【导读】计算机视觉顶会CVPR 2020在不久前公布了论文接收列表。本届CVPR共收到了6656篇有效投稿,接收1470篇,其接受率在逐年下降,今年接受率仅为22%。近期,一些Paper放出来,Domain Adaptation(域自适应)相关研究非常火热,特别是基于Domain Adaptation的视觉应用在今年的CVPR中有不少,专知小编整理了CVPR 2020 域自适应(DA)相关的比较有意思的值得阅读的六篇论文,供大家参考—行为分割、语义分割、目标检测、行为识别、域自适应检索。
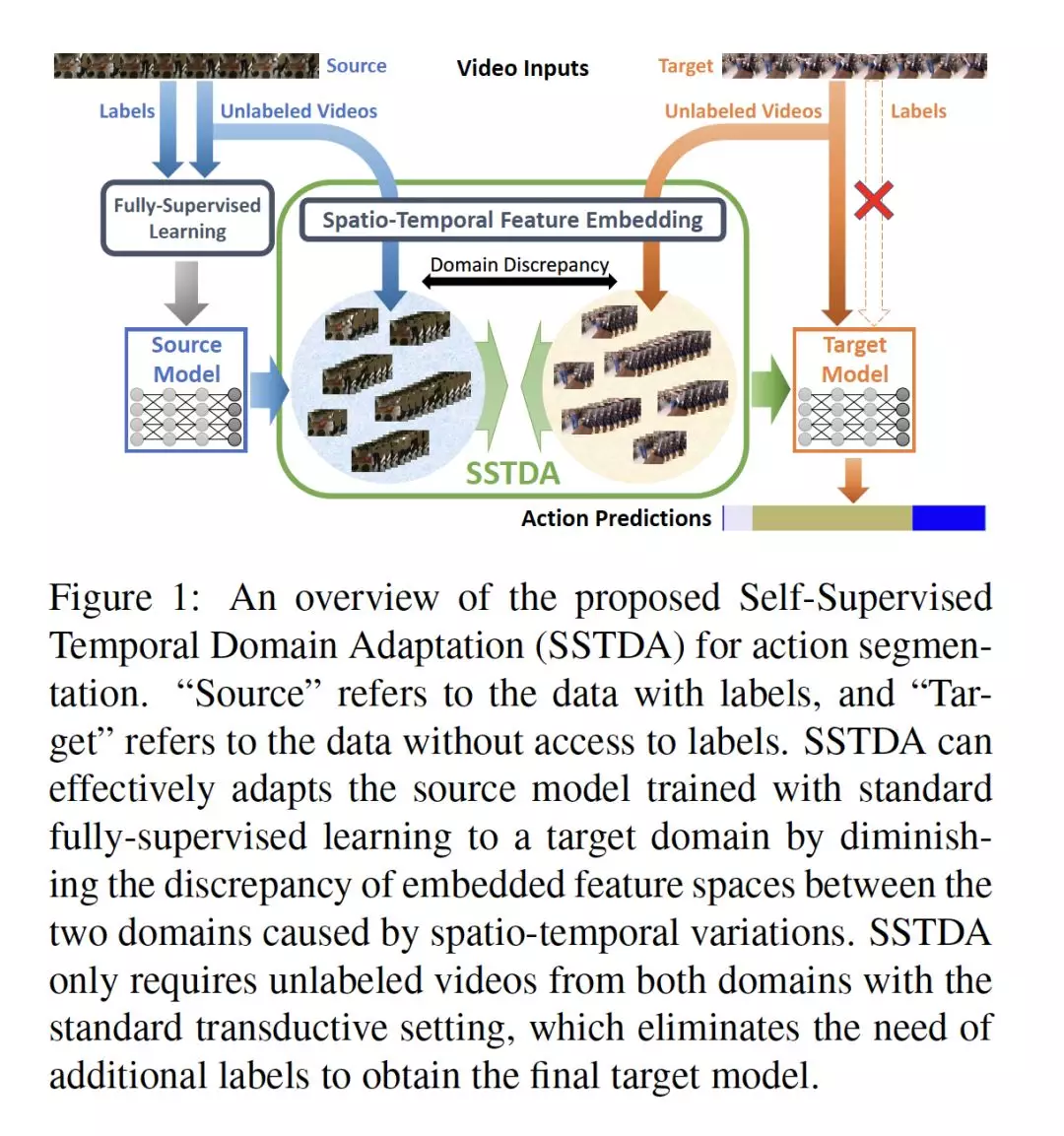
- Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
作者:Min-Hung Chen, Baopu Li, Yingze Bao, Ghassan AlRegib, Zsolt Kira
摘要:尽管最近在全监督行为分割(action segmentation)技术方面取得了一些进展,但性能仍然不尽如人意。一个主要挑战是时空变化问题(例如,不同的人可能以不同的方式进行相同的活动)。因此,我们利用无标签视频将行为分割任务重新表述为一个具有时空变化引起的域差异的跨域问题来解决上述时空变化问题。为了减少这种域差异,我们提出了自监督时域自适应(SSTDA),它包含两个自监督辅助任务(二进制和序列域预测)来联合对齐嵌入局部和全局时间动态的跨域特征空间,取得了比其他域自适应(DA)方法更好的性能。