情感分析算法在阿里小蜜的应用实践


主要作者:宋双永 阿里达摩院 算法专家
编辑整理:Hoh
内容来源:作者授权
出品平台:DataFunTalk
注:欢迎转载,转载请留言。
01
智能客服系统中情感分析技术架构
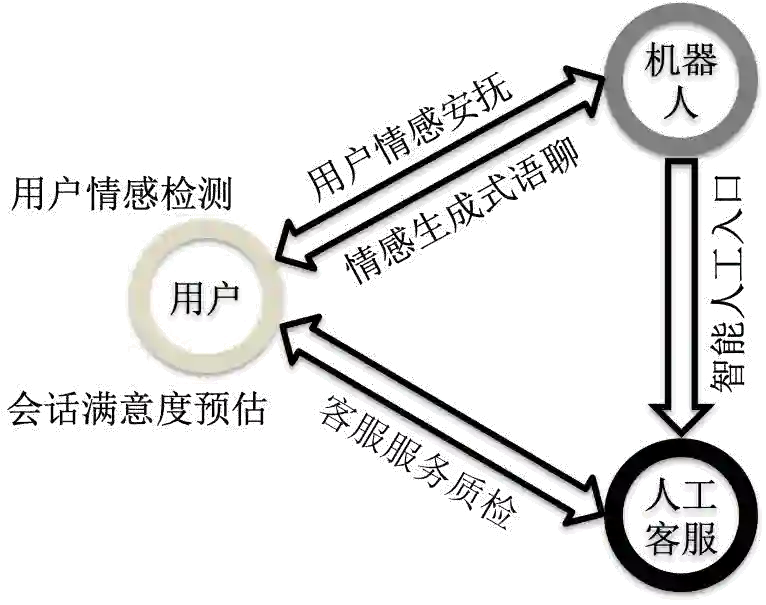
(a)
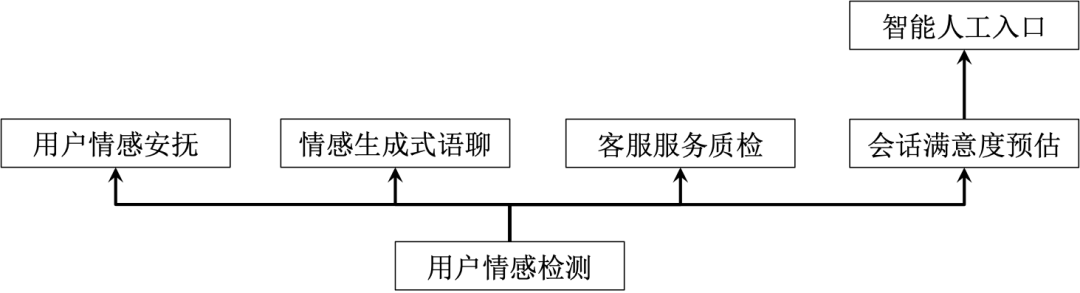
(b)
图1:智能客服系统中的情感分析技术架构
-
针对用户的每一句对话,我们会实时分析用户在对话中带有的情感类别,例如“着急”、“失望”和“气愤”等; -
在机器人为用户服务的过程中,针对用户带有情感的对话,机器人会有针对性的情感安抚能力; -
针对用户对话中所包含的情感,利用生成式模型自动生成与用户情感相对应情感的语聊回复内容; -
