
题目: Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs
摘要: 近年来随着知识图谱(KGs)的大量涌现,加上实体间缺失关系(链接)的不完全或部分信息,催生了大量关于知识库补全(也称为关系预测)的研究。最近的一些研究表明,基于卷积神经网络(CNN)的模型能够生成更丰富、更有表现力的特征嵌入,因此在关系预测方面也有很好的表现。然而,我们观察到这些KG嵌入独立地处理三元组,因此不能捕获到三元组周围的复杂和隐藏的信息。为此,本文提出了一种新的基于注意的特征嵌入方法,该方法能同时捕获任意给定实体邻域内的实体特征和关系特征。此外,我们还在模型中封装了关系集群和多跳关系。我们的实验研究为我们基于注意力的模型的有效性提供了深入的见解,并且与所有数据集上的最先进的方法相比,有显著的性能提升。
成为VIP会员查看完整内容

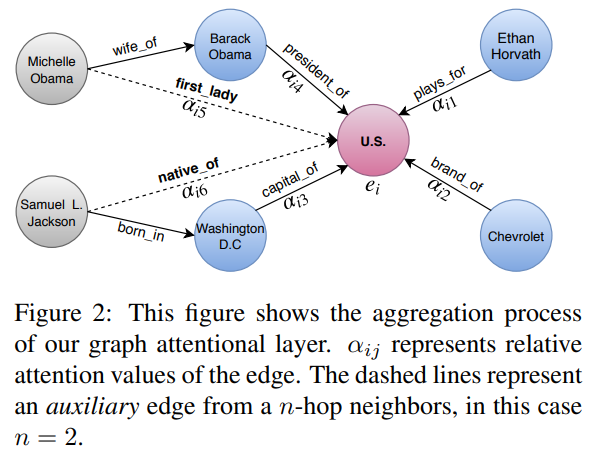
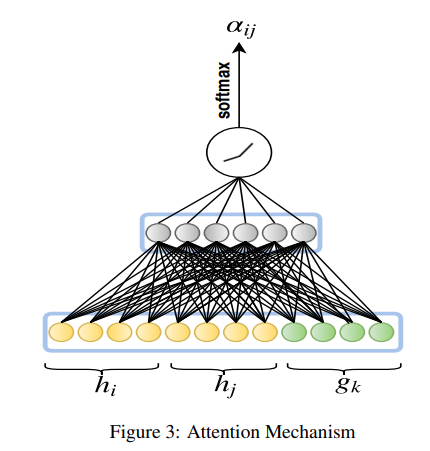
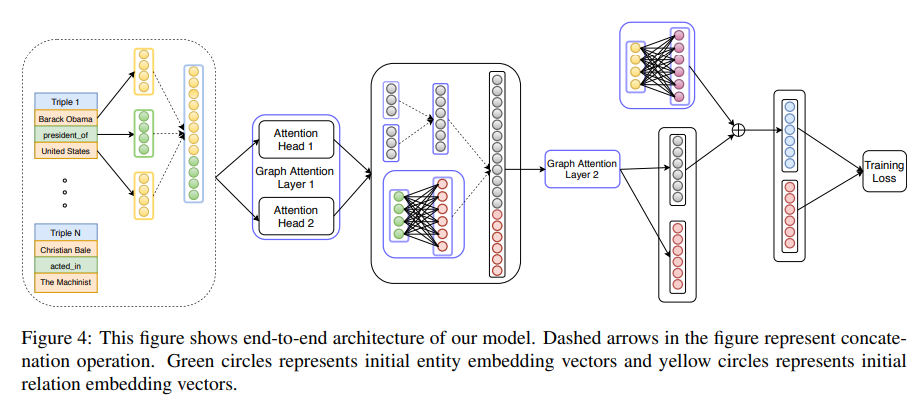
相关内容

知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
专知会员服务
59+阅读 · 2020年6月30日
专知会员服务
78+阅读 · 2020年5月11日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
64+阅读 · 2020年1月11日
Arxiv
12+阅读 · 2019年9月26日
Arxiv
6+阅读 · 2019年8月17日
Arxiv
40+阅读 · 2019年6月4日



相关VIP内容
专知会员服务
59+阅读 · 2020年6月30日
专知会员服务
78+阅读 · 2020年5月11日
专知会员服务
108+阅读 · 2020年3月29日
专知会员服务
64+阅读 · 2020年1月11日
相关资讯
相关论文
Arxiv
12+阅读 · 2019年9月26日
Arxiv
6+阅读 · 2019年8月17日
Arxiv
40+阅读 · 2019年6月4日