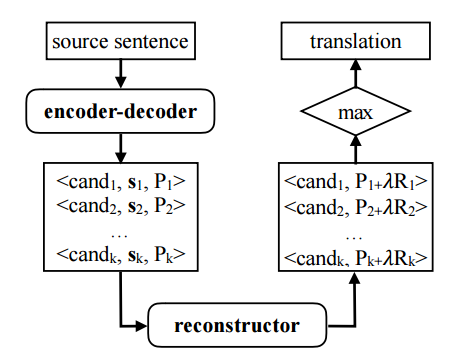
实验只在 zh-en 的数据集上验证,不过有很多 analyze 的实验,同时 encoder-decoder 的参数是通过 RNNSearch 模型 warm start 的。
资源
训练集:1.25M LDC的zh-en数据集;
验证集:NIST2002;
测试集:NIST2005, NIST2006, NIST2008
实验结果
做了很多分析的实验:
1. 先是让人打分,看 reconstruction score 和 adequacy 还是 fluency 相关性更大,人觉得是 adequacy 更相关。
2. 然后是在 training 的时候观察验证集上的 bleu 和 reconstruct 的 source sentence 的 bleu(x, x')的bleu 的变化,然后发现 110k iteration 的时候是这两个值是 balance 最好的。
3. 之后是在不同 beam size 的时候,加上 reconstruction 之后验证集上的 bleu 和 translation 的长度都变好了。
4. 接着是在测试集上的 bleu 变化,高了 2 个点以上。
5. 然后在 testing 的时候加上 reconstruction 比不加又高 1 个点。
6. 在长句子上的表现更好,bleu 更高。
另外还说虽然模型变复杂了,但是速度没有变的特别慢,还有一个是和作者之前自己提出的 context gate,model coverage 比较,都比它们好,以及其他一些涉及人工观察的实验。
相关工作
1. Modeling coverage for NMT
2. Context gates for NMT
3. Semi-supervised learning for NMT
简评
本文用(supervised)autoencoder 的思路,在原有的 NMT 模型上构建了一个 reconstructor,使得 x 翻译得到 y 之后,这个 y 也能通过 reconstructor 重建回 x,这样一来就说明模型中 encoder 和 decoder 的 hidden 所包含的信息是相对充分的,能够改善翻译不充分(重复翻译和翻译不足)的问题。思路非常的清晰简单,模型也不复杂,实验非常丰富,分析了很多的点来说明这个模型表现的很好。值得学习这种清晰的思路和简单的模型构建。
完成人信息
吴郦军 中山大学
实录
问:为什么 beam search size 越大,效果越差?
答:这个问题是这样,一方面 LL 的目标函数本身倾向于更短的句子;另一方面当 beam size 变大的时候,这个问题就会凸显的更加严重。我们来看下,当 beam size 变大时,其实是可能产生很多短的 candidate 的,而这些短的 candidate 的概率就会变得相对较大,因为句子的概率是连乘 `(P(y_1...t)=p(y_1)p(y_2|y_1)...p(y_t|y_<t))` 的形式,所以短的句子很可能概率更大,这也就是第一点 LL 的问题;那么,当 beam size 比较小的时候,decoding 的每一步都会去选择概率最大的 k 个词语,所以那些短的句子基本上也就不会出现了。
问:Model 是 warm start 的,那如果不是 warm start 效果会如何?另外 reconstructor 是 cold start 的,这个是不是不好?
答:准确的说,现在很多 nmt 的工作都是 warm start 开始的,因为可能存在不是 warm start 模型可能无法收敛, 学不出来等的情况或者是为了加快学习速率,比如用预先训练好的 language model 的 embedding,再比如 rl 的方法不 warm start 就会导致搜索空间太大而无法学到等。所以 warm start 还是很重要的而且很通用。在这个工作中,如果不 warm start 似乎没有看出特别大的问题,所以这个还是需要实验来证明好不好;另外对于 reconstructor,的确可以先将地下的 encoder 和 decoder 固定住,先 pre-train 上层的 constructor,然后再 joint 的 supervised training,这样也是可以的。不过同样好不好还是得看试验结果,这里可能只是学习速率上的区别。这点因为没有做实验,也不好说。只是个人猜测。
问:为什么 beam size 变大,就会产生更多较短的 candidates?
答:decoding 的做法是根据每一步来选概率最大的,开始的时候,概率低的那些词语基本上是不会出现在 beam 的 pool 里面的。而当 size 变大时,这些词语就被 cover 在 beam 的 pool 里面了,而如果他们比较早的就到了 eos 的话,整个句子的概率就会相对较大,也就很有可能选择了这样不好的答案。这点应该是和 LL 这个目标是相吻合的,所以也就是倾向于更短的句子这个意思。
问:Lambda 这个参数是 1 是如何确定的?
答:这点其实我觉得是本文可能一个不太严谨的地方,个人觉得应该得试下不同的 lambda,然后给出一个不同 lambda 对于这个问题的结果的影响。我觉得作者应该是尝试了不同的 lambda,然后发现 1 是最好的,所以才这样 report 的。不过也很好奇其他 lambda 的结果,夸张一点说,如果 lambda 大于 1 又会如何呢?其实在一些不同的任务上,lambda 一般是一个 trade-off 的作用,一般应该是 lambda*x + (1-lambda)*y 这样,不过这里不一定是 trade-off,所以就暂且当做同样实验表明 lambda=1 是效果最好的吧。
问: NMT 是如何学习到词与词之间的映射关系?为什么 NMT 能够工作?
答:这个问题。不知道这里提到的词到词的映射是否指的是我理解的 x 中的词要和 y 中的词语一一对应?如果是的话,其实 nmt 本身就没有这个要求,而是强大的 seq2seq 框架,整个 seq2seq 就相当于是两个 language model 的组合(encoder,decoder),那 language model 本身就是可以产生像样的句子。这应该是回到了第二点 nmt 为何 work。那么再看本文,其实这就是一个 autoencoder 的框架,我们如果不看 y 作为单独的词语,而只看 hidden h 的话,那么整体上就是一个 autoencoder。本身其实也不是学习一个词到词的映射,而只是两个 Loglikelihood 的目标。我们从 intuition 的角度理解,他就是希望翻译出来的 y 也能更好的翻译回 x,如果 y 能够翻译回 x,那么整体所包含的语义就是比较丰富的,应该也能表明 encoder 和 decoder 中的 hidden 都有更丰富的信息。这也是这个工作效果为何的确好。
问:Reconstructor 是从翻译过的 y 重新 decoder 回 y,因为 y 有可能翻译的不好,可以理解为 noise,所以像 Denoised Autoencoder —— 如果是这样,是否可以用 DAE 那一套:deep DAE? deep DEA 后是否效果更好 —— 但是这里不是学习,只是验证前面的 seq-to-seq 的效果,所以可以 single layer 就够了。
答:关于 DAE 我没有关注过,所以不是很好回答。但是这篇文章是一个 supervised 训练过程,所以其实不是 sample 或者说翻译出来的 y 来做 reconstructor 的训练,而是用 pair 的 label data y 来做训练的,因此 y 并没有 noise 的这个说法。
本文由机器之心转自PaperWeekly,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




