斯坦福大学Fall 2018课程-机器学习硬件加速器( 附PPT下载)
【导读】斯坦福大学2018秋季学期推出《机器学习硬件加速器》课程,介绍机器学习系统中的硬件加速器训练和推理的架构技术,系统而又前沿,是该领域不可多得的课程值得一看。
课程简介
本课程将深入介绍在机器学习系统中用于设计训练和推理加速器的架构技术。本课程将涵盖经典的ML算法,如线性回归和支持向量机,以及DNN模型,如卷积神经网络和递归神经网络。我们将考虑对这些模型的训练和推断,并讨论批量大小、精度、稀疏性和压缩等参数对这些模型精度的影响。我们将介绍ML模型推理和训练的加速器设计。学生将熟悉使用并行性、局部性和低精度来实现ML中使用的核心计算内核的硬件实现技术。为了设计高效节能的加速器,学生们将建立直觉,在ML模型参数和硬件实现技术之间进行权衡。学生将阅读最近的研究论文并完成一个设计项目。
课程地址:
https://cs217.github.io/
教师介绍

Kunle Olukotun 教授:
http://arsenalfc.stanford.edu/kunle
ARDAVAN PEDRAM
https://web.stanford.edu/~perdavan/
课程内容安排
客座讲师

课程相关内容Slides
Lecture01: Deep Learning Challenge. Is There Theory? (Donoho/Monajemi/Papyan)
https://cs217.github.io/assets/lectures/StanfordStats385-20170927-Lecture01-Donoho.pdf
Lecture02: Overview of Deep Learning From a Practical Point of View (Donoho/Monajemi/Papyan)
