【动态】 “人工智能安全与隐私”系列论坛第11期圆满落幕
3月3日,由中国图象图形学学会、深圳市大数据研究院主办,腾讯研究院、腾讯AI lab承办,香港中文大学(深圳)数据科学学院、IEEE Guangzhou Section Biometrics Council Chapter协办的“人工智能安全与隐私”系列论坛第十一期圆满落下帷幕。此次报告由香港中文大学(深圳)数据科学学院副教授吴保元主持,清华大学的崔鹏副教授作为主讲嘉宾,围绕基于稳定学习在因果推断和机器学习之间的关系展开了详细的讨论。此外,腾讯高级研究员卞亚涛博士、吴秉哲博士、王焕超研究员分享了腾讯在可信AI和科技向善的探索和最新研究成果。最后,中国人民大学未来法治研究院执行院长张吉豫教授、腾讯AI Lab AI医疗首席科学家姚建华博士、腾讯研究院高级研究员曹建峰博士就“可信AI与可解释AI的技术探索与法律保障”的话题开展了圆桌讨论。
直播录像请见:

本次论坛采用哔哩哔哩线上直播以及腾讯研究院视频号直播形式,吴保元教授回顾了论坛的创建历程,并对论坛举办过程中得到的众多组织、专家的支持表示了诚挚的感谢。在吴保元教授的主持下,"人工智能安全与隐私"系列论坛第十一期于3月3日上午10:00正式拉开帷幕。
讲座内容
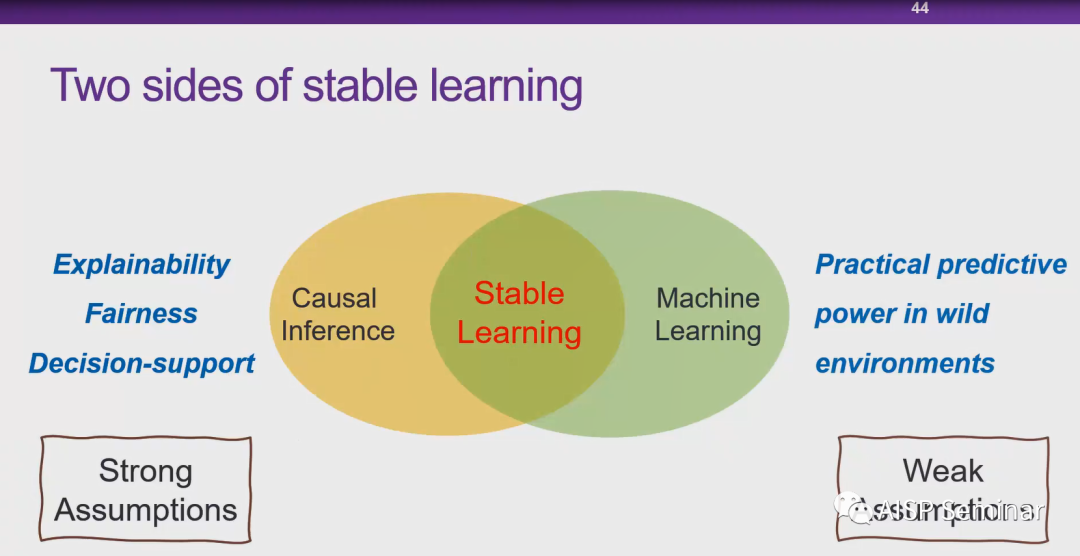
从现在往后看AI的发展,一个很大的趋势就是AI会越来越多的和我们这些很这个严肃的一些应用领域来去做这个渗透和应用。这个里边就包括像医疗项司法向金融等等,那么这些领域,实际上我们统称他们为risk sensitive area即对于风险很敏感可能关乎生命安全,也可能关乎司法正义。这就要求,我们对于AI的技术可能要从单纯的去优化性能,转移到对于风险更加敏感的一种研究范式。












问答环节
Q
Reweighting的结果很好,为什么能做到这样的效果,可否进行详细解释?