针对人工客服的服务过程,利用情感分析技术能够实现自动的客服服务质量检测,帮助及时发现客服服务的质量问题,加以提醒和纠正; -
在用户结束一整通与机器人的会话之后,会预估用户对整体会话的满意度; -
在机器人服务的过程中,会根据用户的状态变化判断是否开启智能人工入口。
02
用户情感检测


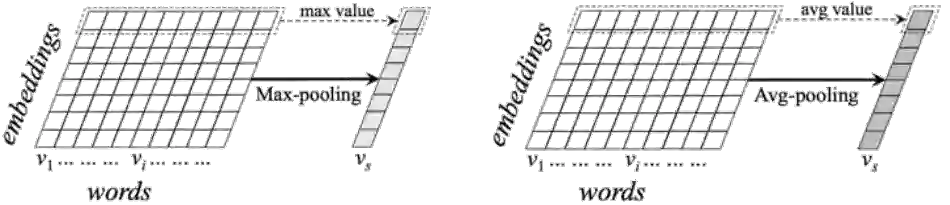
图4:SWEM模型中的最大值池化和平均值池化
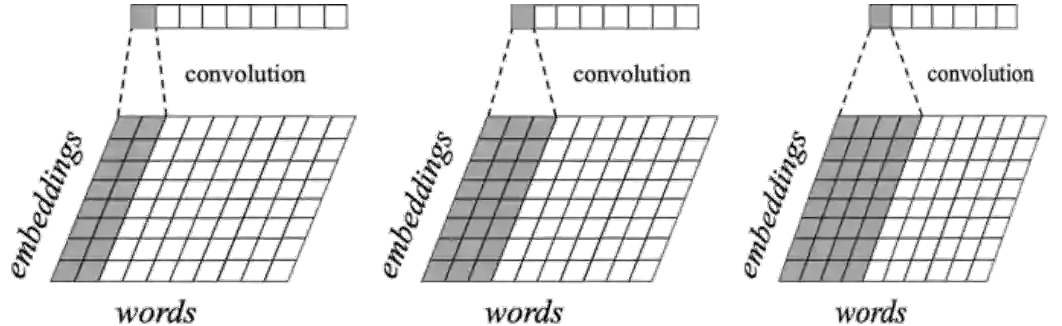
图5:基于卷积的二元、三元和四元语义特征抽取
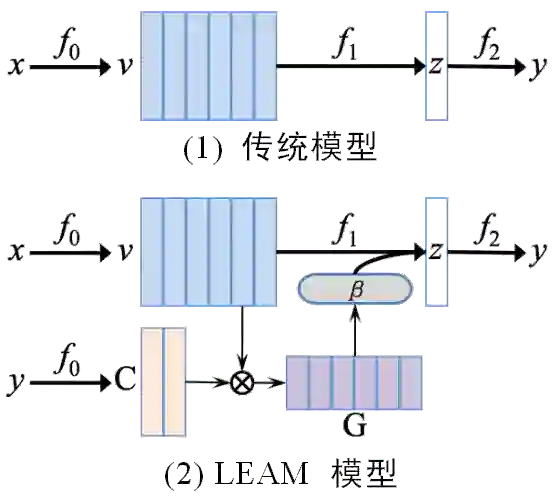
图6:LEAM模型中词语和类别标签之间的语义交互(传统方法和LEAM模型的对比)
