干货|当深度学习遇见自动文本摘要,seq2seq+attention
随着近几年文本信息的爆发式增长,人们每天能接触到海量的文本信息,如新闻、博客、聊天、报告、论文、微博等。从大量文本信息中提取重要的内容,已成为我们的一个迫切需求,而自动文本摘要(automatic text summarization)则提供了一个高效的解决方案。
根据Radev的定义[3],摘要是“一段从一份或多份文本中提取出来的文字,它包含了原文本中的重要信息,其长度不超过或远少于原文本的一半”。自动文本摘要旨在通过机器自动输出简洁、流畅、保留关键信息的摘要。
自动文本摘要有非常多的应用场景,如自动报告生成、新闻标题生成、搜索结果预览等。此外,自动文本摘要也可以为下游任务提供支持。
尽管对自动文本摘要有庞大的需求,这个领域的发展却比较缓慢。对计算机而言,生成摘要是一件很有挑战性的任务。从一份或多份文本生成一份合格摘要,要求计算机在阅读原文本后理解其内容,并根据轻重缓急对内容进行取舍,裁剪和拼接内容,最后生成流畅的短文本。因此,自动文本摘要需要依靠自然语言处理/理解的相关理论,是近几年来的重要研究方向之一。
自动文本摘要通常可分为两类,分别是抽取式(extractive)和生成式(abstractive)。抽取式摘要判断原文本中重要的句子,抽取这些句子成为一篇摘要。而生成式方法则应用先进的自然语言处理的算法,通过转述、同义替换、句子缩写等技术,生成更凝练简洁的摘要。比起抽取式,生成式更接近人进行摘要的过程。历史上,抽取式的效果通常优于生成式。伴随深度神经网络的兴起和研究,基于神经网络的生成式文本摘要得到快速发展,并取得了不错的成绩。
本文主要介绍基于深度神经网络的生成式自动文本摘要,着重讨论典型的摘要模型,并介绍如何评价自动生成的摘要。对抽取式和不基于深度神经网络的生成式自动文本摘要感兴趣的同学可以参考[1][2]。
生成式文本摘要
生成式文本摘要以一种更接近于人的方式生成摘要,这就要求生成式模型有更强的表征、理解、生成文本的能力。传统方法很难实现这些能力,而近几年来快速发展的深度神经网络因其强大的表征(representation)能力,提供了更多的可能性,在图像分类、机器翻译等领域不断推进机器智能的极限。借助深度神经网络,生成式自动文本摘要也有了令人瞩目的发展,不少生成式神经网络模型(neural-network-based abstractive summarization model)在DUC-2004测试集上已经超越了最好的抽取式模型[4]。这部分文章主要介绍生成式神经网络模型的基本结构及最新成果。
基本模型结构