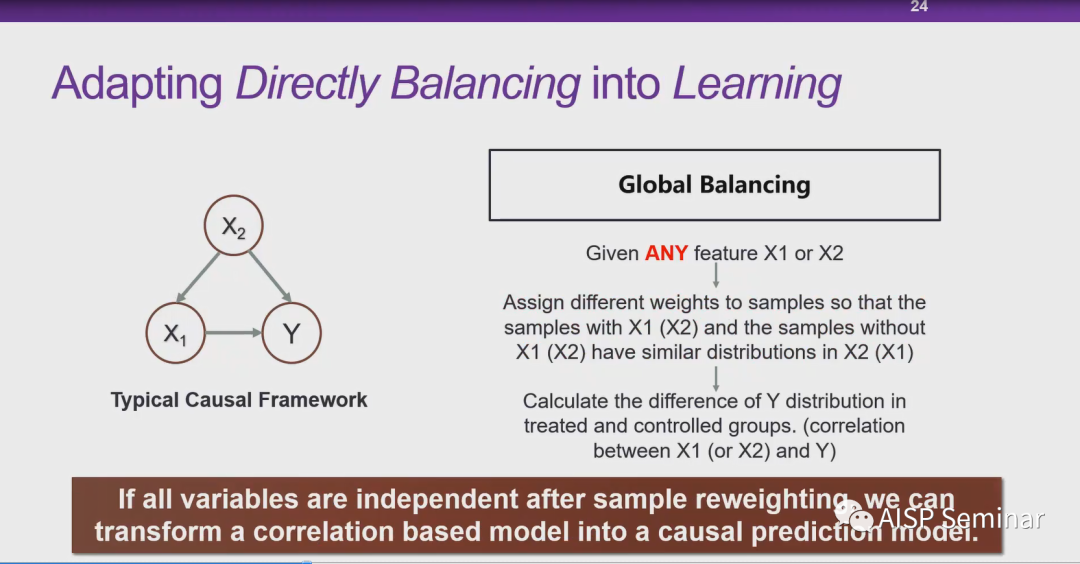
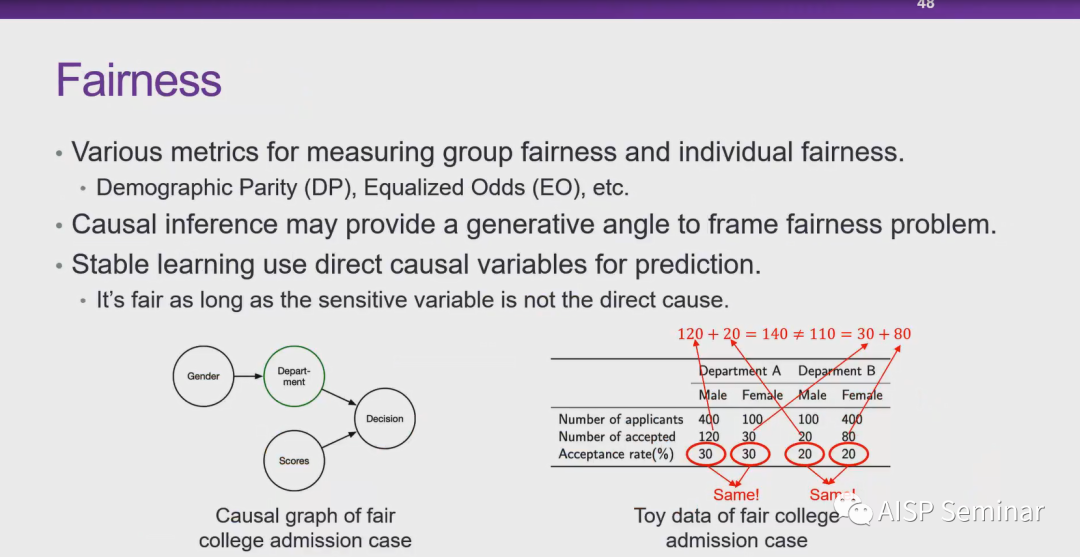
崔鹏教授:样本权重本身一开始一个技巧,本质的区别就是对数据分布做干预,机器学习比较关注IID的情况。我们就可以类比于A-B test。所以我们想在全局上通过reweight使得跟因果更加契合。
成果汇报
之后由腾讯AI lab高级研究员卞亚涛主持,腾讯AI lab高级研究员吴秉哲研究员,腾讯研究院王焕超研究员作为分享嘉宾,介绍了腾讯可信AI取得的相关研究成果。
01
可信AI:
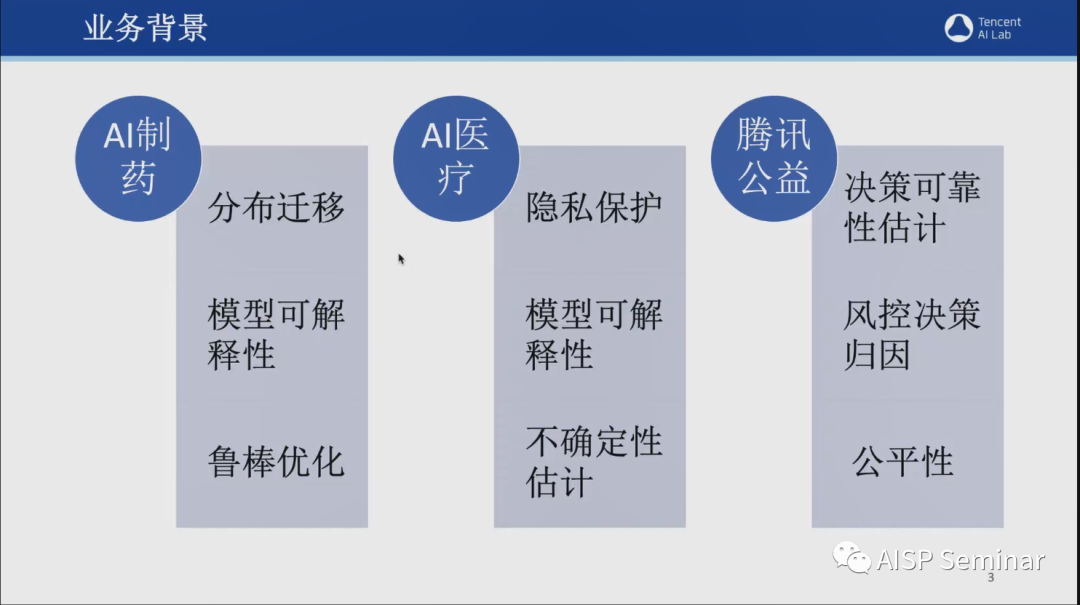
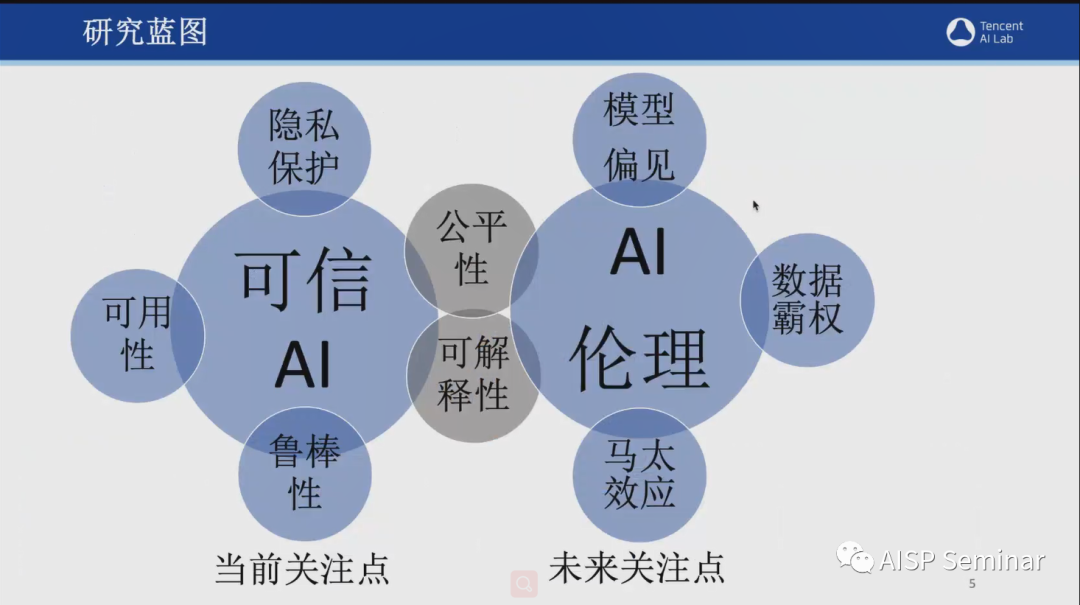
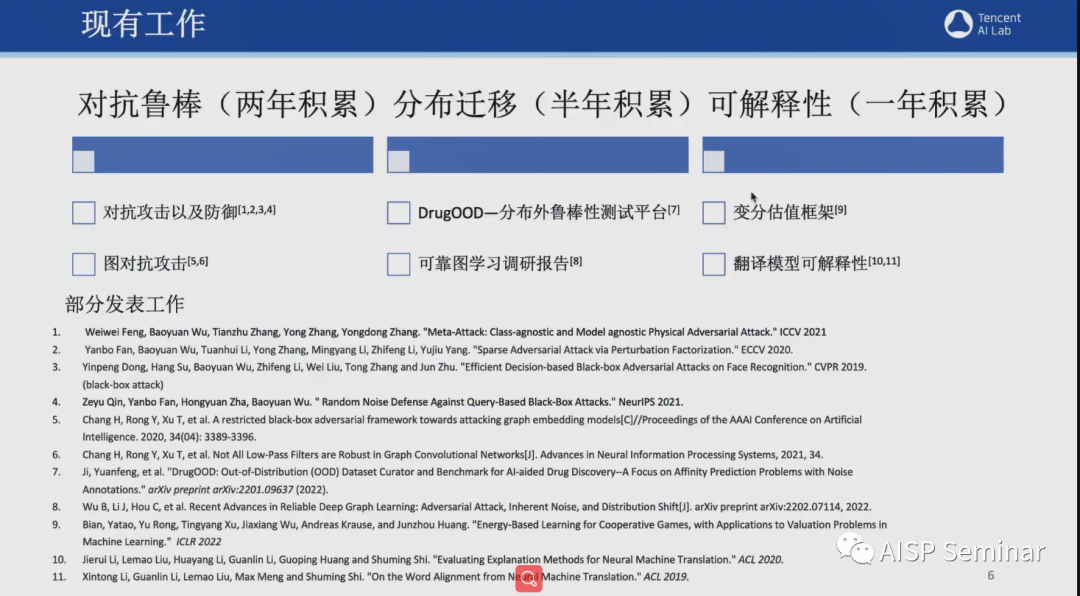
腾讯可信AI团队成立于2021年7月,在对抗鲁棒性、分布迁移以及可解释性等领域有着丰硕的研究成果,并且在国际知名会议和期刊上,发表多篇论文,例如ICCV、CVPR、NeurIPS、ECCV、ACL等。2021年9月,该团队发布了业内首份AI安全白皮书。