https://cs217.github.io/assets/lectures/Lecture-02-AsCorrected.pdf
Lecture03: Harmonic Analysis of Deep Convolutional Neural Networks (Helmut Bolcskei)
https://cs217.github.io/assets/lectures/bolcskei-stats385-slides.pdf
Lecture04: Convnets from First Principles: Generative Models, Dynamic Programming & EM (Ankit Patel)
https://cs217.github.io/assets/lectures/2017%20Stanford%20Guest%20Lecture%20-%20Stats%20385%20-%20Oct%202017.pdf
Lecture05: When Can Deep Networks Avoid the Curse of Dimensionality and Other Theoretical Puzzles (Tomaso Poggio)
https://cs217.github.io/assets/lectures/StanfordStats385-20171025-Lecture05-Poggio.pdf
Lecture06: Views of Deep Networksfrom Reproducing Kernel Hilbert Spaces (Zaid Harchaoui)
https://cs217.github.io/assets/lectures/lecture6_stats385_stanford_nov17.pdf
Lecture07: Understanding and Improving Deep Learning With Random Matrix Theory (Jeffrey Pennington)
https://cs217.github.io/assets/lectures/Understanding_and_improving_deep_learing_with_random_matrix_theory.pdf
Lecture08: Topology and Geometry of Half-Rectified Network Optimization (Joan Bruna)
https://cs217.github.io/assets/lectures/stanford_nov15.pdf