生成式神经网络模型的基本结构主要由编码器(encoder)和解码器(decoder)组成,编码和解码都由神经网络实现。
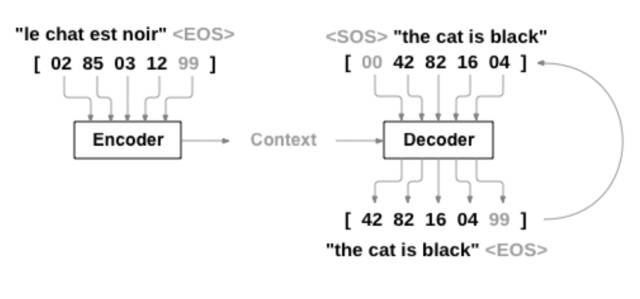
编码器负责将输入的原文本编码成一个向量(context),该向量是原文本的一个表征,包含了文本背景。而解码器负责从这个向量提取重要信息、加工剪辑,生成文本摘要。这套架构被称作Sequence-to-Sequence(以下简称Seq2Seq),被广泛应用于存在输入序列和输出序列的场景,比如机器翻译(一种语言序列到另一种语言序列)、image captioning(图片像素序列到语言序列)、对话机器人(如问题到回答)等。
Seq2Seq架构中的编码器和解码器通常由递归神经网络(RNN)或卷积神经网络(CNN)实现。
基于递归神经网络的模型
RNN被称为递归神经网络,是因为它的输出不仅依赖于输入,还依赖上一时刻输出。
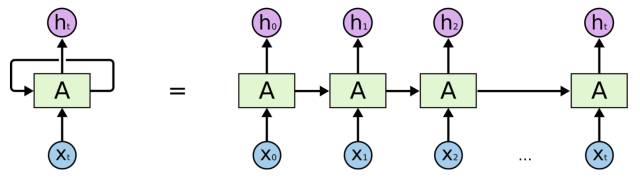
如上图所示,t时刻的输出h不仅依赖t时刻的输入x,还依赖t-1时刻的输出,而t-1的输出又依赖t-1的输入和t-2输出,如此递归,时序上的依赖使RNN在理论上能在某时刻输出时,考虑到所有过去时刻的输入信息,特别适合时序数据,如文本、语音、金融数据等。因此,基于RNN实现Seq2Seq架构处理文本任务是一个自然的想法。
典型的基于RNN的Seq2Seq架构如下图所示:
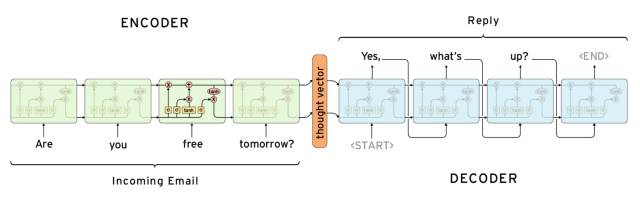
图中展示的是一个用于自动回复邮件的模型,它的编码器和解码器分别由四层RNN的变种LSTM[5]组成。图中的向量thought vector编码了输入文本信息(Are you free tomorrow?),解码器获得这个向量依次解码生成目标文本(Yes, what's up?)。上述模型也可以自然地用于自动文本摘要任务,这时的输入为原文本(如新闻),输出为摘要(如新闻标题)。
目前最好的基于RNN的Seq2Seq生成式文本摘要模型之一来自Salesforce,在基本的模型架构上,使用了注意力机制(attention mechanism)和强化学习(reinforcement learning)。这个模型将在下文中详细介绍。
基于卷积神经网络的模型
Seq2Seq同样也可以通过CNN实现。不同于递归神经网络可以直观地应用到时序数据,CNN最初只被用于图像任务[6]。
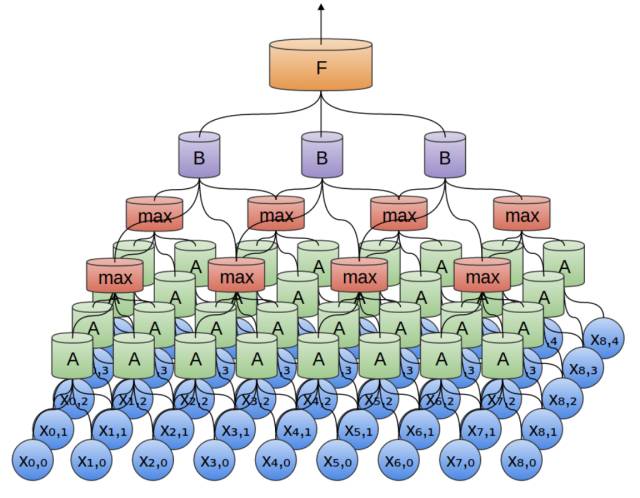