这份白皮书详细罗列了现在实际业务场景中可能面临的AI安全风险,涵盖了人脸识别、图像分类、物体检测,多模态学习等多个领域。此外,该团队也正在针对这些AI安全风险开展了一系列防御技术的研究。
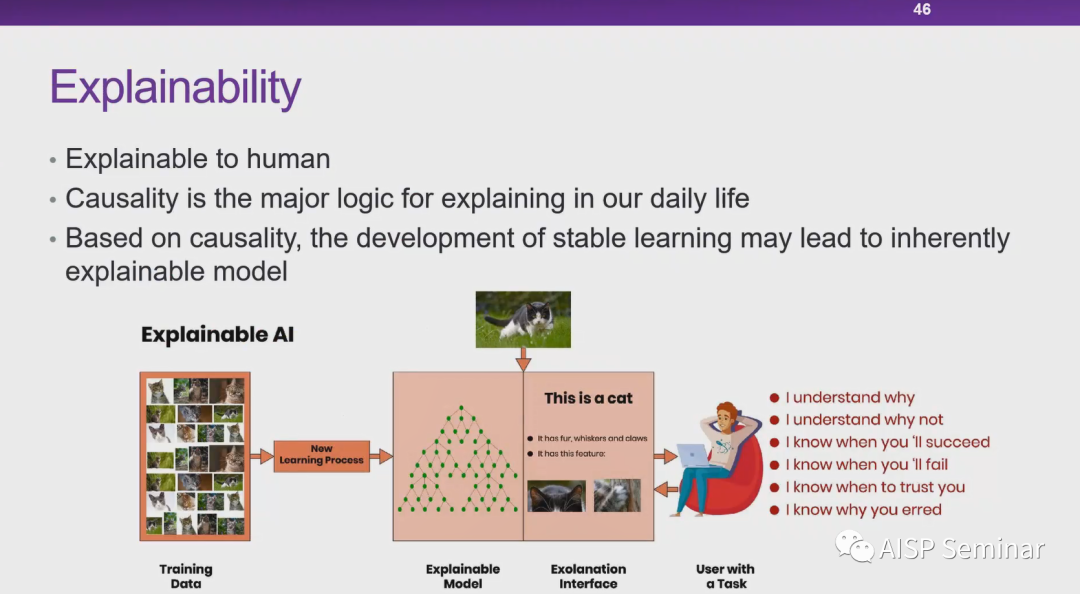
近年来,由于许多决策系统越来越依赖深度学习,AI模型的可解释性便成为了该团队亟需突破的难题。于是,该团队以“为内部基于AI决策系统提供决策归因及可靠性分析“为目标,在可解释性方向积累原创算法10多项,顶级会议文章5篇,并且在2022年发布业内首份可解释AI报告,涵盖了AI制药、自然语言处理、风控等多个领域。
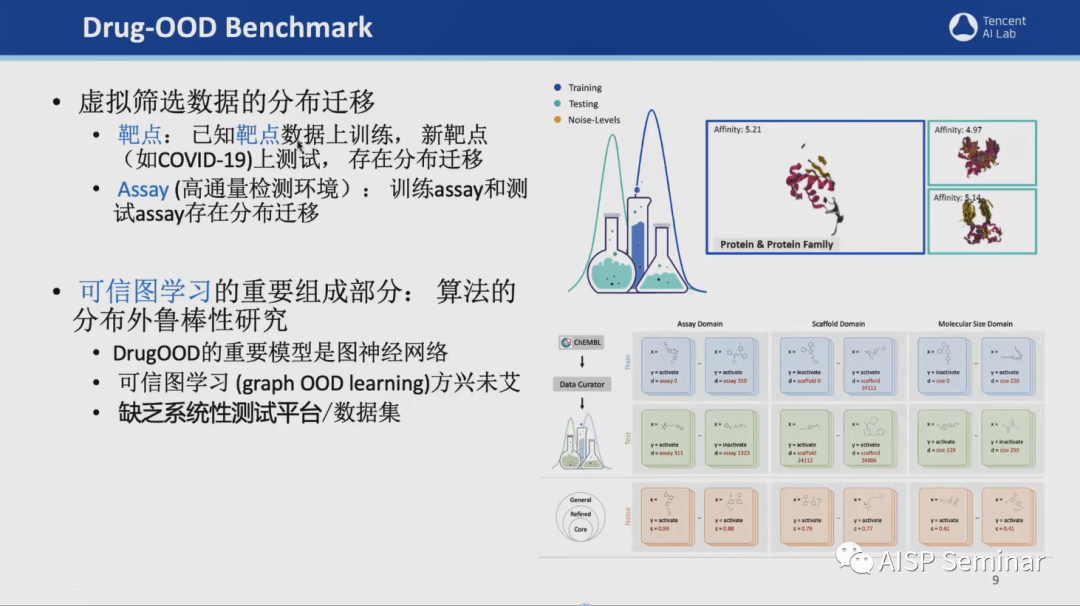
除了以上提到的对抗鲁棒性和模型可解释性外,该团队在对分布迁移的研究上也有卓越的贡献。为了解决分布迁移鲁棒性的问题,该团队研发了首个自动化数据整理器,DrugOOD,可提供96个样例数据集,并且支持定制化生成数据集测评不同学习范式(元学习、迁移学习、稳定学习等)。此外,为了更加真实地模拟现实场景中的数据分布,可支持域标定和真实噪声标定。



02
科技向善