在三个具有挑战性的基准数据集(GTEA、50Salads和Breakfast)上,SSTDA的表现远远超过当前最先进的方法(在Breakfas上F1@25得分从59.6%到69.1%,在50Salads上F1@25得分从73.4%到81.5%,在GTEA上F1@25得分从83.6%到89.1%),并且只需要65%的标记训练数据来就实现了该性能,这表明了SSTDA在各种变化中适应未标记目标视频的有效性。
网址:https://arxiv.org/abs/2003.02824
代码链接:https://github.com/cmhungsteve/SSTDA
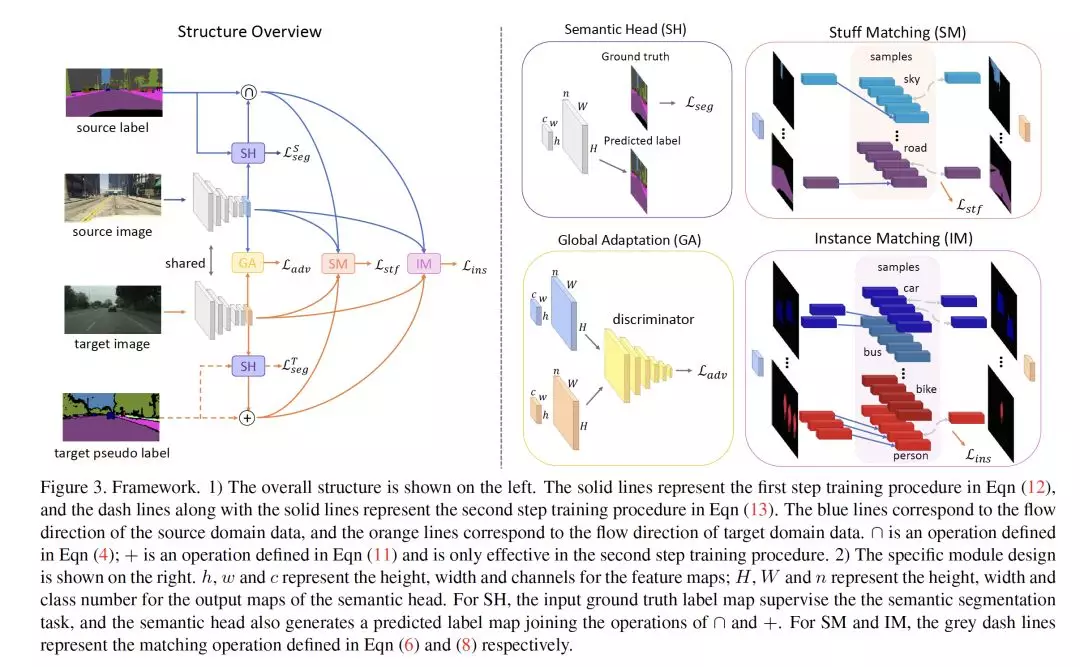
- Differential Treatment for Stuff and Things:A Simple Unsupervised Domain Adaptation Method for Semantic Segmentation
作者:Zhonghao Wang, Mo Yu, Yunchao Wei, Rogerior Feris, Jinjun Xiong, Wen-mei Hwu, Thomas S. Huang, Honghui Shi
摘要:本文通过缓解源域(合成数据)和目标域(真实数据)之间的域转换(domain shift),研究语义分割中的无监督域自适应问题。之前的方法证明,执行语义级对齐有助于解决域转换问题。