CNN通过卷积核(上图的A和B)从图像中提取特征(features),间隔地对特征作用max pooling,得到不同阶层的、由简单到复杂的特征,如线、面、复杂图形模式等,如下图所示。
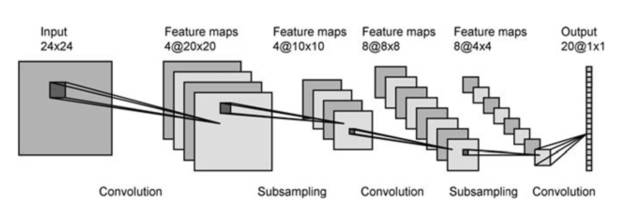
CNN的优势是能提取出hierarchical的特征,并且能并行高效地进行卷积操作,那么是否能将CNN应用到文本任务中呢?原生的字符串文本并不能提供这种可能性,然而,一旦将文本表现成分布式向量(distributed representation/word embedding)[7],我们就可以用一个实数矩阵/向量表示一句话/一个词。这样的分布式向量使我们能够在文本任务中应用CNN。
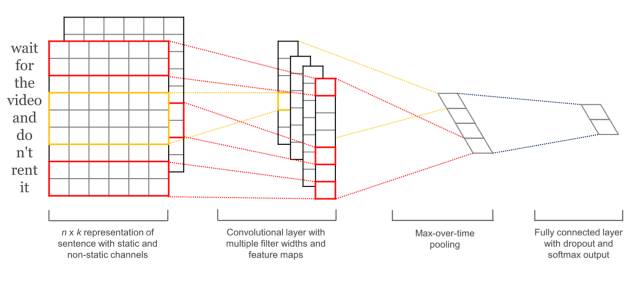
如上图所示,原文本(wait for the video and do n't rent it)由一个实数矩阵表示,这个矩阵可以类比成一张图像的像素矩阵,CNN可以像“阅读”图像一样“阅读”文本,学习并提取特征。虽然CNN提取的文本特征并不像图像特征有显然的可解释性并能够被可视化,CNN抽取的文本特征可以类比自然语言处理中的分析树(syntactic parsing tree),代表一句话的语法层级结构。
基于卷积神经网络的自动文本摘要模型中最具代表性的是由Facebook提出的ConvS2S模型[9],它的编码器和解码器都由CNN实现,同时也加入了注意力机制,下文将详细介绍。
当然,我们不仅可以用同一种神经网络实现编码器和解码器,也可以用不同的网络,如编码器基于CNN,解码器基于RNN。
前沿
A Deep Reinforced Model for Abstractive Summarization
这是由Salesforce研究发表的基于RNN的生成式自动文本摘要模型,通过架构创新和若干tricks提升模型概括长文本的能力,在CNN/Daily Mail、New York Times数据集上达到了新的state-of-the-art(最佳性能)。
针对长文本生成摘要在文本摘要领域是一项比较困难的任务,即使是过去最好的深度神经网络模型,在处理这项任务时,也会出现生成不通顺、重复词句等问题。为了解决上述问题,模型作者提出了内注意力机制(intra-attention mechanism)和新的训练方法,有效地提升了文本摘要的生成质量。
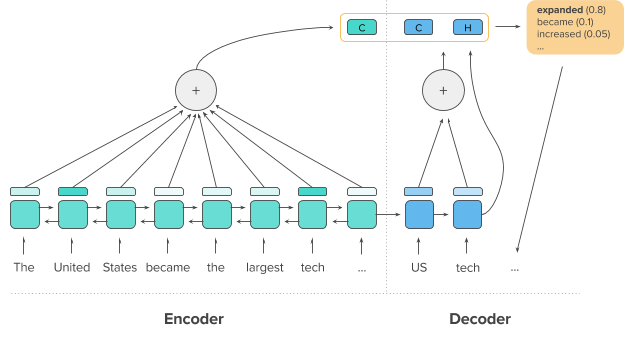
