LineFlow 开源:比 PyTorch 简洁数倍,适用任何框架的 NLP 数据集处理程序

作者丨Yasufumi TANIGUCHI
译者丨Sambodhi
策划丨赵钰莹
对自然语言处理任务来说,你可能需要在预处理中对文本进行词法分析或构建词汇表。因为这个过程非常痛苦,所以我创建了 LineFlow ,尽可能让整个过程干净整洁。真正的代码看起来是什么样子?请看下面的图,预处理包括词法分析、词汇表构建和索引。
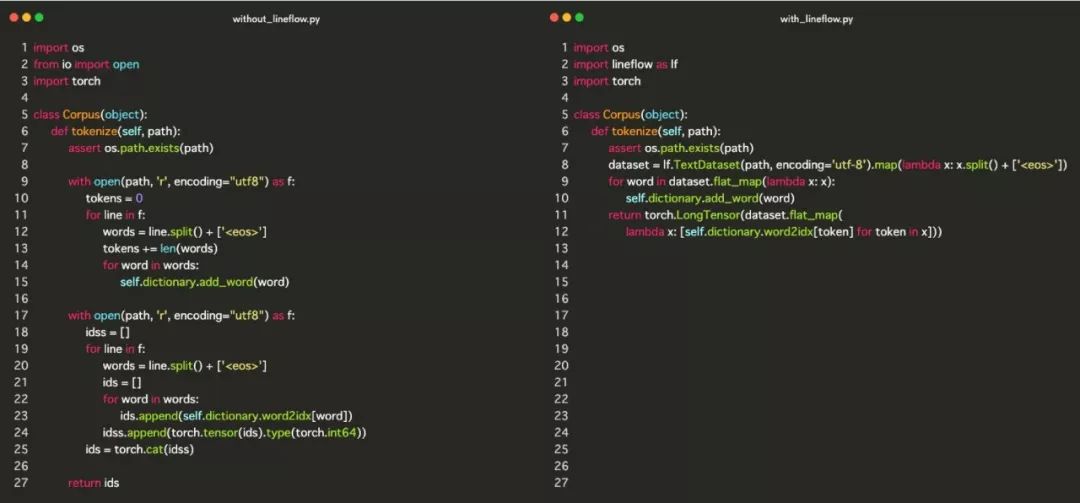
左边部分是来自 PyTorch 官方示例仓库的示例代码,它对文本数据进行常见的预处理。右边部分是用 LineFolw 编写的,实现了完全相同的处理。看完对比之后,你应该明白 LineFlow 是如何减轻痛苦的。要查看完整的代码,可以访问此链接。
在本文中,我将详细解释上图右边部分的代码,并讲解 LineFlow 的用法。
文本数据的加载,是通过上面代码中的第 8 行完成的,我稍后会详细解释这个 map。lf.TextDataset 将文本文件的路径作为参数并进行加载。
dataset = lf.TextDataset(path, encoding='utf-8').map(...)lf.TextDataset 要求的数据格式是每行对应一个数据。如果文本数据满足此条件,则可以加载任何类型的文本数据。


加载之后,它将文本数据转换为列表。列表中的项对应于文本数据中的行。请看下图,这是 lf.TextDataset 的直观图像。图中的 d 代表代码中的 dataset。
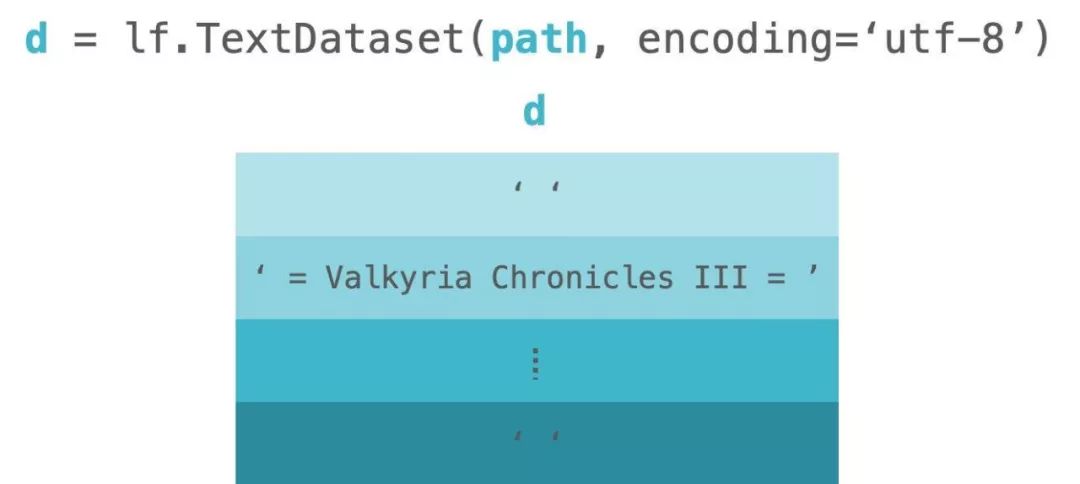
LineFlow 已经提供了一些公开可用的数据集。所以你可以马上使用它。要查看提供的数据集,请访问此链接。
文本标记化也是通过第 8 行完成的。map 将作为参数传递的处理应用到文本数据的每一行。
dataset = lf.TextDataset(...).map(lambda x: x.split() + ['<eos>'])请看下图。这是 lf.TextDataset.map 的直观图像。图中的 d 代表代码中的 dataset。
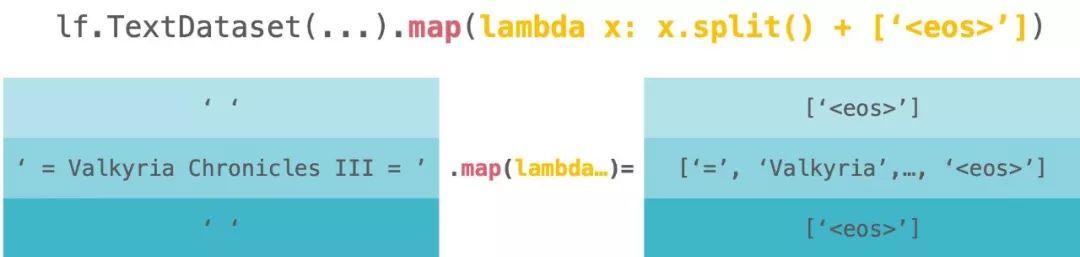
让我们深入了解下面的实际处理过程。
lambda x: x.split() + ['<eos>']我们将文本数据中的每一行按空格拆分为标记,然后将
此时,我们使用 str.split 进行标记化。我们可以使用其他的标记化方法,如 spaCy 、 StanfordNLP 、 Bling Fire 等。例如,如果你想使用 Bling Fire,我们将得到以下代码。
> from blingfire import text_to_words> d = lf.TextDataset('/path/to/your/text')> d.map(text_to_words).map(str.split)
另外,只要我们的处理将每行文本数据作为参数,就可以执行任何我们想要的处理。例如,我们可以计算标记的数量。在下面的代码中,标记的数量是在第二个元素中定义的。