Lecture09: What’s Missing from Deep Learning? (Bruno Olshausen)
https://cs217.github.io/assets/lectures/lecture-09--20171129.pdf
Lecture10: Convolutional Neural Networks in View of Sparse Coding (Vardan Papyan)
https://cs217.github.io/assets/lectures/lecture-10--20171206.pdf
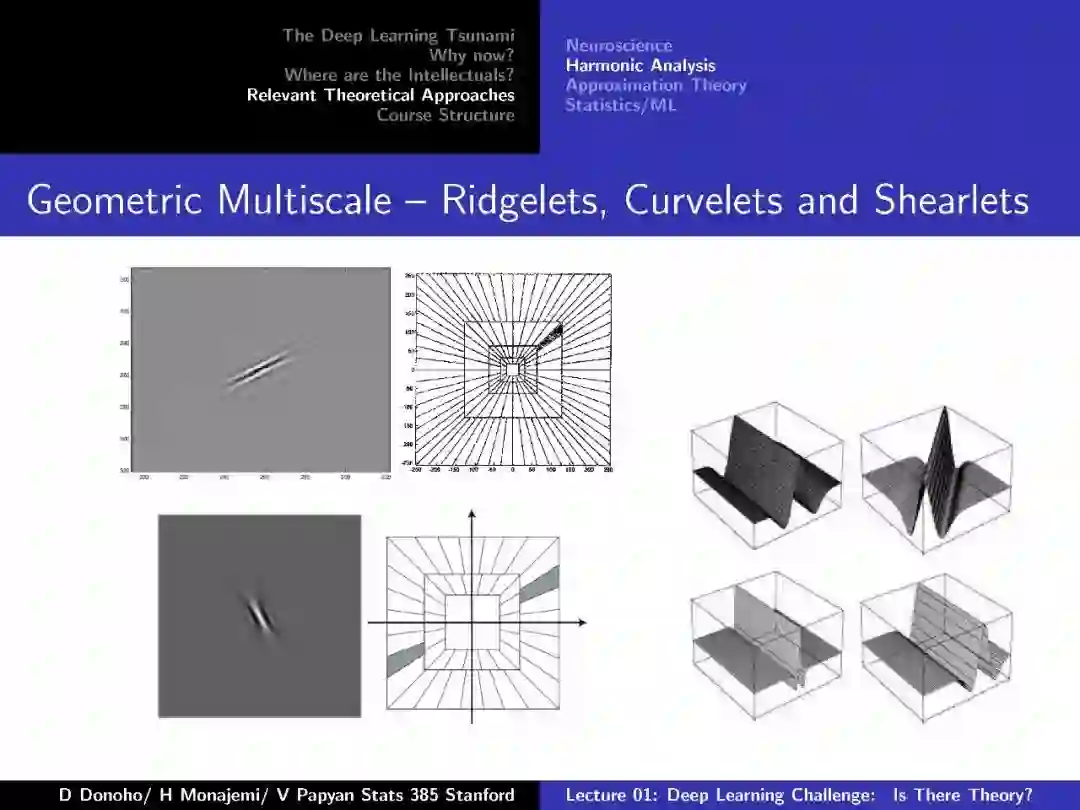
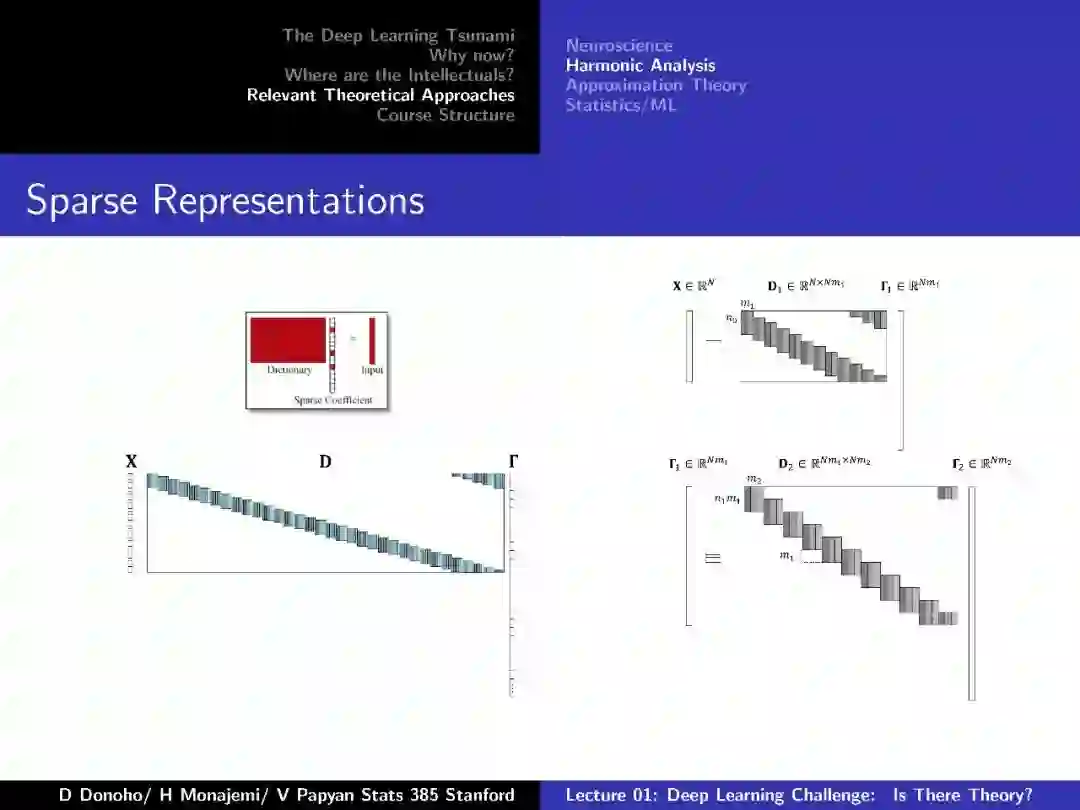
附:第一节 深度学习挑战:存在理论么