模型里应用了两套注意力机制,分别是1)经典的解码器-编码器注意力机制,和2)解码器内部的注意力机制。前者使解码器在生成结果时,能动态地、按需求地获得输入端的信息,后者则使模型能关注到已生成的词,帮助解决生成长句子时容易重复同一词句的问题。
模型的另一创新,是提出了混合式学习目标,融合了监督式学习(teacher forcing)和强化学习(reinforcement learning)。
首先,该学习目标包含了传统的最大似然。最大似然(MLE)在语言建模等任务中是一个经典的训练目标,旨在最大化句子中单词的联合概率分布,从而使模型学习到语言的概率分布。
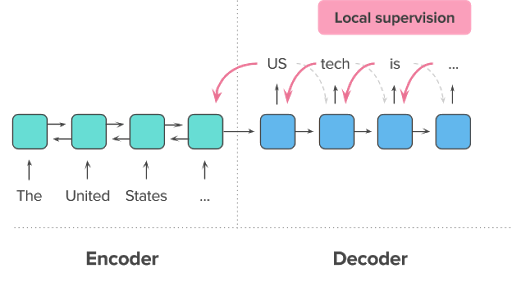
但对于文本摘要,仅仅考虑最大似然并不够。主要有两个原因,一是监督式训练有参考“答案”,但投入应用、生成摘要时却没有。比如t时刻生成的词是"tech",而参考摘要中是"science",那么在监督式训练中生成t+1时刻的词时,输入是"science",因此错误并没有积累。但在实际应用中,由于没有ground truth,t+1时刻的输入是错误的"tech"。这样引起的后果是因为没有纠正,错误会积累,这个问题被称为exposure bias。另一个原因是,往往在监督式训练中,对一篇文本一般只提供一个参考摘要,基于MLE的监督式训练只鼓励模型生成一模一样的摘要,然而正如在介绍中提到的,对于一篇文本,往往可以有不同的摘要,因此监督式学习的要求太过绝对。与此相反,用于评价生成摘要的ROUGE指标却能考虑到这一灵活性,通过比较参考摘要和生成的摘要,给出摘要的评价(见下文评估摘要部分)。所以希望在训练时引入ROUGE指标。但由于ROUGE并不可导的,传统的求梯度+backpropagation并不能直接应用到ROUGE。因此,一个很自然的想法是,利用强化学习将ROUGE指标加入训练目标。
那么我们是怎么通过强化学习使模型针对ROUGE进行优化呢?简单说来,模型先以前向模式(inference)生成摘要样本,用ROUGE指标测评打分,得到了对这个样本的评价/回报(reward)后,再根据回报更新模型参数:如果模型生成的样本reward较高,那么鼓励模型;如果生成的样本评价较低,那么抑制模型输出此类样本。
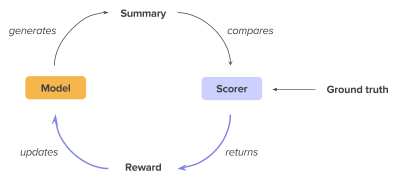
最终的训练目标是最大似然和基于ROUGE指标的函数的加权平均,这两个子目标各司其职:最大似然承担了建立好的语言模型的责任,使模型生成语法正确、文字流畅的文本;而ROUGE指标则降低exposure bias,允许摘要拥有更多的灵活性,同时针对ROUGE的优化也直接提升了模型的ROUGE评分。