科技向善研究组成立与2017年,致力于从用户的关切点出发进而提供更有价值的产品和服务。在AI作为一种新的技术形态并在人类生活扮演着关键角色的社会中,科技向善研究组正在竭尽全力找到一种平衡,即充分考虑可解释性的要求和其他重要伦理价值之间的平衡,来打造可信、负责任的AI。科技向善组也参与了2022可解释AI白皮书的撰写,从专业的角度对理念概述、监管趋势、行业实践、发展建议等进行了详细说明。






圆桌讨论
之后由腾讯研究院高研究员曹建峰主持,清华大学副教授崔鹏,腾讯AI lab AI医疗首席科学家姚建华,中国人民大学未来法治研究院执行院长张吉豫作为圆桌嘉宾,研讨关于可信AI的技术探索与法律保障。
Q
圆桌讨论的第一个话题,关于可信AI的价值,第三次人工智能浪潮的一个核心就是可信AI。AI技术的应用普及到底有什么样的价值。
崔鹏教授:我觉得从我个人的角度来讲可信AI是大势所趋,现在把AI提升到国家级战略,是下一次生产力释放的核心,它会越来越多地对于风险非常敏感,或者很严肃的领域里面去。对与几个标志性的事件,包括IBM的沃森,Watson宣告失败。AI技术本身落地应用的发展,就是要求关注可信AI。