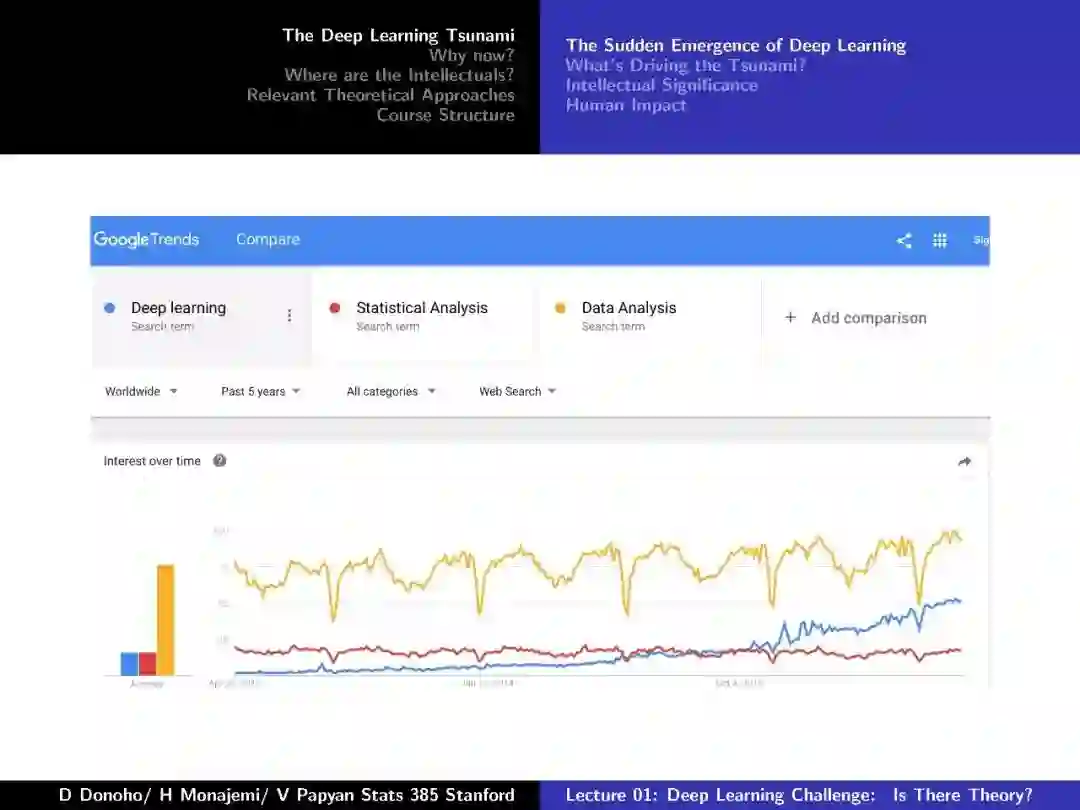
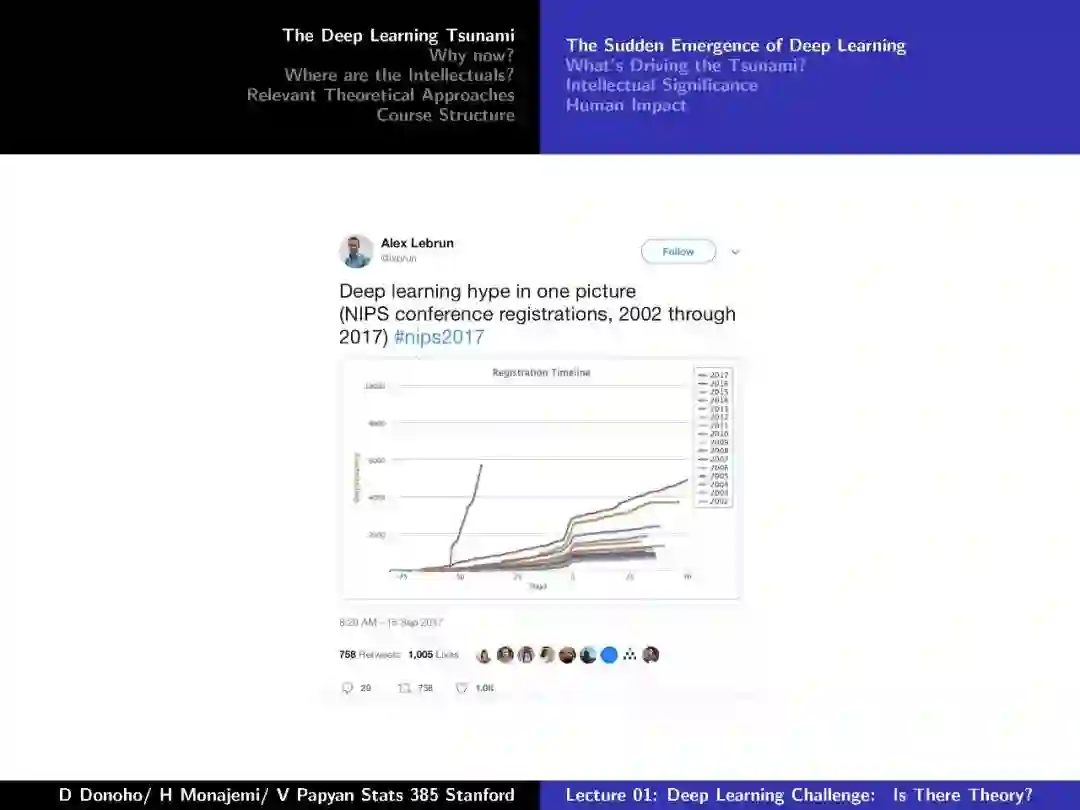
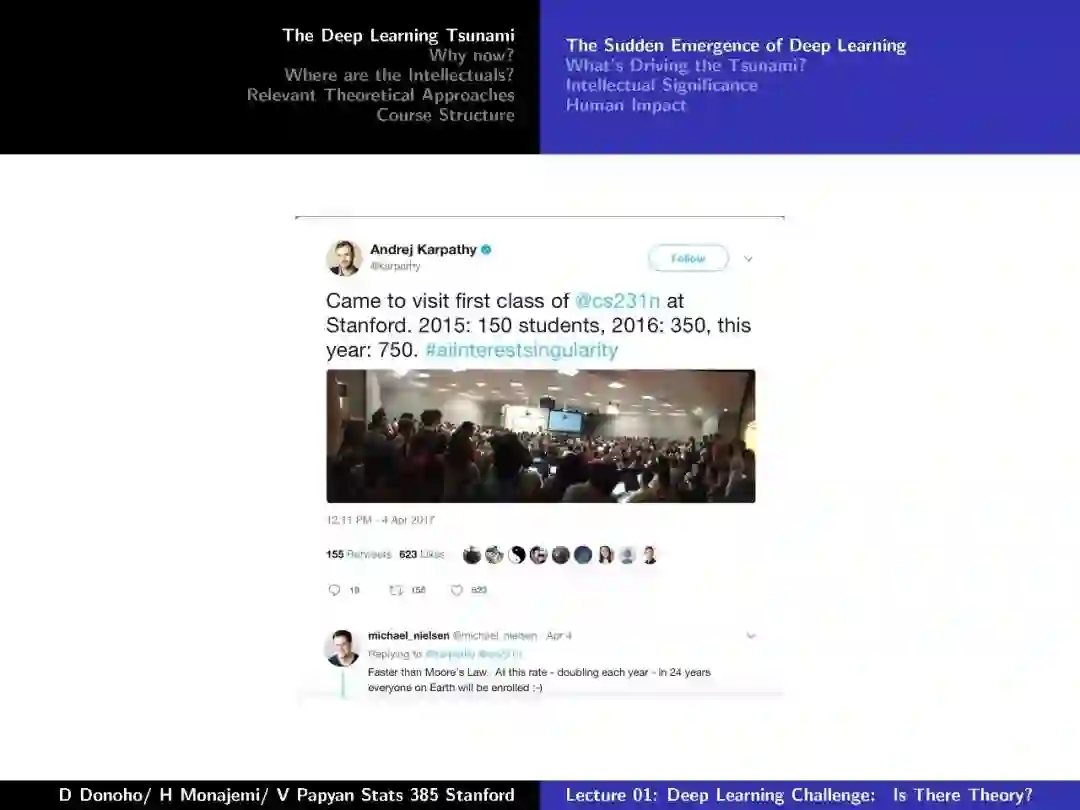



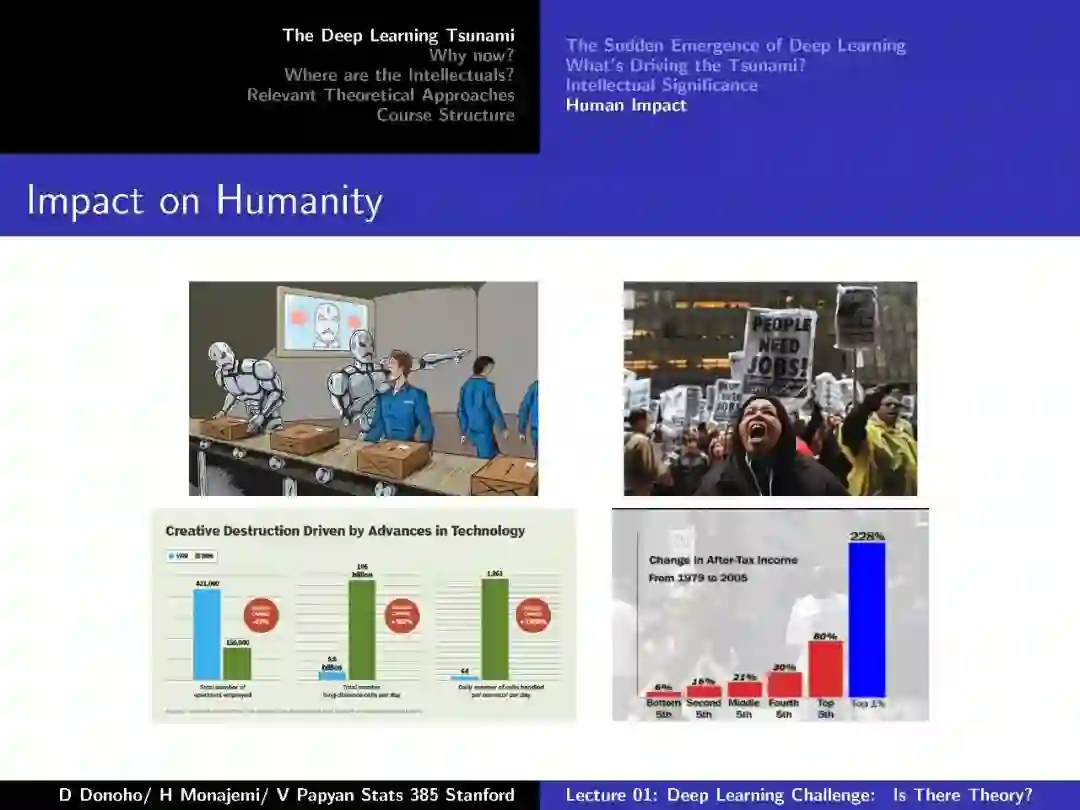


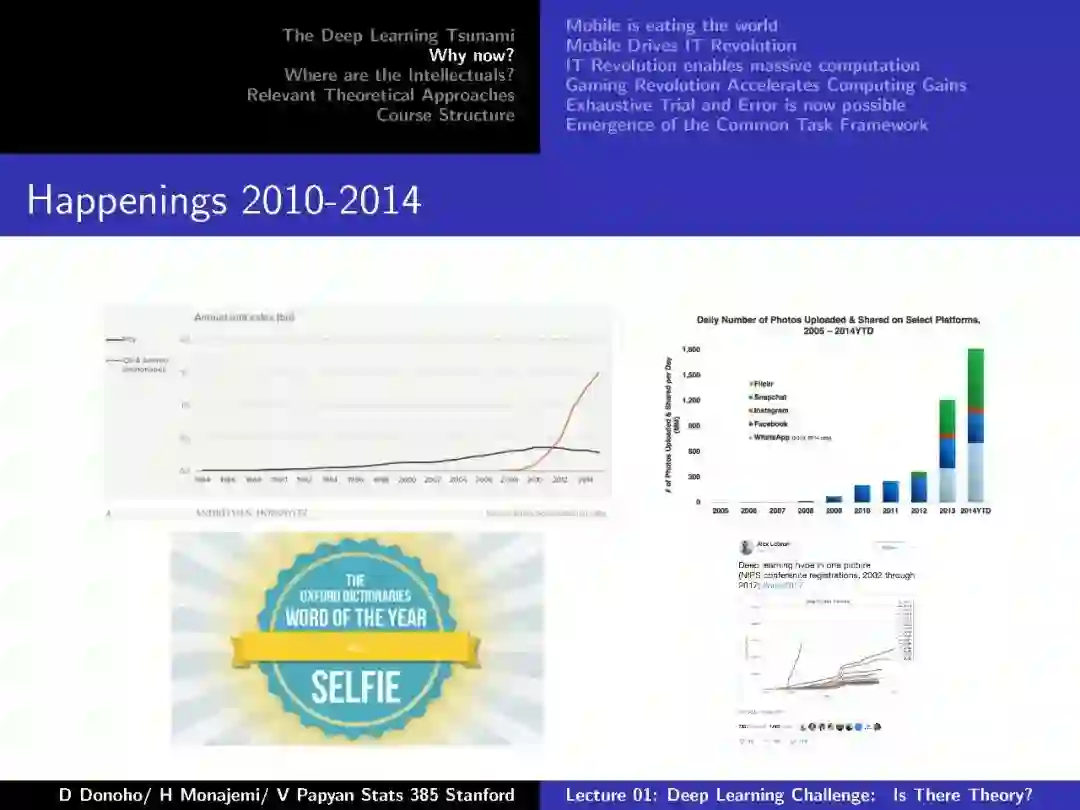
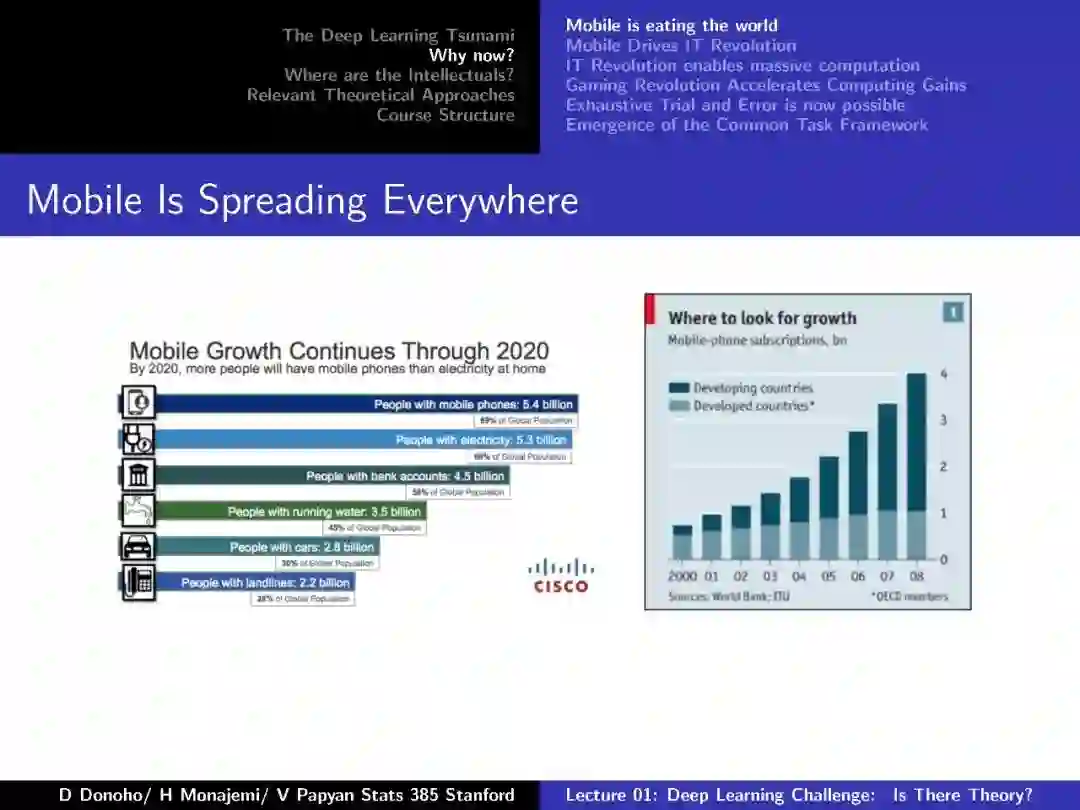
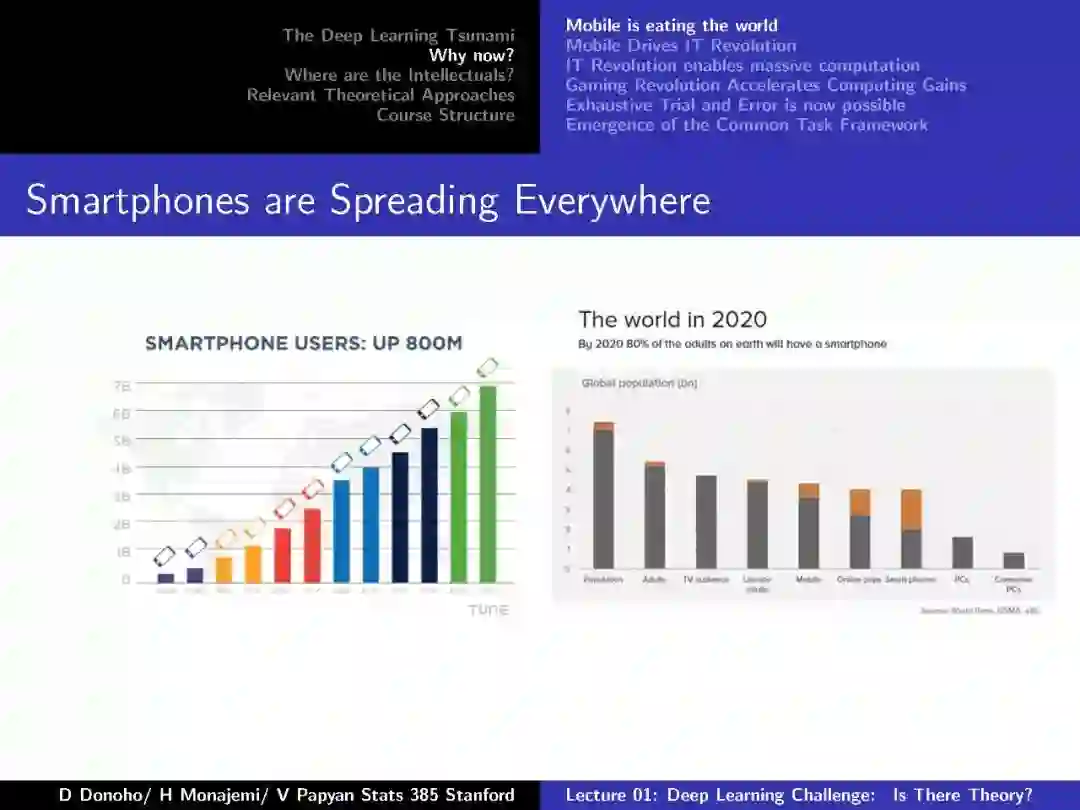
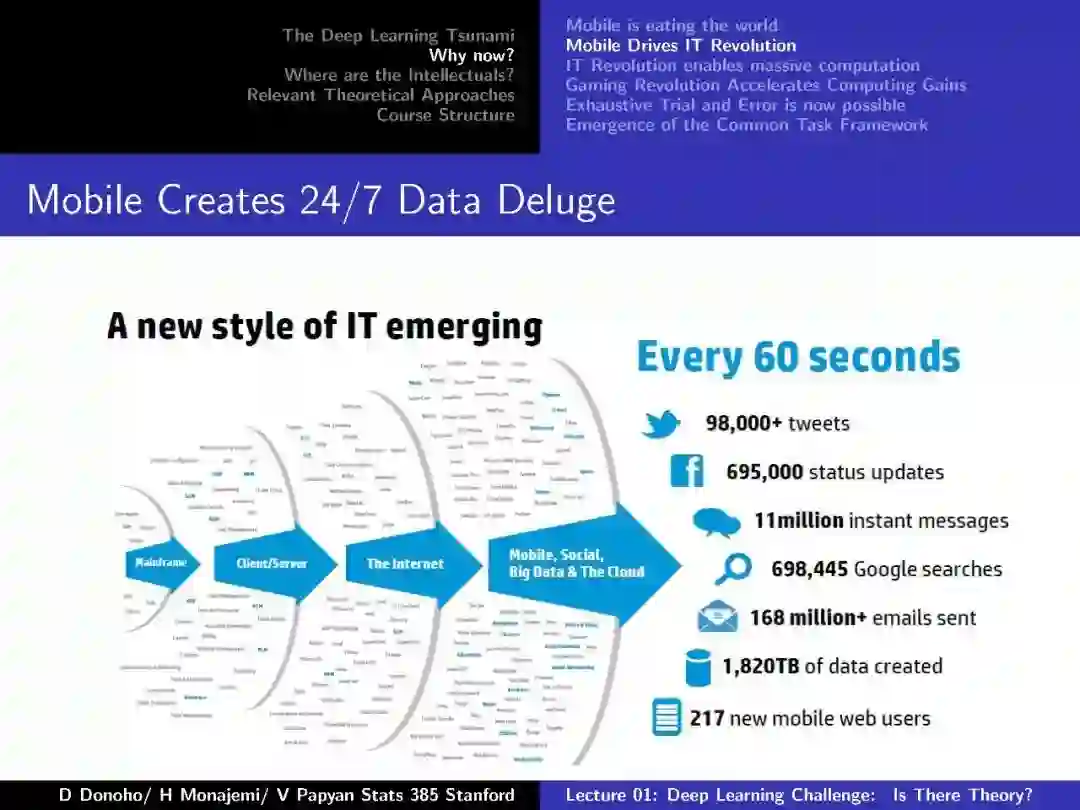

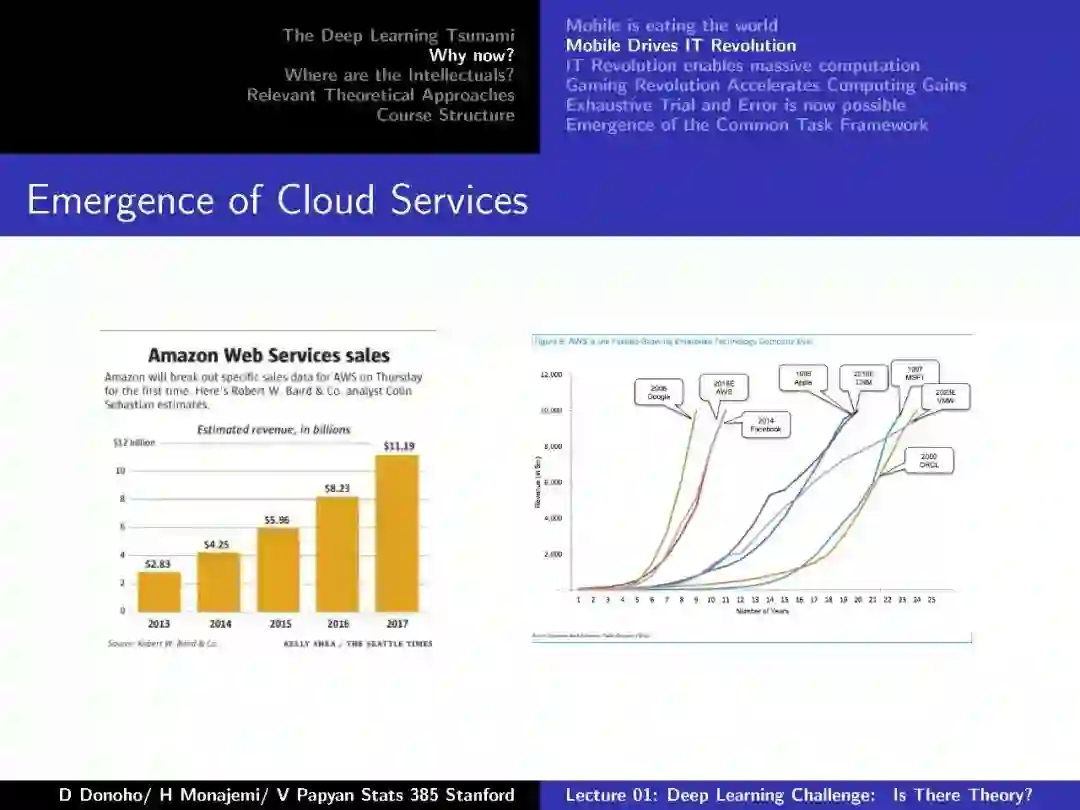

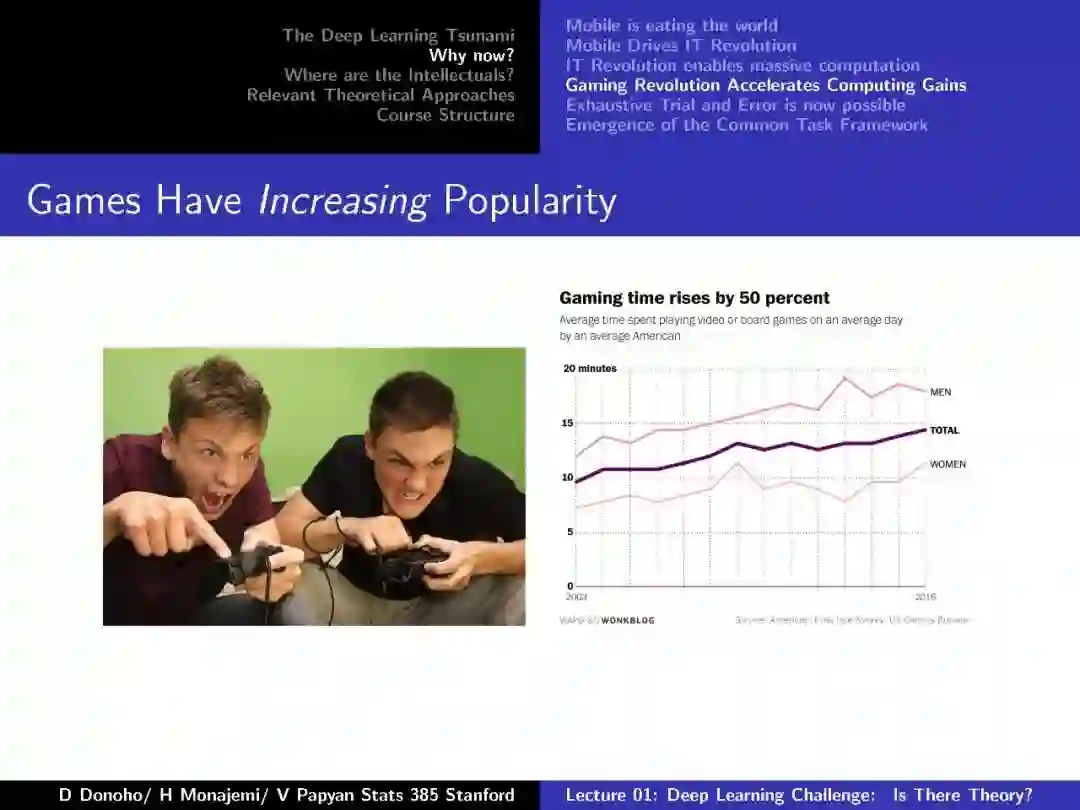