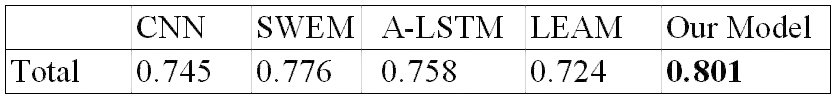
表1:集成模型和三种baseline模型的效果对比
03
用户情感安抚
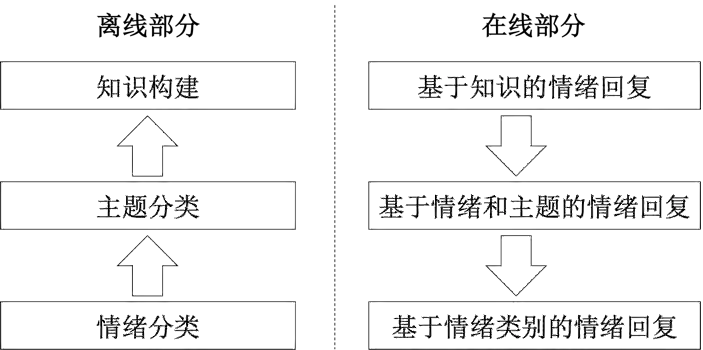
图7:用户情绪安抚整体框架
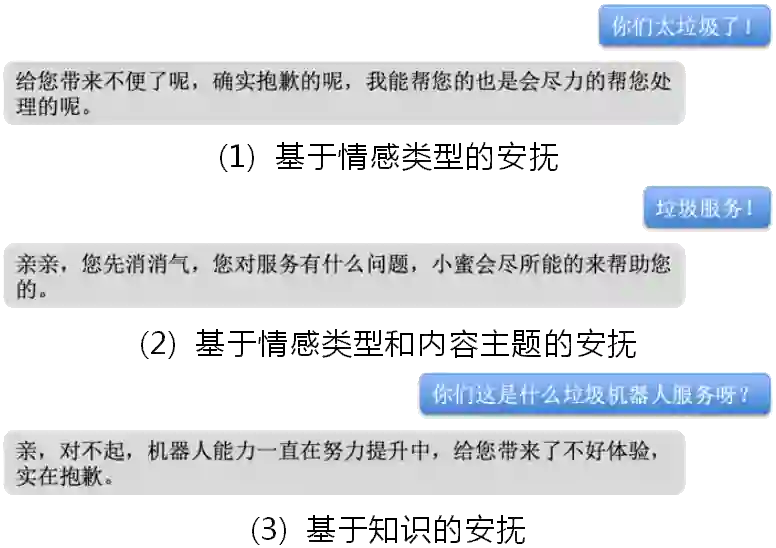
图8:用户情绪安抚示例

图9:文本匹配模型
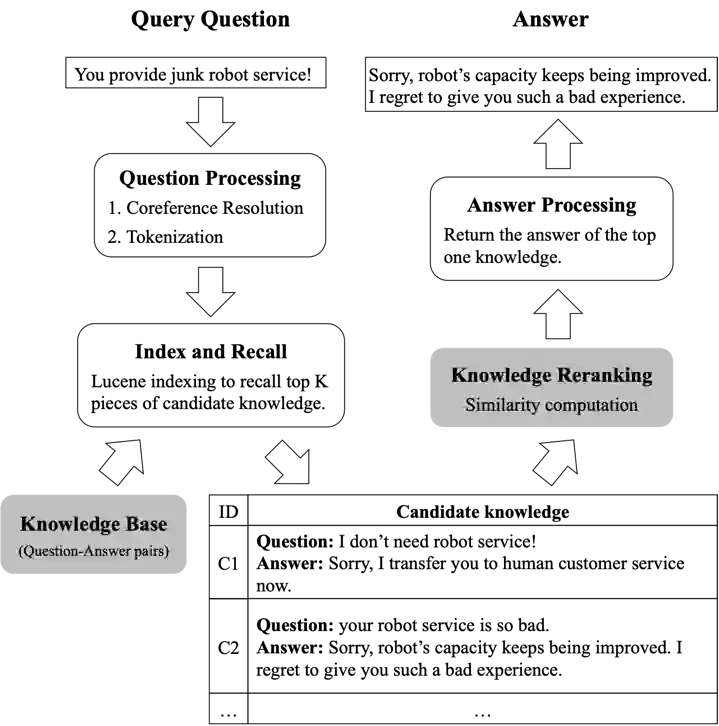
图10:基于检索的问答系统流程图

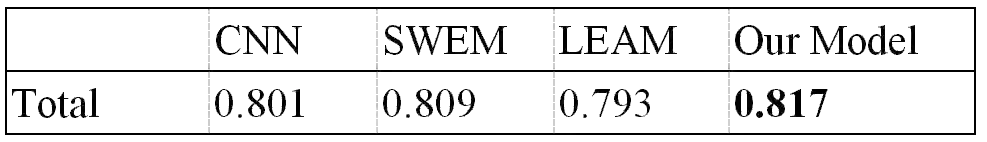
表3:主题分类效果对比
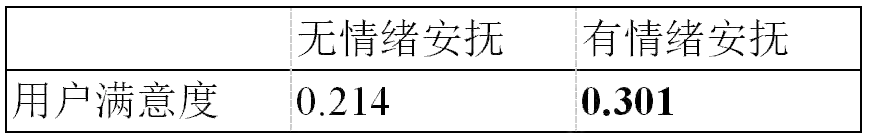
