carla 体验效果 及代码
https://arxiv.org/abs/1710.02410
https://github.com/carla-simulator/imitation-learning 使用了 Direct Future Prediction方法
下载carla二进制版本
server:
./CarlaUE4.sh /Game/Maps/Town01 -opengl3 -carla-server -benchmark -fps=15 -windowed -ResX=800 -ResY=600
client: 如下几种:
效果:
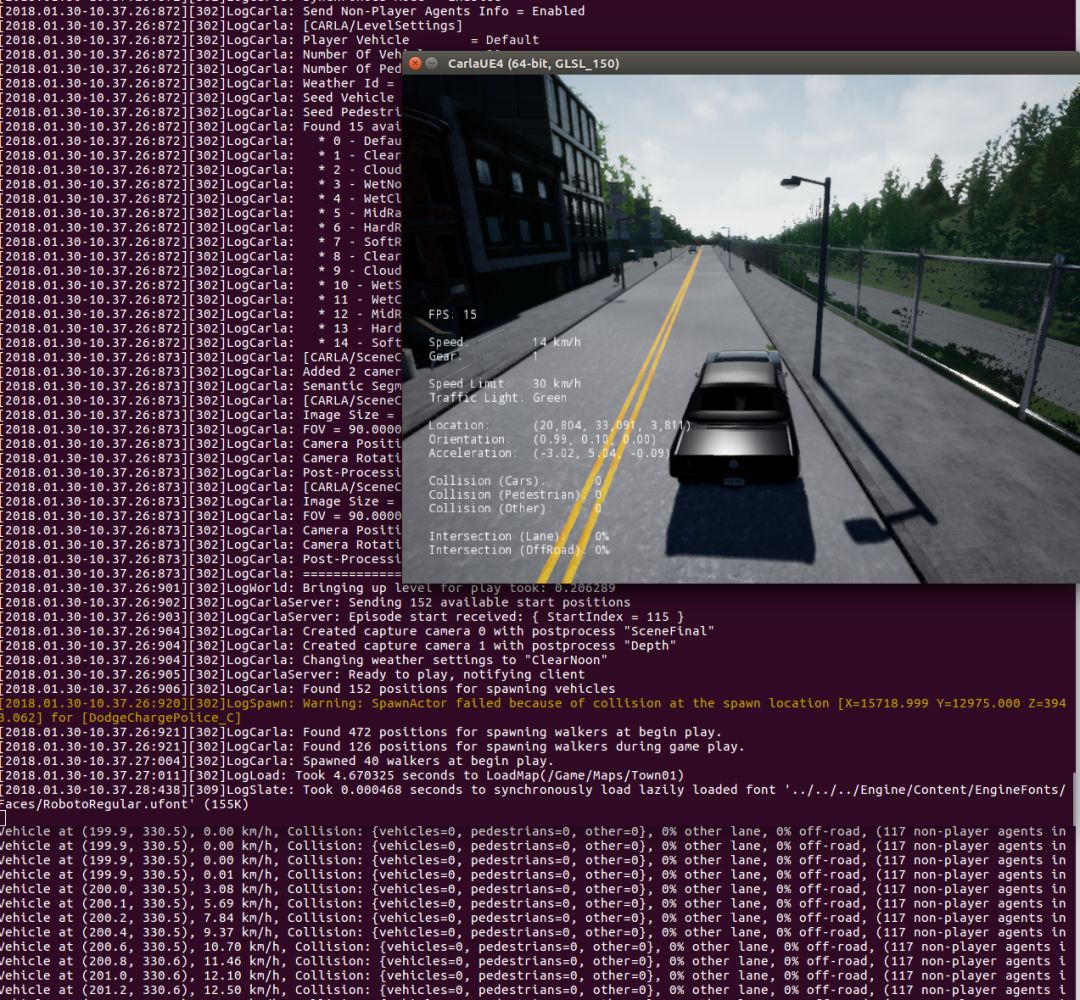
run benchmark.py
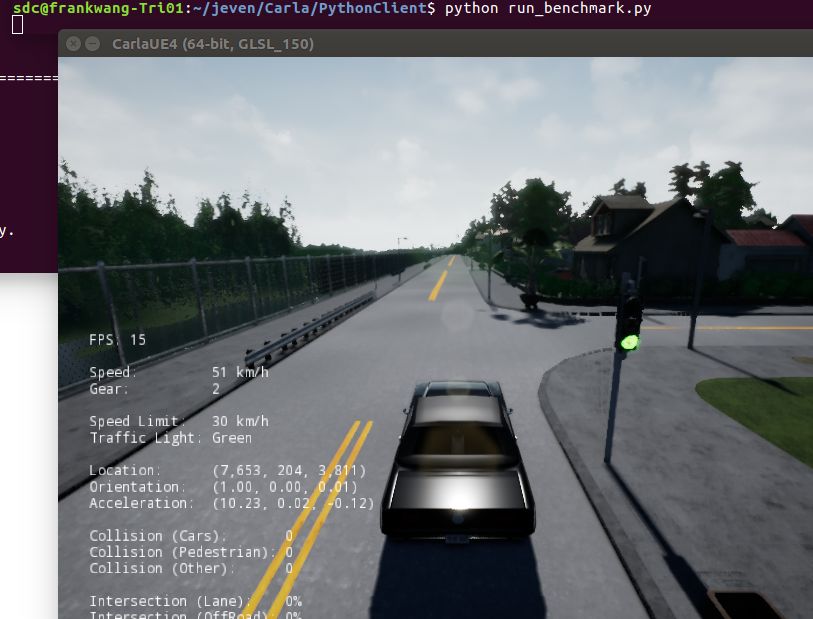
手动模式 ; 深度视图
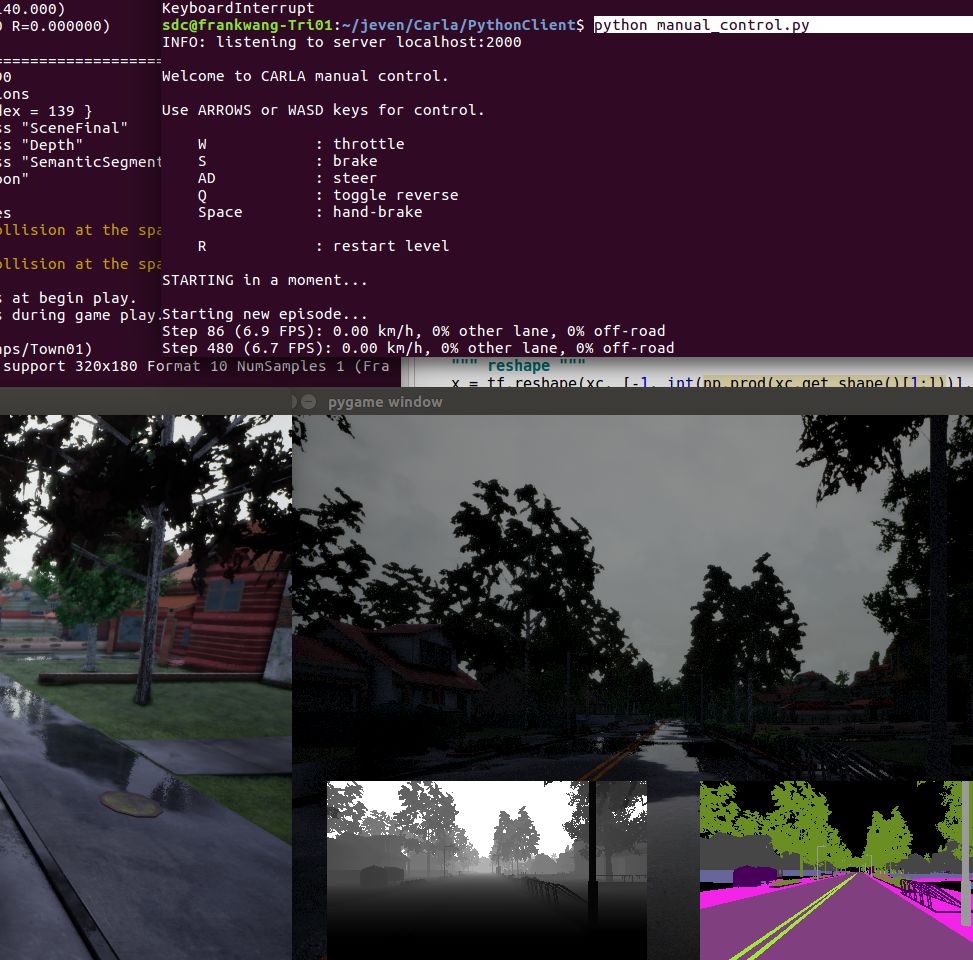
模仿学习的预训练模型
carla imitation 数据fusion
"""conv3"""
xc = network_manager.conv_block(xc, 3, 2, 128, padding_in='VALID')
print xc
xc = network_manager.conv_block(xc, 3, 1, 128, padding_in='VALID')
print xc
"""conv4"""
xc = network_manager.conv_block(xc, 3, 1, 256, padding_in='VALID')
print xc
xc = network_manager.conv_block(xc, 3, 1, 256, padding_in='VALID')
print xc
"""mp3 (default values)"""
""" reshape """
x = tf.reshape(xc, [-1, int(np.prod(xc.get_shape()[1:]))], name='reshape')
print x
""" fc1 """
x = network_manager.fc_block(x, 512)
print x
""" fc2 """
x = network_manager.fc_block(x, 512)
"""Process Control"""
""" Speed (measurements)"""
with tf.name_scope("Speed"):
speed = input_data[1] # get the speed from input data
speed = network_manager.fc_block(speed, 128)
speed = network_manager.fc_block(speed, 128)
""" Joint sensory """
j = tf.concat([x, speed], 1)
j = network_manager.fc_block(j, 512)
End-to-end Driving via Conditional Imitation Learning
Felipe Codevilla, Matthias Müller, Alexey Dosovitskiy, Antonio López, Vladlen Koltun