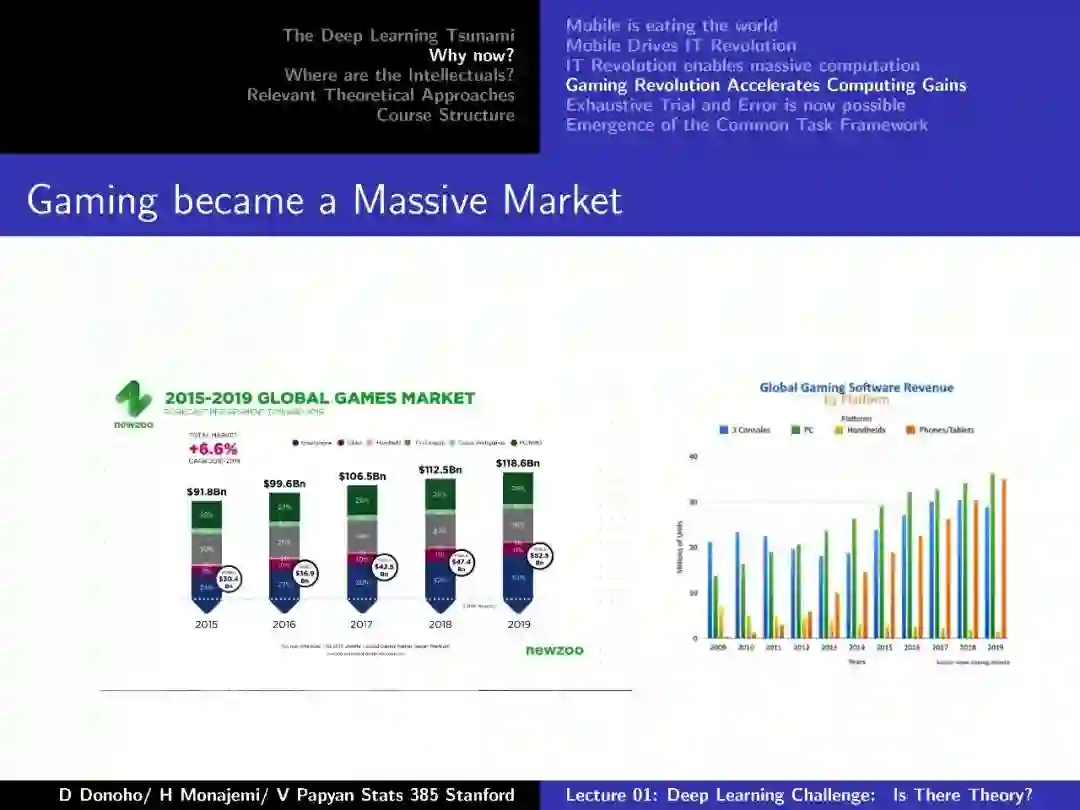
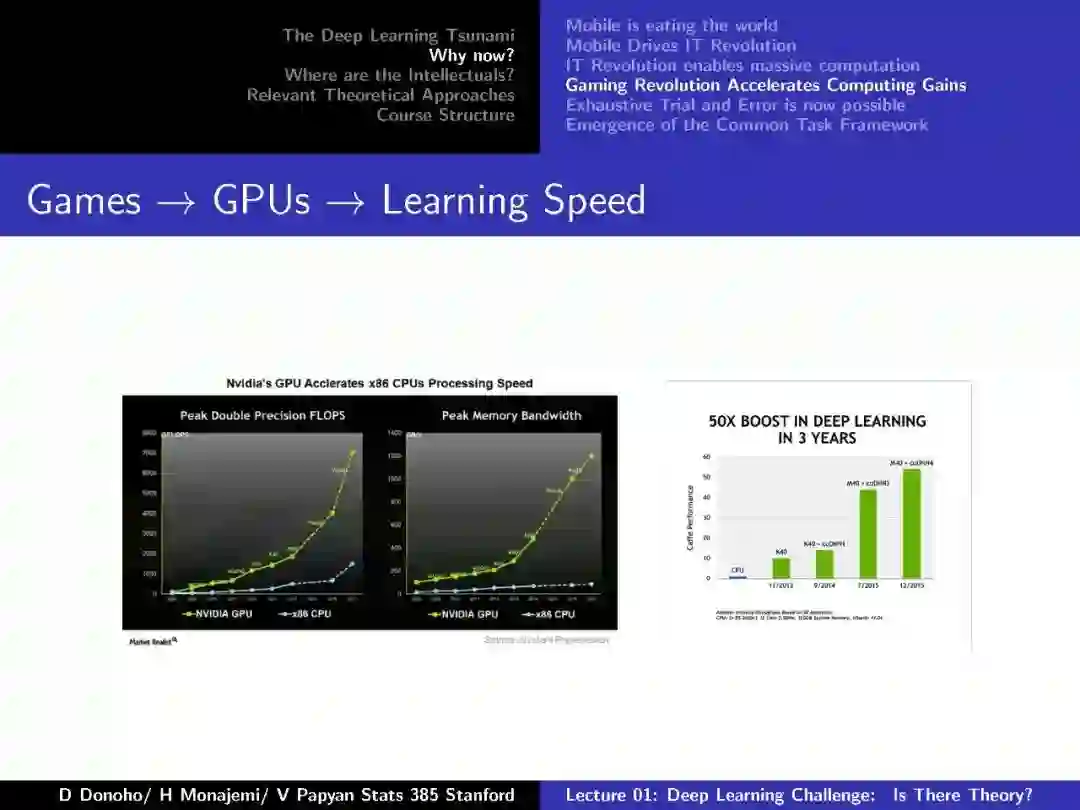


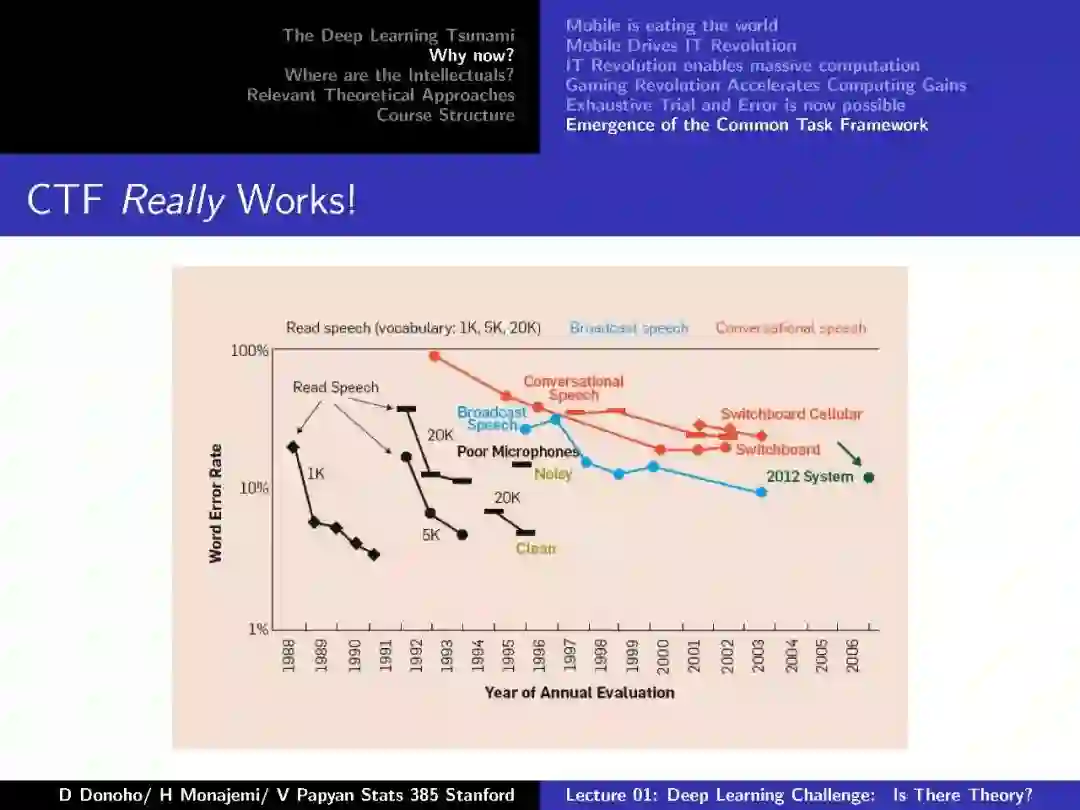



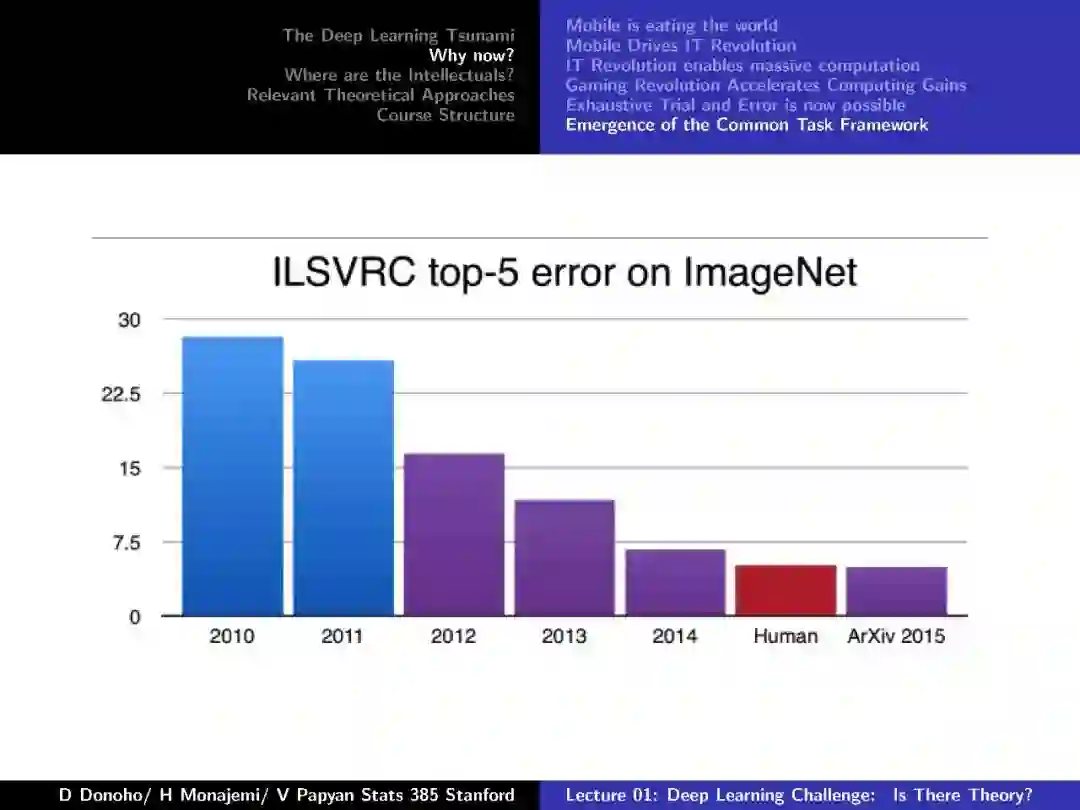



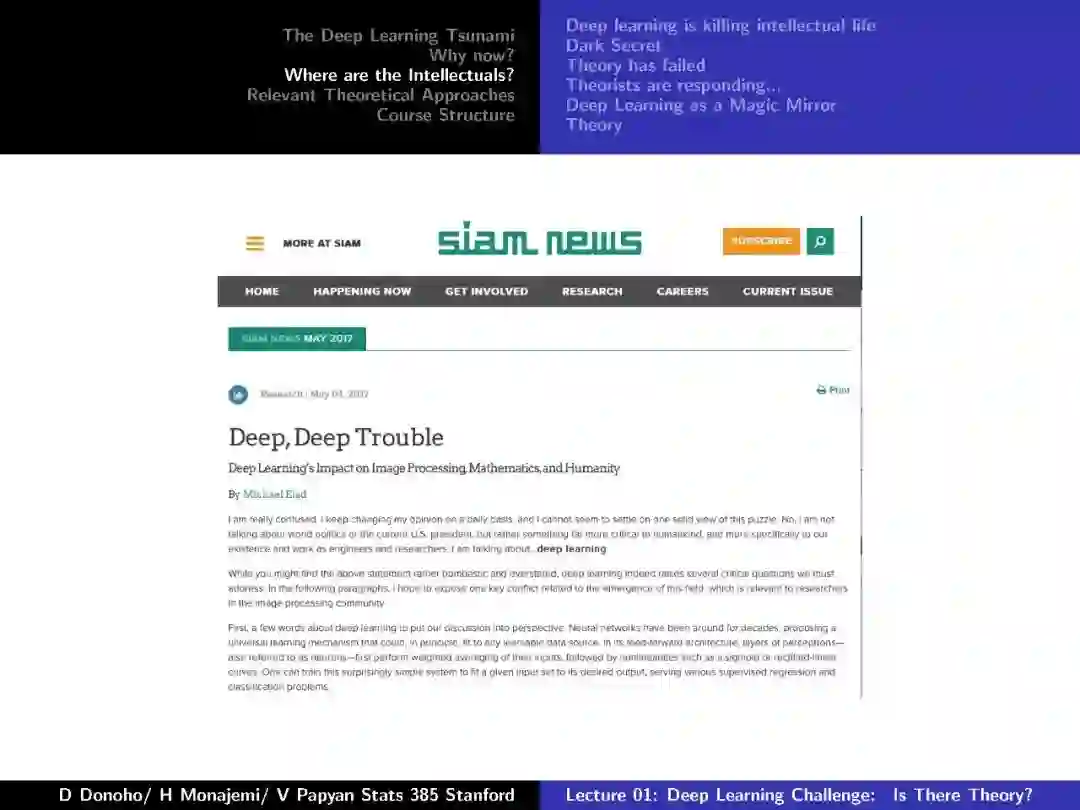
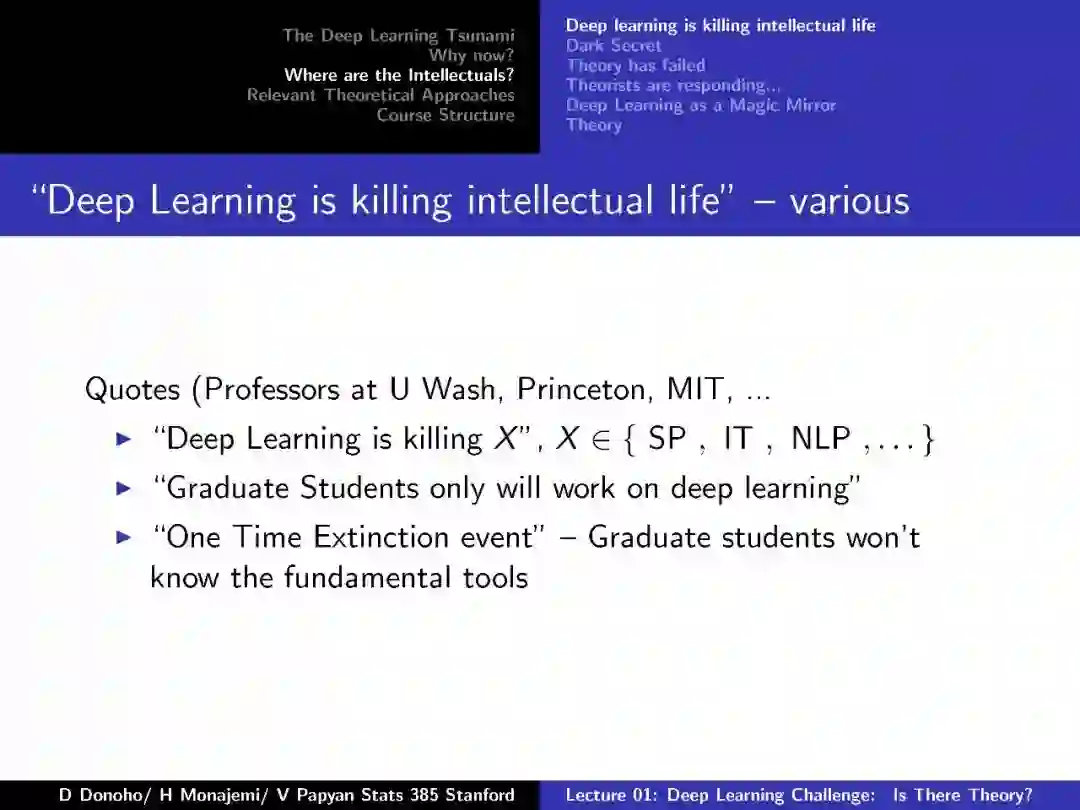
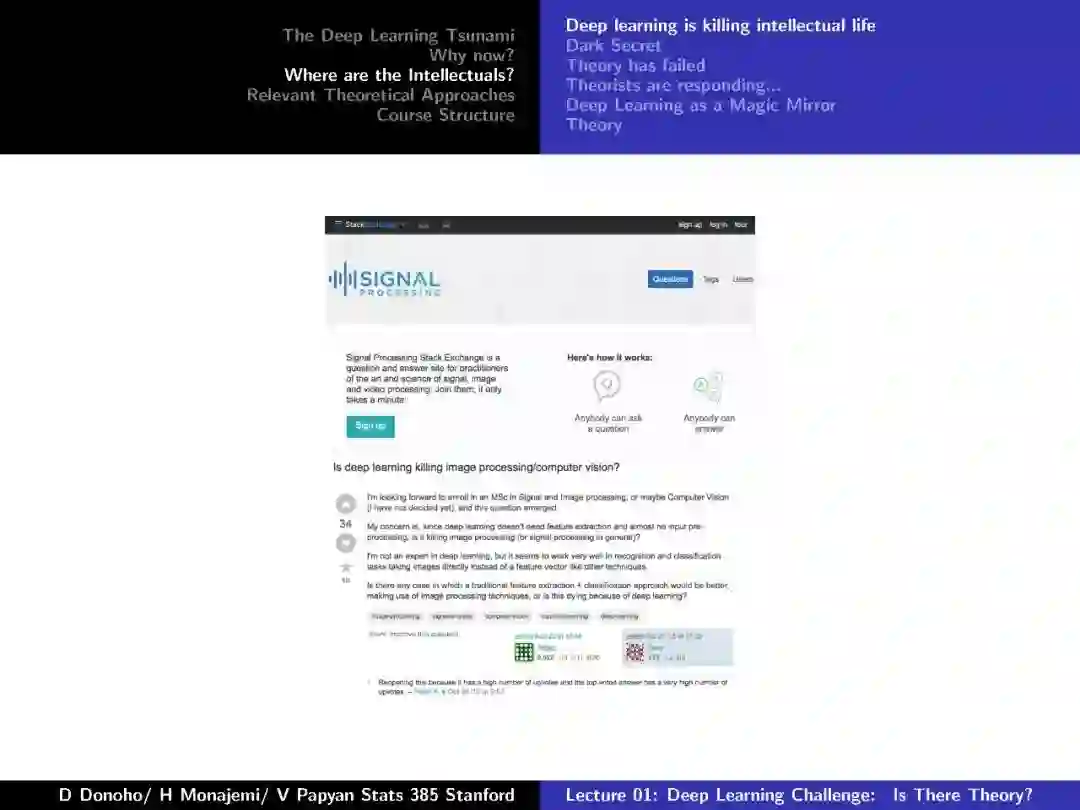





















-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知