表4:负面情绪安抚对用户满意度的效果对比
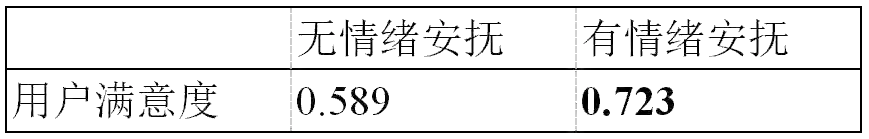
表5:感激情感安抚对用户满意度的效果对比
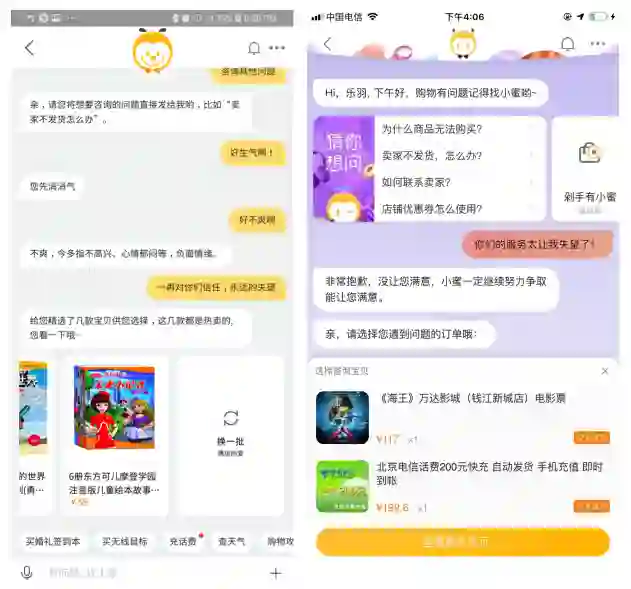
04
情感生成式语聊
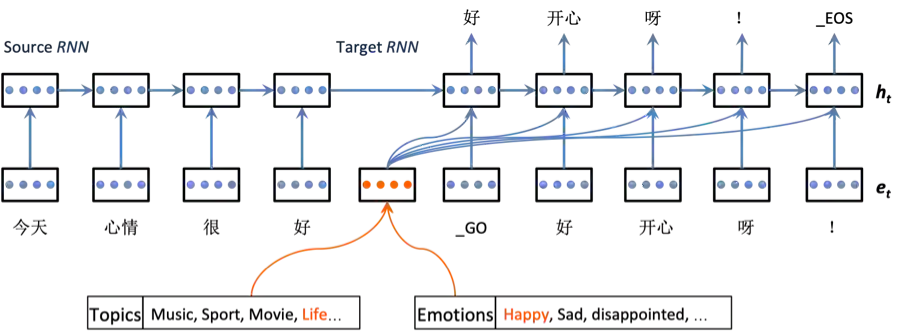
图12:智能客服系统中的情感生成式语聊模型
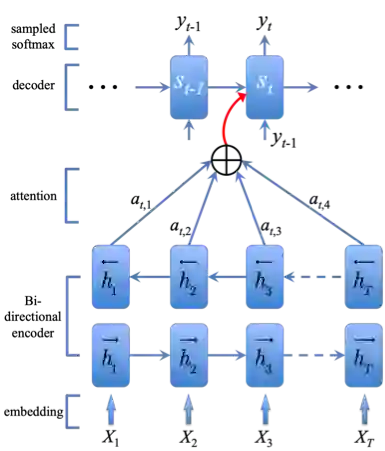
图13:生成式语聊中的注意力机制
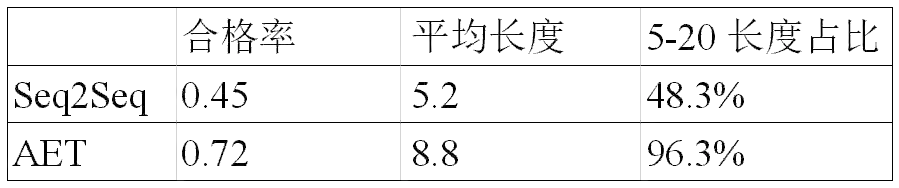
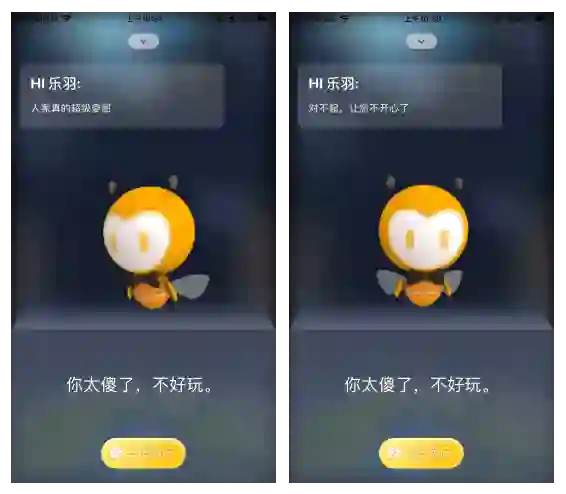