现在从研究和企业产业界可能是把可信当成是束缚,但我想AI的广泛应用,一定会出台具有全球认同的一些标准,在这样的一个体系下边,谁能够最大化的发挥数据的效力,我想这个实际上会成为这个AI时代的一个核心竞争力。
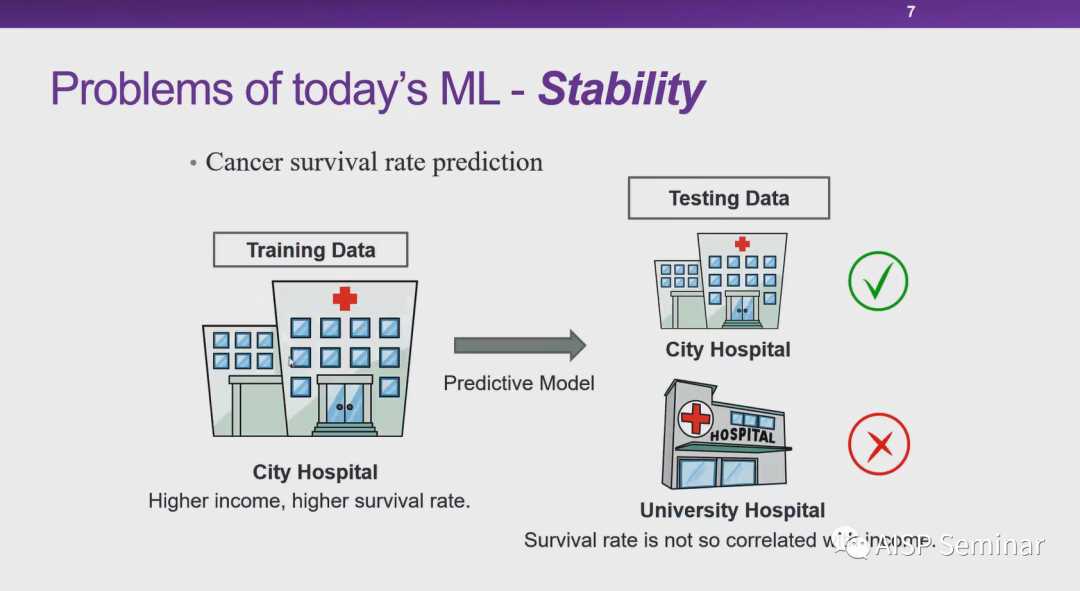
姚建华研究员:我也从医疗应用角度来讲一下可信ai的重要性价值。医疗实际上是AI的一个重要应用场景,希望AI能够缓解医疗资源不足而分配不均的问题,以提高诊疗水平。但是目前AI在医疗上落地上还有一些瓶颈,实际上这些瓶颈主要涉及模型的泛化性,可解释性以及数据安全。首先是模型的泛化性也就是刚刚崔教授提到的稳定性。医疗不同数据之间的异质性非常强,性能不稳定,会造成使用者对AI的不信任。因此我们需要研究可信AI的技术提高模型的泛化性。第二点就是AI模型的可解释性,医学是一个循证医学,诊断跟治疗上都是有依据,AI可以比较精确计算,如何将AI精确计算出来的一些特征转化成医生可以理解内容,这也是一个重要问题。第三点是一些数据安全的问题,目前医疗数据一般会对数据进行脱敏,去掉病人的一些身份信息。但是有时候是不够的。比如说利用联邦学习使得数据可用不可见。我们需要通过从技术跟法规两个角度来保护和增强数据的安全。因此我觉得这三点对人工智能在医疗上的落地跟普及是非常重要的。
张吉豫院长:我觉得,首先从法律的角度来看,可信AI这部分的制度构建。在当前前沿的信息技术的背景之下,看到万物能够互联,万物可计算的社会。那么如何更好地利用数据,计算能力等等。AI算法是非常重要的。那特别我们结合到十四五规划,数字中国的建设,AI算法会更广泛的应用在我们生活的各个领域,智能家居,道路交通,医疗等等。这个社会各界对于人工智能伦理问题,首先就是它的可信问题展开了研究讨论。我们国家,也是非常的重视,从一七年国务院印发新一代人工智能发展规划中,强调了要加强相关的法律伦理和社会问题的研究和相应的法律法规道德伦理道德框架的这种建设,还制定了三个阶段的发展规划。世界范围内的就有很多企业、协会、行业组织、政府都发布和研究了人工智能相应的一些伦理的守则包括对于关于人类利益的重视对于可解释性、安全性、公平性、隐私保护等等。现在也越来越广泛的科研人员都去理解和进行研究在不同的要求和利益关系,特别注重技术和法治的结合,也特别注重通过多元工资,分层分类的治理等等一些方式去实现安全和发展的并重。
Q
我们要讨论的下一个问题,机器学习的可解释性,各位嘉宾针对可解释性有什么思考?