我们观察到事物类别通常在不同域的图像之间具有相似的外观,而事物(即目标实例)具有更大的差异,我们提出使用针对填充(stuff)区域和事物的不同策略来改进语义级别的对齐方式:1)对于填充类别,我们为每一类生成特征表示,并进行从目标域到源域的对齐操作;2)对于事物(thing)类别,我们为每个单独的实例生成特征表示,并鼓励目标域中的实例与源域中最相似的实例对齐。以这种方式,事物类别内的个体差异也将被考虑,以减轻过度校准。除了我们提出的方法之外,我们还进一步揭示了当前对抗损失在最小化分布差异方面经常不稳定的原因,并表明我们的方法可以通过最小化源域和目标域之间最相似的内容和实例特征来帮助缓解这个问题。
网址:https://arxiv.org/abs/2003.08040
- Exploring Categorical Regularization for Domain Adaptive Object Detection
作者:Chang-Dong Xu, Xing-Ran Zhao, Xin Jin, Xiu-Shen Wei
摘要:在本文中,我们解决了域自适应目标检测问题,其中的主要挑战在于源域和目标域之间存在明显的域差距。以前的工作试图明确地对齐图像级和实例级的移位,以最小化域差异。然而,它们仍然忽略了去匹配关键图像区域和重要的跨域实例,这将严重影响域偏移缓解。在这项工作中,我们提出了一个简单有效的分类正则化框架来缓解这个问题。它可以作为一个即插即用(plug-and-play)组件应用于一系列域自适应Faster R-CNN方法,这些方法在处理域自适应检测方面表现突出。