> d = lf.TextDataset('/path/to/text')> d.map(tokenize).map(lambda x: (x, len(x)))
当我们想要制作用于注意力机制或长短期记忆网络的掩码时,这种处理就很有用。
索引是由第 9 行到第 12 行完成的。这些行如下图所示。在这个代码块中,我们构建了词汇表和索引。让我们按顺序来查看这些内容。
for word in dataset.flat_map(lambda x: x):self.dictionary.add_word(word)return torch.LongTensor(dataset.flat_map(...))
首先我们将看到构建词汇表的代码块。在下面的代码块中,我们构建了词汇表。flat_map 将作为参数传递的处理应用于数据中的每一行,然后对其进行扁平化。因此,我们将在 dataset.flat_map(lambda x: x) 之后获取单个标记。
for word in dataset.flat_map(lambda x: x):self.dictionary.add_word(word)
请看下图。这是 dataset.flat_map(lambda x: x) 的直观图像。图中的 d 代表代码中的 'dataset`。

flat_map 有点令人困惑,但它等同于下面的代码。
from itertools import chainchain.from_iterable(map(lambda x: x, dataset))>>>>>> dataset.flat_map(lambda x: x) # same as above
在使用 flat_map 提取每个标记之后,我们将标记传递给 self.dictionary.add_word 来构建词汇表。我将不会解释它是如何工作的,因为这与本文无关。但如果你对它的内部实现感兴趣的话,请查看此链接。
self.dictionary.add_word(word)接下来,我们将看到索引的代码块。索引是由一下的代码块来完成的。我们还使用 flat_map 来索引每个标记并使其扁平化。这是因为 PyTorch 的示例需要扁平化标记的张量,所以我们就这么做了。
dataset.flat_map([] for token in x)])
请看下图。这是 dataset.flat_map(indexer) 的直观图像。图中的 d 代表代码中的 dataset。
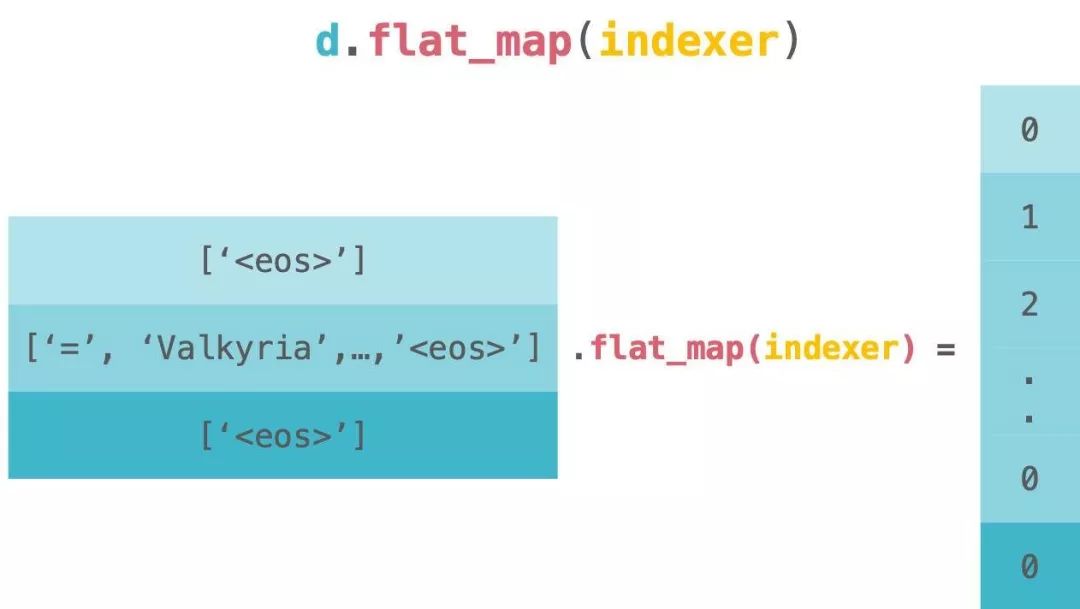
此代码等同于以下代码。
> from itertools import chain> chain.from_iterable(map(indexer, dataset))>>>> dataset.flat_map(indexer) # same as above
最后,我们用 torch.LongTensor 将它包起来,把它变成张量。至此就完成了文本数据的加载。
return torch.LongTensor(dataset.flat_map(...))现在我们可以阅读完整的代码了,如下所示:
