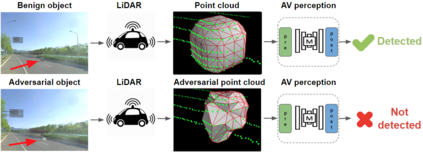
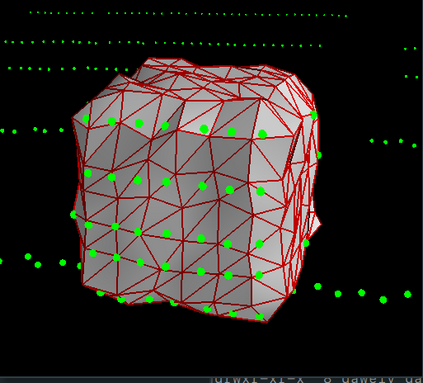
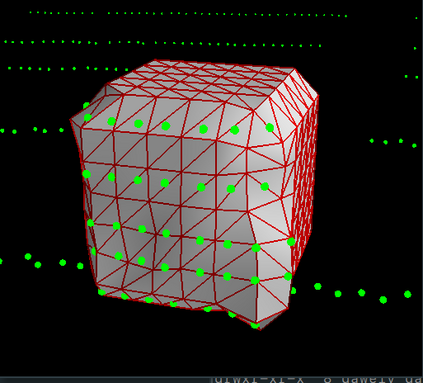
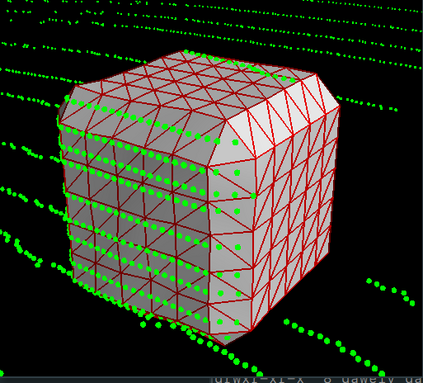
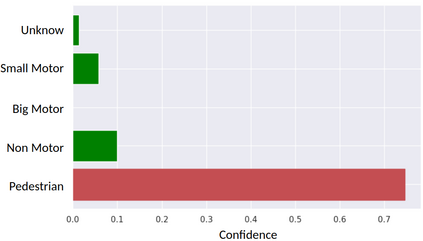
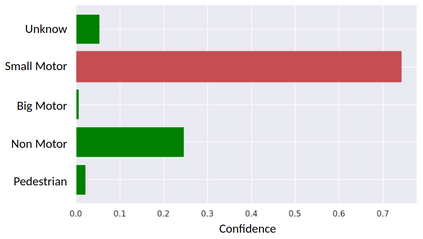
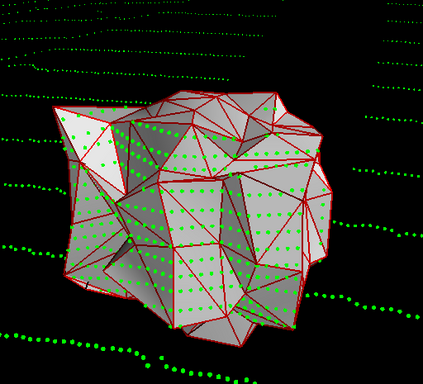
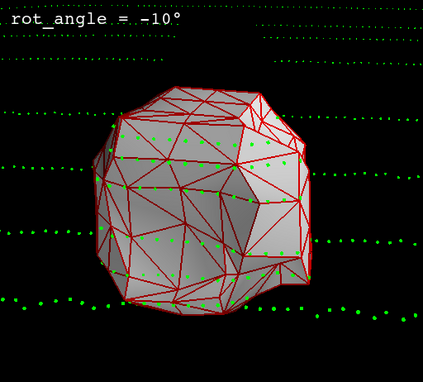
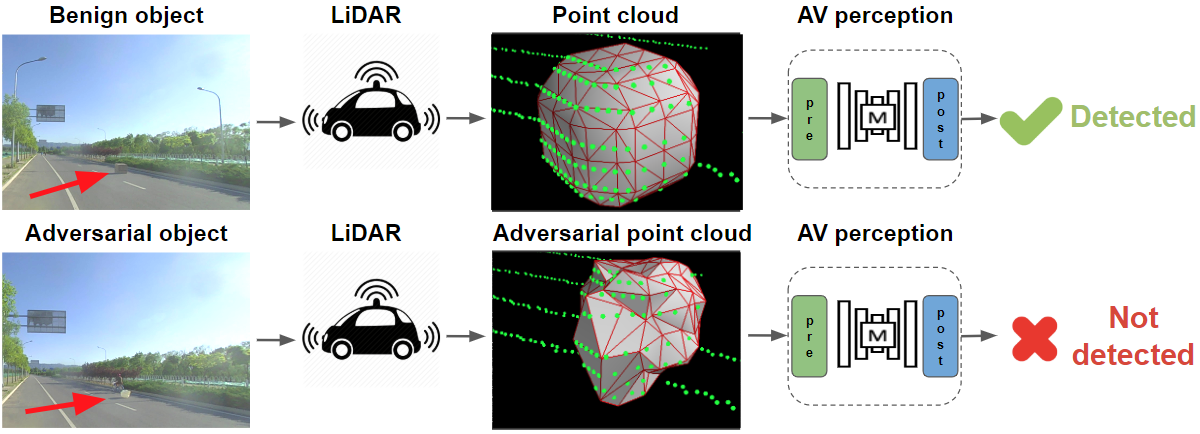
Deep neural networks (DNNs) are found to be vulnerable against adversarial examples, which are carefully crafted inputs with a small magnitude of perturbation aiming to induce arbitrarily incorrect predictions. Recent studies show that adversarial examples can pose a threat to real-world security-critical applications: a "physical adversarial Stop Sign" can be synthesized such that the autonomous driving cars will misrecognize it as others (e.g., a speed limit sign). However, these image-space adversarial examples cannot easily alter 3D scans of widely equipped LiDAR or radar on autonomous vehicles. In this paper, we reveal the potential vulnerabilities of LiDAR-based autonomous driving detection systems, by proposing an optimization based approach