构建一个好的模型,除了在架构上需要有创新,也需要一些小技巧,这个模型也不例外。在论文中,作者使用了下列技巧:
使用指针处理未知词(OOV)问题;
共享解码器权重,加快训练时模型的收敛;
人工规则,规定不能重复出现连续的三个词。
综上所述,深度学习+强化学习是一个很好的思路,这个模型第一次将强化学习应用到文本摘要任务中,取得了不错的表现。相信同样的思路还可以用在其他任务中。
Convolutional Sequence to Sequence Learning
ConvS2S模型由Facebook的AI实验室提出,它的编码器和解码器都是基于卷积神经网络搭建的。这个模型主要用于机器翻译任务,在论文发表的时候,在英-德、英-法两个翻译任务上都达到了state-of-the-art。同时,作者也尝试将该模型用于自动文本摘要,实验结果显示,基于CNN的Seq2Seq模型也能在文本摘要任务中达到接近state-of-the-art的表现。
模型架构如下图所示。乍看之下,模型很复杂,但实际上,它的每个部分都比较直观,下面通过分解成子模块,详细介绍ConvS2S。
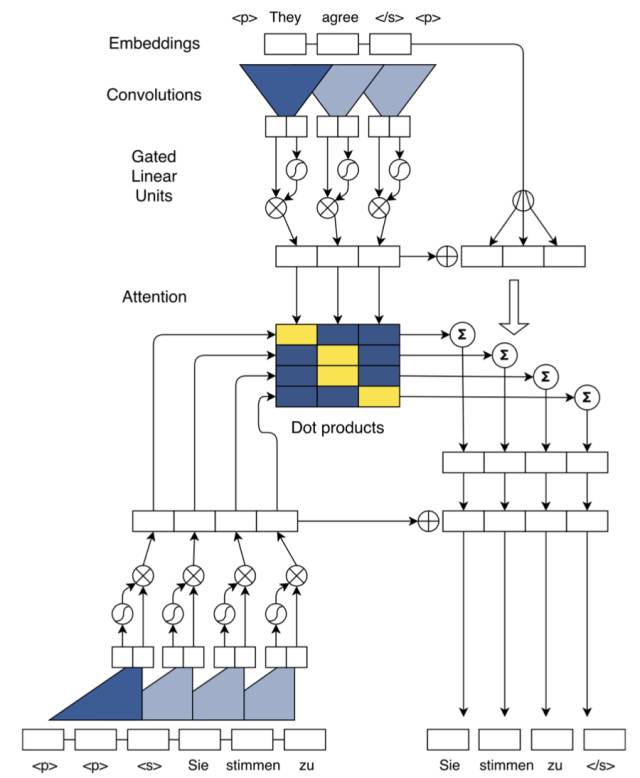
首先来看embedding部分。
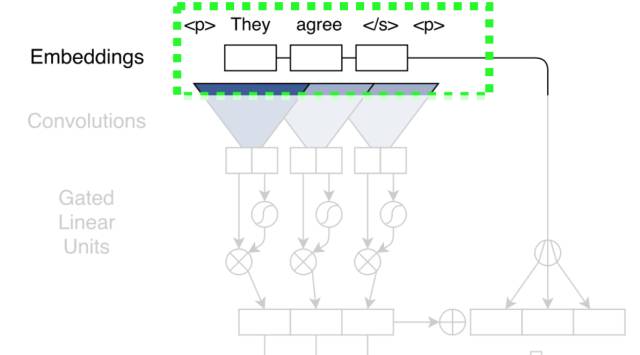
这个模型的embedding比较新颖,除了传统的semantic embedding/word embedding,还加入了position embedding,将词序表示成分布式向量,使模型获得词序和位置信息,模拟RNN对词序的感知。最后的embedding是语义和词序embedding的简单求和。
之后,词语的embedding作为输入进入到模型的卷积模块。
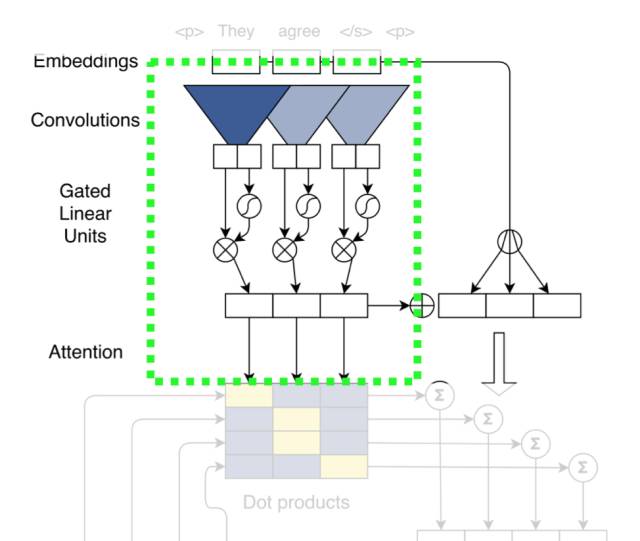
这个卷积模块可以视作是经典的卷积加上非线性变换。虽然图中只画出一层的情况,实际上可以像经典的卷积层一样,层层叠加。
这里着重介绍非线性变换。

该非线性变换被称为Gated Linear Unit (GLU)[10]。它将卷积后的结果分成两部分,对其中一部分作用sigmoid变换,即映射到0到1的区间之后,和另一部分向量进行element-wise乘积。
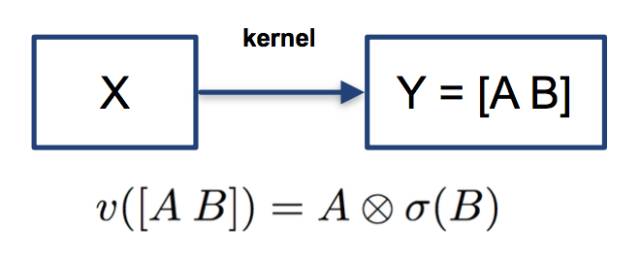
这个设计让人联想到LSTM中的门结构。GLU从某种程度上说,是在模仿LSTM和GRU中的门结构,使网络有能力控制信息流的传递,GLU在language modeling被证明是非常有效的[10]。