崔鹏教授:从两个不同层面谈了对可解释性的理解,分别公众对模型的运作制度的理解以及研究者对模型工作机制的理解。后者则需要研究人员从内在的角度构建一个可解释的模型,而这往往需要依靠因果逻辑来支撑。
姚建华研究员:我认为在医疗的筛查、诊断和预后的三个任务中模型的可解释性对不同任务而言要求也各不相同。现阶段针对医疗可解释性的研究通常从以下三个角度出发,分别是模型自身的可解释性(如决策树)、深度学习网络中的注意力机制以及与已有结果的关联性。
张吉豫院长:从法律的角度,我阐述一下可解释性对于企业以及社会的重要性。首先,对于企业而言,是应该主动建立模型可解释性的管理制度,以满足模型定期审核的要求。其次,若涉及个人重大个人利益,公民应有让模型做出解释的合法权益。由于未来人工智能的应用场景更加多元且复杂,所以更需要结合具体场景来分析关于模型可解释性的要求以及解释方式等关键制度因素。
Q
还有第三个问题,我想请各位老师简单的去谈一下这个科技事业,跟公平性的相关,还有AI的公平性?
崔鹏教授:我觉得AI公平性主要分三个层次第一个层次叫宏观公平,从商业的角度来讲,他讲的是企业和消费者之间是不是公平,比如所谓的大数据杀熟,它背后体现的是宏观的公平性。这一部分实际上是对于政策法规,或者对于政策制定者,调控者,管理者的一个可解释。中观公平,指的是人群和人群之间的公平,这个实际上面向的是社会的可解释,还有一类,叫做个体公平对个体怎么去解释这个问题。我们是不是能够去。发现不公平的来源,从本质上来讲,还是要能够一定程度上去理解这个数据和这个算法的一个产生的机制和过程,这是我的看法。
姚建华研究员:我认为可解释性跟公平性是两个不同的维度但是他们也是关联的。提高公平性我觉得,更多需要从数据本身去入手因为主要是数据本身的一些偏见可能会造成就AI模型的结果的一个不公平,我们如果要建建立更公平的一个模型,可能需要更全面的数据,然后就解释性刚才也提到他解释性可能是可以促进公平性,不仅仅是结果,而且解释数据的一些分布跟来源,可能可以间接的提高模型的公平性。
张吉豫院长:我觉得从法律的角度来看,关于公平性的问题,一个是对于公民权益保护的这个领域,也包括消费者权益保护等等。那另外一个,就是商业竞争领域,特别是在具有市场支配地位的情况下,那他可能涉及到这种排除限制竞争的自我优待等等问题。在司法执法的过程之中,也需要去进行解释。这就涉及到我们能不能够去证明,在这里没有一个明显的就是人为故意的对于公平性的这种干预等等。可解释性的增长增强,一方面可以更好的帮助相应的算法的实施者在事前去检验中间的一些法律禁止的歧视行为,那另外一方面,在应对具体的司法和执法的过程之中,可能也可以用于去解释一些歧视,不公平的问题。
Q
谈一下对这个可信AI的这个未来的一个发展的一个展望,或者期待。
崔鹏教授:我是相信可信AI肯定是未来人工智能的会成为主战场,所以希望有更多的这个,尤其是我们学界,我们国内现在这方面,其实力量还是薄弱的,需要希望我们更多的学界的同仁能够加入到这个这个方向里面来,培养更多的可信AI的人才,谢谢。
姚建华研究员:我是期望通过可信AI技术的发展,促进了AI智能在医疗领域的落地,然后提高整体的医疗技术,帮助医生,造福病人,谢谢。
来源:CSIG数字媒体取证与安全专业委员会