LiDAR-Adv to generate adversarial objects that can evade the LiDAR-based detection system under various conditions. We first show the vulnerabilities using a blackbox evolution-based algorithm, and then explore how much a strong adversary can do, using our gradient-based approach LiDAR-Adv. We test the generated adversarial objects on the Baidu Apollo autonomous driving platform and show that such physical systems are indeed vulnerable to the proposed attacks. We also 3D-print our adversarial objects and perform physical experiments to illustrate that such vulnerability exists in the real world. Please find more visualizations and results on the anonymous website: https://sites.google.com/view/lidar-adv.
翻译:深心神经网络(DNNS)被认为易受对抗性例子的伤害,这些图像-空间对抗性例子是精心设计的,其输入是精心设计的,其扰动程度小,目的是引起任意错误的预测。最近的研究表明,对抗性例子可能对现实世界的安全关键应用构成威胁:可以合成一个“物理对抗性停止信号”,这样自动驾驶汽车就会误认它为其他人(例如,一个速度限制信号) 。然而,这些图像-空间对抗性例子无法轻易地改变广泛装备的LIDAR或自动车辆雷达的3D扫描。在本文中,我们揭示了基于LIDAR的自动驾驶探测系统的潜在弱点,为此我们提议了一种基于优化的方法,即LIDAR-Adv生成对抗性物体,以便在各种条件下生成能够避开以LIDAR为基础的探测系统的对抗性物体。我们首先用黑盒进化算法来显示其弱点,然后探索强大的对手能做些什么,利用我们的基于梯度的方法LIDAR-Adv 。我们在Baiddu Alicom自动驾驶平台上测试产生的对抗性物体,并显示这种物理实验系统确实容易受到攻击。