具体地说,由于分类方式的定位能力较弱,通过在检测主干上集成图像级多标签分类器,可以获得与分类信息相对应的稀疏但关键的图像区域。同时,在实例级,我们利用图像级预测(分类器)和实例级预测(检测头)之间的分类一致性作为正则化因子,自动寻找目标域的硬对齐实例。各种域转移场景的大量实验表明,与原有的域自适应Faster R-CNN检测器相比,我们的方法获得了显着的性能提升。此外,定性的可视化和分析可以证明我们的方法能够关注针对领域适配的关键区域/实例。
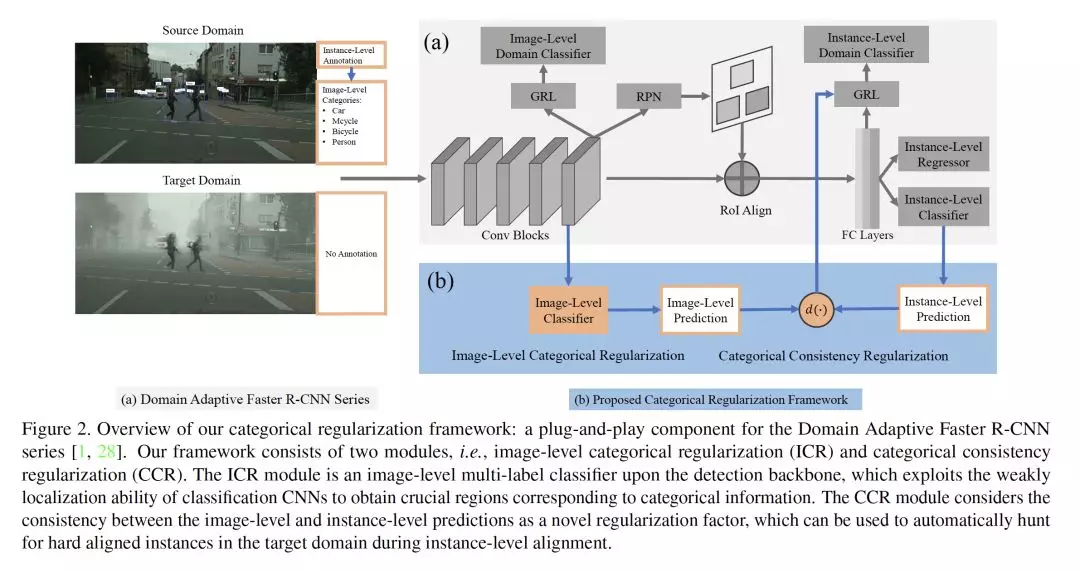
网址:https://arxiv.org/abs/2003.09152
代码链接:https://github.com/Megvii-Nanjing/CR-DA-DET
- Multi-Modal Domain Adaptation for Fine-Grained Action Recognition
作者:Jonathan Munro, Dima Damen
摘要:细粒度行为识别数据集存在出环境偏差,多个视频序列是从有限数量的环境中捕获的。在一个环境中训练模型并在另一个环境中部署会由于不可避免的域转换而导致性能下降。无监督域适应(UDA)方法经常利用源域和目标域之间进行对抗性训练。然而,这些方法并没有探索视频在每个域中的多模式特性。在这项工作中,除了对抗性校准之外,我们还利用模态之间的对应关系作为UDA的一种自监督校准方法。