图14:小蜜空间中的情绪生成式语聊应用实例
05
客服服务质检
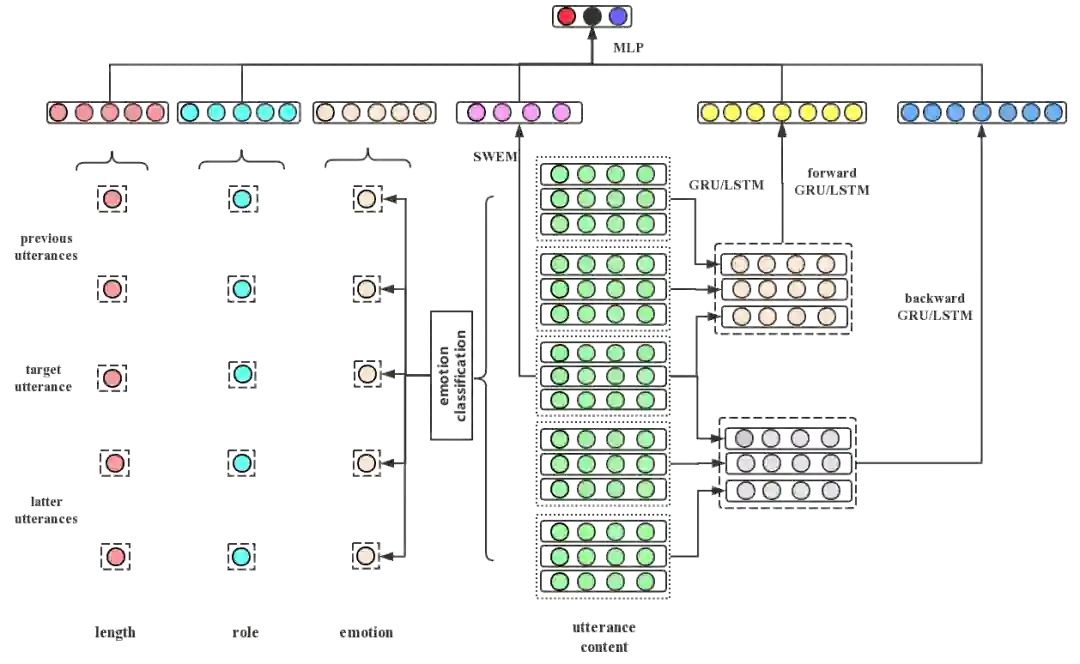
图15:客服服务质检模型1
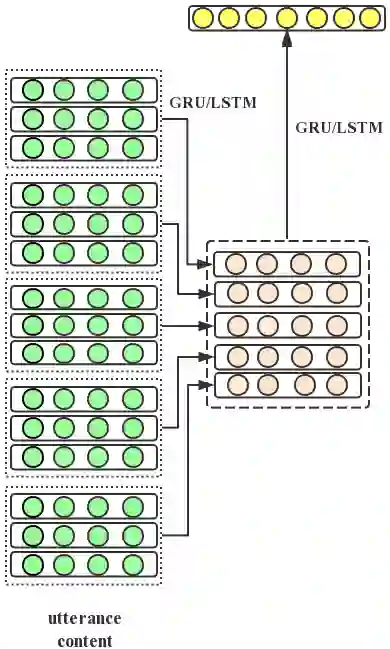
-
我们收集最近被客户投诉的服务会话记录,由业务专家负责从中识别消极或者态度差的服务轮次。最终,1,202个消极服务和125个态度差的服务被人工检测到。这部分数据会被用于训练一个初版质检模型; -
利用该初版模型,我们进一步地从大量原始人工客服语料中检测含有质量问题的服务记录,并且之后由业务专家对这些模型检测结果进行审核,判定结果是否准确。这种对模型结果进行审核的方式,要比直接从对话记录里进行人工检测的方式,大大降低了工作量,适合于标注大量语料。