除了将门架构和卷积层结合,作者还使用了残差连接(residual connection)[11]。residual connection能帮助构建更深的网络,缓解梯度消失/爆炸等问题。
除了使用加强版的卷积网络,模型还引入了带多跳结构的注意力机制(multi-step attention)。不同于以往的注意力机制,多跳式注意力不仅要求解码器的最后一层卷积块关注输入和输出信息,而且还要求每一层卷积块都执行同样的注意力机制。如此复杂的注意力机制使模型能获得更多的历史信息,如哪些输入已经被关注过。
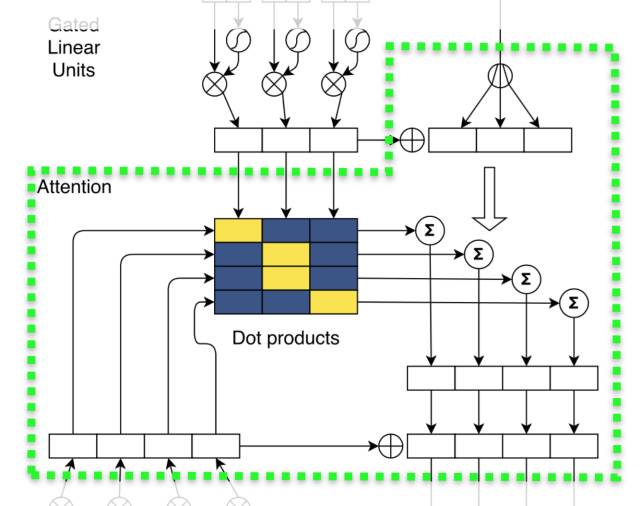
像A Deep Reinforced Model for Abstractive Summarization一样,ConvS2S的成功之处不仅在于创新的结构,还在于细致入微的小技巧。在ConvS2S中,作者对参数使用了非常仔细的初始化和规范化(normalization),稳定了方差和训练过程。
这个模型的成功证明了CNN同样能应用到文本任务中,通过层级表征长程依赖(long-range dependency)。同时,由于CNN具有可高度并行化的特点,所以CNN的训练比RNN更高效。比起RNN,CNN的不足是有更多的参数需要调节。
评估摘要
评估一篇摘要的质量是一件比较困难的任务。
对于一篇摘要而言,很难说有标准答案。不同于很多拥有客观评判标准的任务,摘要的评判一定程度上依赖主观判断。即使在摘要任务中,有关于语法正确性、语言流畅性、关键信息完整度等标准,摘要的评价还是如同”一千个人眼里有一千个哈姆雷特“一样,每个人对摘要的优劣都有自己的准绳。
自上世纪九十年代末开始,一些会议或组织开始致力于制定摘要评价的标准,他们也会参与评价一些自动文本摘要。比较著名的会议或组织包括SUMMAC,DUC(Document Understanding Conference),TAC(Text Analysis Conference)等。其中DUC的摘要任务被广泛研究,大多数abstractive摘要模型在DUC-2004数据集上进行测试。
目前,评估自动文本摘要质量主要有两种方法:人工评价方法和自动评价方法。这两类评价方法都需要完成以下三点:
决定原始文本最重要的、需要保留的部分;
在自动文本摘要中识别出1中的部分;
基于语法和连贯性(coherence)评价摘要的可读性(readability)。
人工评价方法