我们在大规模数据集EPIC-Kitchens中的三个kitchens上使用行为识别的两种模式:RGB和光学流(Optical Flow)测试了我们的方法。结果显示,仅多模态自监督比仅进行源训练的性能平均提高了2.4%。然后,我们将对抗训练与多模态自监督相结合,表明我们的方法比其他UDA方法要好3%。
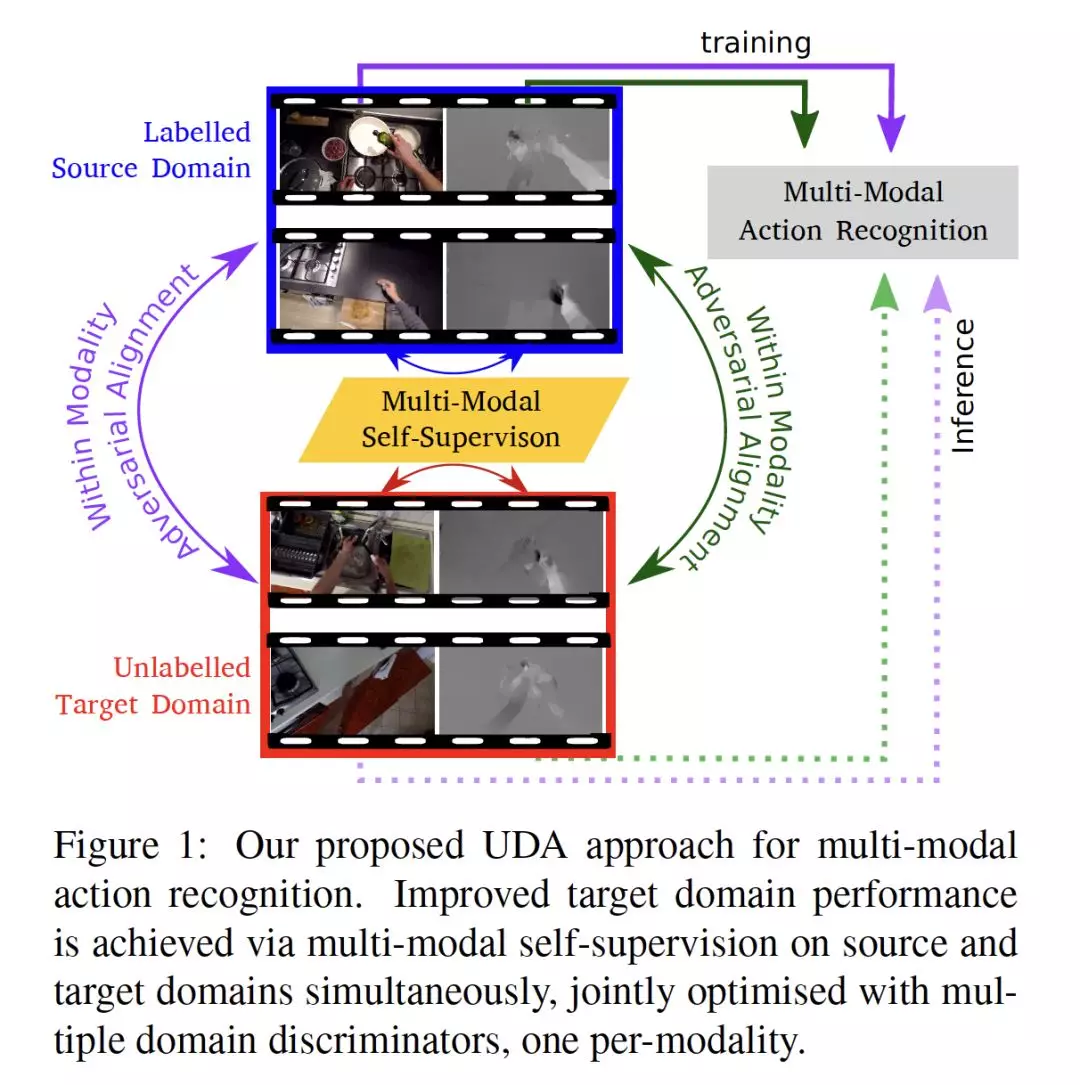
网址:https://arxiv.org/abs/2001.09691
- Learning Texture Invariant Representation for Domain Adaptation of Semantic Segmentation
作者:Myeongjin Kim, Hyeran Byun
摘要:由于用于语义分割的像素级标签标注很费力,因此利用合成数据是一种更好的解决方案。然而,由于合成域和实域之间存在领域鸿沟,用合成数据训练的模型很难推广到真实数据。本文将这两个领域之间的根本差异作为纹理,提出了一种自适应目标域纹理的方法。首先,我们使用样式转移算法使合成图像的纹理多样化。合成图像的各种纹理防止分割模型过拟合到一个特定(合成)纹理。然后,通过自训练对模型进行微调,得到对目标纹理的直接监督。我们的结果达到了最先进的性能,并通过大量的实验分析了在多样化数据集上训练的模型的性质。
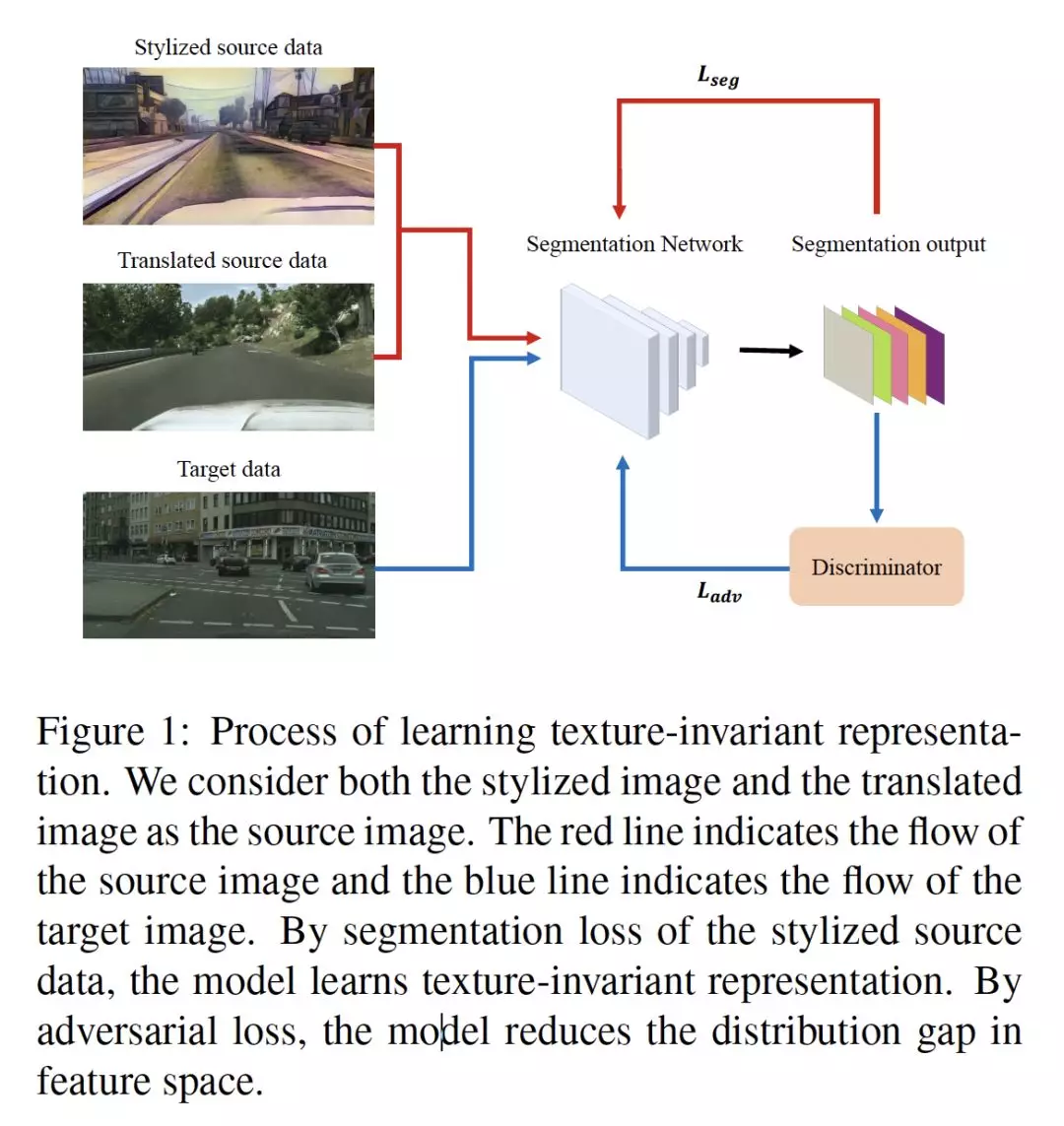
网址:https://arxiv.org/abs/2003.00867