(Submitted on 6 Oct 2017)
Deep networks trained on demonstrations of human driving have learned to follow roads and avoid obstacles. However, driving policies trained via imitation learning cannot be controlled at test time. A vehicle trained end-to-end to imitate an expert cannot be guided to take a specific turn at an upcoming intersection. This limits the utility of such systems. We propose to condition imitation learning on high-level command input. At test time, the learned driving policy functions as a chauffeur that handles sensorimotor coordination but continues to respond to navigational commands. We evaluate different architectures for conditional imitation learning in vision-based driving. We conduct experiments in realistic three-dimensional simulations of urban driving and on a 1/5 scale robotic truck that is trained to drive in a residential area. Both systems drive based on visual input yet remain responsive to high-level navigational commands. Experimental results demonstrate that the presented approach significantly outperforms a number of baselines. The supplementary video can be viewed at this https URL
使用模拟器 carla也进行了训练,真实环境测试视频也有。
这一表述背后的一个隐含假设是,专家的行动得到了观察的充分解释。也就是说,存在一个函数E,它将观察结果映射到专家的行动: ai = E ( oi )。如果这个假设成立,一个充分表达的近似器将能够在给定足够数据的情况下拟合函数E。这就解释了模仿学习在诸如车道跟踪等任务上的成功。然而,在更复杂的情况下,观测到行动的映射是一个函数的假设被打破了。考虑一个司机接近一个十字路口。驾驶员随后的操作不会被观察结果所解释,而是另外受到驾驶员内部状态(例如预期目的地)的影响。根据这种潜在状态,相同的观察结果可能导致不同的行动。这可以模拟为随机性,但随机公式忽略了行为的根本原因。此外,即使训练有素模仿城市驾驶示范的管制员学会转弯和避免碰撞,它仍然不是一个有用的驾驶系统。它会在街上游荡,在十字路口做出武断的决定。这种车辆中的乘客将不能向控制器传达预期的行进方向,或者不能向控制器给出关于转弯的命令。