评估一篇摘要的好坏,最简单的方法就是邀请若干专家根据标准进行人工评定。这种方法比较接近人的阅读感受,但是耗时耗力,无法用于对大规模自动文本摘要数据的评价,和自动文本摘要的应用场景并不符合。因此,文本摘要研究团队积极地研究自动评价方法。
自动评价方法
为了更高效地评估自动文本摘要,可以选定一个或若干指标(metrics),基于这些指标比较生成的摘要和参考摘要(人工撰写,被认为是正确的摘要)进行自动评价。目前最常用、也最受到认可的指标是ROUGE(Recall-Oriented Understudy for Gisting Evaluation)。ROUGE是Lin提出的一个指标集合,包括一些衍生的指标,最常用的有ROUGE-n,ROUGE-L,ROUGE-SU:
ROUGE-n:该指标旨在通过比较生成的摘要和参考摘要的n-grams(连续的n个词)评价摘要的质量。常用的有ROUGE-1,ROUGE-2,ROUGE-3。
ROUGE-L:不同于ROUGE-n,该指标基于最长公共子序列(LCS)评价摘要。如果生成的摘要和参考摘要的LCS越长,那么认为生成的摘要质量越高。该指标的不足之处在于,它要求n-grams一定是连续的。
ROUGE-SU:该指标综合考虑uni-grams(n = 1)和bi-grams(n = 2),允许bi-grams的第一个字和第二个字之间插入其他词,因此比ROUGE-L更灵活。
作为自动评价指标,ROUGE和人工评定的相关度较高,在自动评价摘要中能给出有效的参考。但另一方面,从以上对ROUGE指标的描述可以看出,ROUGE基于字的对应而非语义的对应,生成的摘要在字词上与参考摘要越接近,那么它的ROUGE值将越高。但是,如果字词有区别,即使语义上类似,得到的ROUGE值就会变低。换句话说,如果一篇生成的摘要恰好是在参考摘要的基础上进行同义词替换,改写成字词完全不同的摘要,虽然这仍是一篇质量较高的摘要,但ROUGE值会呈现相反的结论。从这个极端但可能发生的例子可以看出,自动评价方法所需的指标仍然存在一些不足。目前,为了避免上述情况的发生,在evaluation时,通常会使用几篇摘要作为参考和基准,这有效地增加了ROUGE的可信度,也考虑到了摘要的不唯一性。对自动评价摘要方法的研究和探索也是目前自动文本摘要领域一个热门的研究方向。
总结
本文主要介绍了基于深度神经网络的生成式文本摘要,包括基本模型和最新进展,同时也介绍了如何评价自动生成的摘要。自动文本摘要是目前NLP的热门研究方向之一,从研究落地到实际业务,还有一段路要走,未来可能的发展方向有:1)模仿人撰写摘要的模式,融合抽取式和生成式模型;2)研究更好的摘要评估指标。希望本文能帮助大家更好地了解深度神经网络在自动文本摘要任务中的应用。