import osimport torchimport lineflow as lfclass Dictionary(object):def __init__(self):self.word2idx = {}self.idx2word = []def add_word(self, word):if word not in self.word2idx:self.idx2word.append(word)self.word2idx[word] = len(self.idx2word) - 1return self.word2idx[word]def __len__(self):return len(self.idx2word)class Corpus(object):def __init__(self, path):self.dictionary = Dictionary()self.train = self.tokenize(os.path.join(path, 'train.txt'))self.valid = self.tokenize(os.path.join(path, 'valid.txt'))self.test = self.tokenize(os.path.join(path, 'test.txt'))def tokenize(self, path):assert os.path.exists(path)dataset = lf.TextDataset(path, encoding='utf-8').map(lambda x: x.split() + ['<eos>'])for word in dataset.flat_map(lambda x: x):self.dictionary.add_word(word)return torch.LongTensor(dataset.flat_map(lambda x: [self.dictionary.word2idx[token] for token in x]))
这就是全部的解释。LineFlow 通过对文本数据进行向量化来完成较少的循环和嵌套代码。我们可以使用 Python 的 map 来完成同样的工作。但是,LineFlow 为我们提供了可读的、干净的代码,因为它像管道( Fluent Interface )一样构建了处理过程。
如果你喜欢 LineFlow,并想了解更多信息,请访问 LineFlow 在 GitHub 的仓库。
Yasufumi TANIGUCHI,软件工程师,对自然语言处理有着浓厚的兴趣。本文最初发表于 Medium 博客,经原作者 Yasufumi TANIGUCHI 授权,InfoQ 中文站翻译并分享。
原文链接:
https://towardsdatascience.com/lineflow-introduction-1caf7851125e
InfoQ 读者交流群上线啦!各位小伙伴可以扫描下方二维码,添加 InfoQ 小助手,回复关键字“进群”申请入群。大家可以和 InfoQ 读者一起畅所欲言,和编辑们零距离接触,超值的技术礼包等你领取,还有超值活动等你参加,快来加入我们吧!


点个在看少个 bug 👇