为了解决这个问题,我们首先通过向量h显式地建模专家的内部状态,向量h与观察一起解释专家的动作: ai = E ( oi,hi )。向量h可以包括关于专家意图、目标和先前知识的信息。标准仿制品
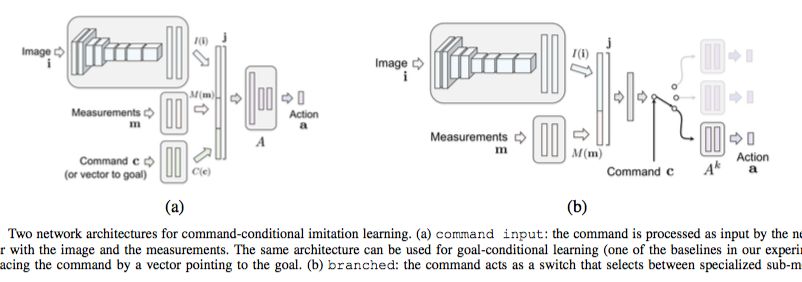
Assume that each observation o = ⟨i,m⟩ comprises an image i and a low-dimensional vector m that we refer to as measurements, following Dosovitskiy and Koltun [9]. The controller F is represented by a deep network. The network takes the image i, the measurements m, and the command c as inputs, and produces an action a as its output. The action space can be discrete, continuous, or a hybrid of these. In our driving experiments, the action space is continuous and two-dimensional: steering angle and acceleration. The acceleration can be negative, which corresponds to braking or driving backwards. The command c is a categorical variable represented by a one-hot vector.
We study two approaches to incorporating the command c into the network. The first architecture is illustrated in Figure 3(a). The network takes the command as an input, alongside the image and the measurements. These three inputs are processed independently by three modules: an image module I (i), a measurement module M (m), and a command module C(c). The image module is implemented as a convolutional network, the other two modules as fully- connected networks. The outputs of these modules are con- catenated into a joint representation:
Actions are two-dimensional vectors that collate steering angle and acceleration: a = ⟨s, a⟩. Given a predicted actiona and a ground truth action agt, the per-sample loss function is defined as
l(a, agt)
= l ⟨s, a⟩ , ⟨sgt, agt⟩
= ∥s−sgt∥2+λa∥a−agt∥2
The recorded control signal is two-dimensional: steering angle and acceleration. The steering angle is scaled between -1 and 1, with extreme values corresponding to full left and full right, respectively. The acceleration is also scaled between -1 and 1, where 1 corresponds to full forward acceleration and -1 to full reverse acceleration.
four commands: continue (follow the road),left (turn left at the next intersection), straight (go straight at the next intersection), and right (turn right at the next intersection). In practice, we represent these as one- hot vectors.
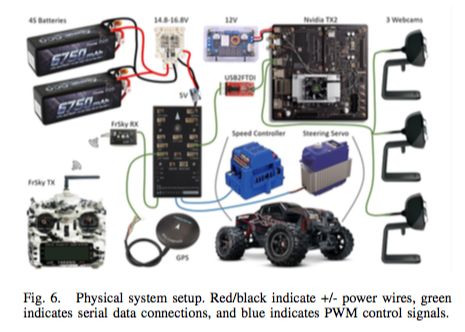
The setup of the physical system is shown in Figure 6. We equipped an off-the-shelf 1/5 scale truck (Traxxas Maxx) with an embedded computer (Nvidia TX2), three low-cost webcams, a flight controller (Holybro Pixhawk) running the APMRover firmware, and supporting electronics. The TX2 acquires images from the webcams and shares a bidirectional communication channel with the Pixhawk. The Pixhawk receives controls from either the TX2 or a human driver and converts them to low-level PWM signals for the speed controller and steering servo of the truck.
https://github.com/carla-simulator/carla/issues/112 carla vs airsim;