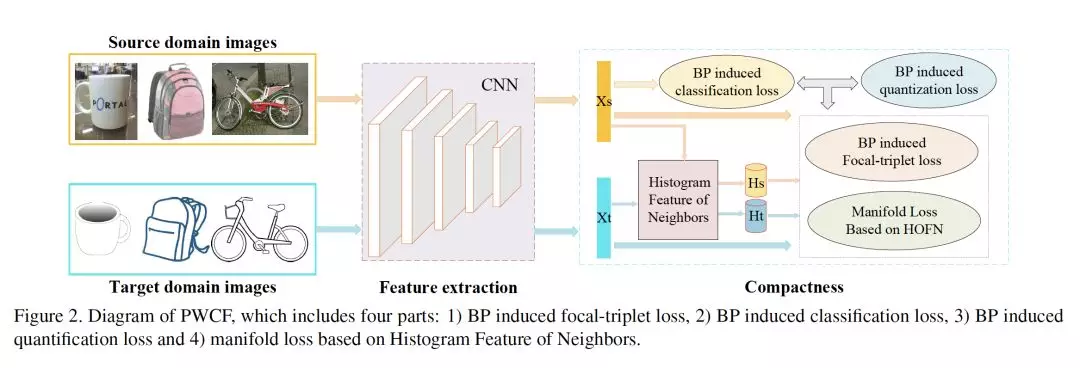
- Probability Weighted Compact Feature for Domain Adaptive Retrieval
作者:Fuxiang Huang, Lei Zhang, Yang Yang, Xichuan Zhou
摘要:域自适应图像检索包括单域检索和跨域检索。现有的图像检索方法大多只关注单个域的检索,假设检索数据库和查询的分布是相似的。然而,在实际应用中,通常在理想光照/姿态/背景/摄像机条件下获取的检索数据库与在非受控条件下获得的查询之间的差异很大。本文从实际应用的角度出发,重点研究跨域检索的挑战性问题。针对这一问题,我们提出了一种有效的概率加权紧凑特征学习(PWCF)方法,它提供域间相关性指导以提高跨域检索的精度,并学习一系列紧凑二进制码(compact binary codes)来提高检索速度。首先,我们通过最大后验估计(MAP)推导出我们的损失函数:贝叶斯(BP)诱发的focal-triplet损失、BP诱发的quantization损失和BP诱发的分类损失。其次,我们提出了一个通用的域间复合结构来探索域间的潜在相关性。考虑到原始特征表示因域间差异而存在偏差,复合结构难以构造。因此,我们从样本统计的角度提出了一种新的特征—邻域直方图特征(HFON)。在不同的基准数据库上进行了大量的实验,验证了我们的方法在领域自适应图像检索中的性能优于许多最先进的图像检索方法。