最终,综合第二步的人工审核结果和第一步的人工检测结果,我们一共获取到了33,353条消极数据以及12,501条态度差的数据。此外,通过第二步中的审核结果,判定初版质检模型的识别准确率为0.43。
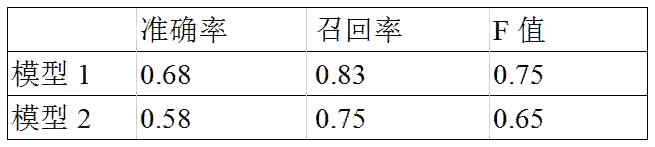
表7:质检模型两种上下文语义抽取方式对比
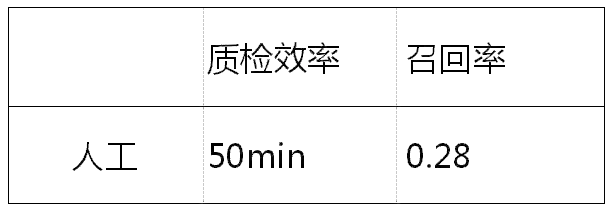
06
会话满意度预估
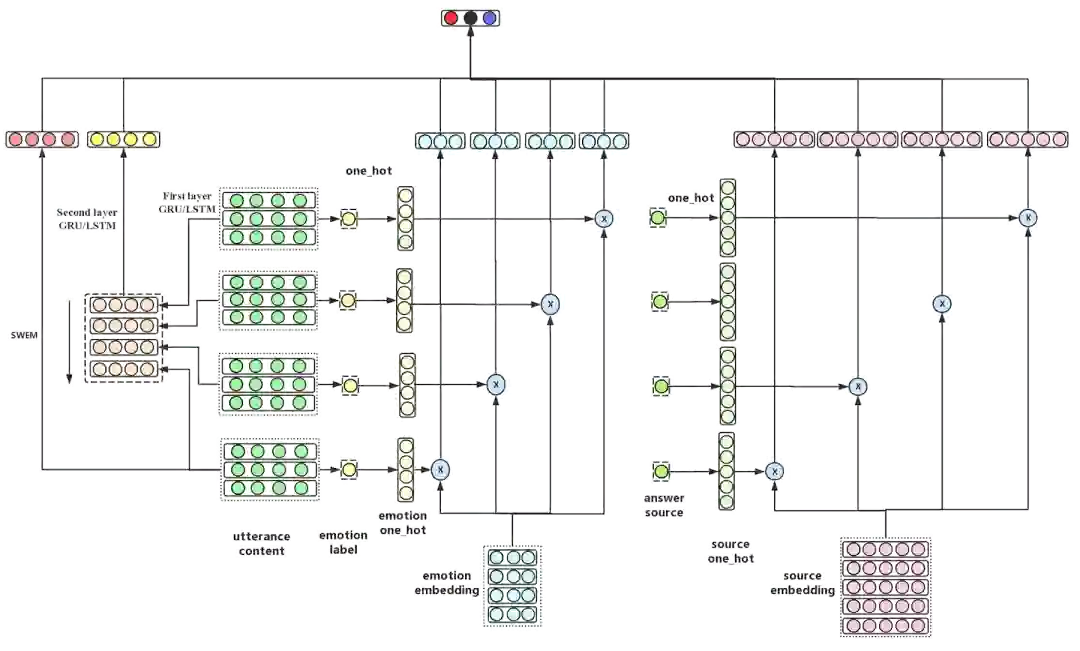
图17:智能客服系统中的用户会话满意度预估模型
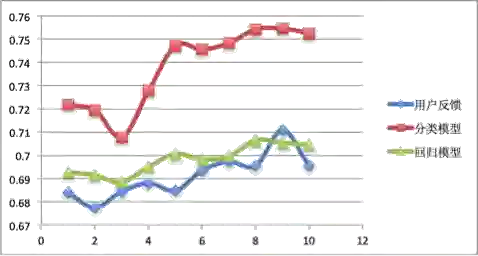
图18:用户会话满意度预估结果比较

表9:用户会话满意度预估结果比较
07
智能人工入口
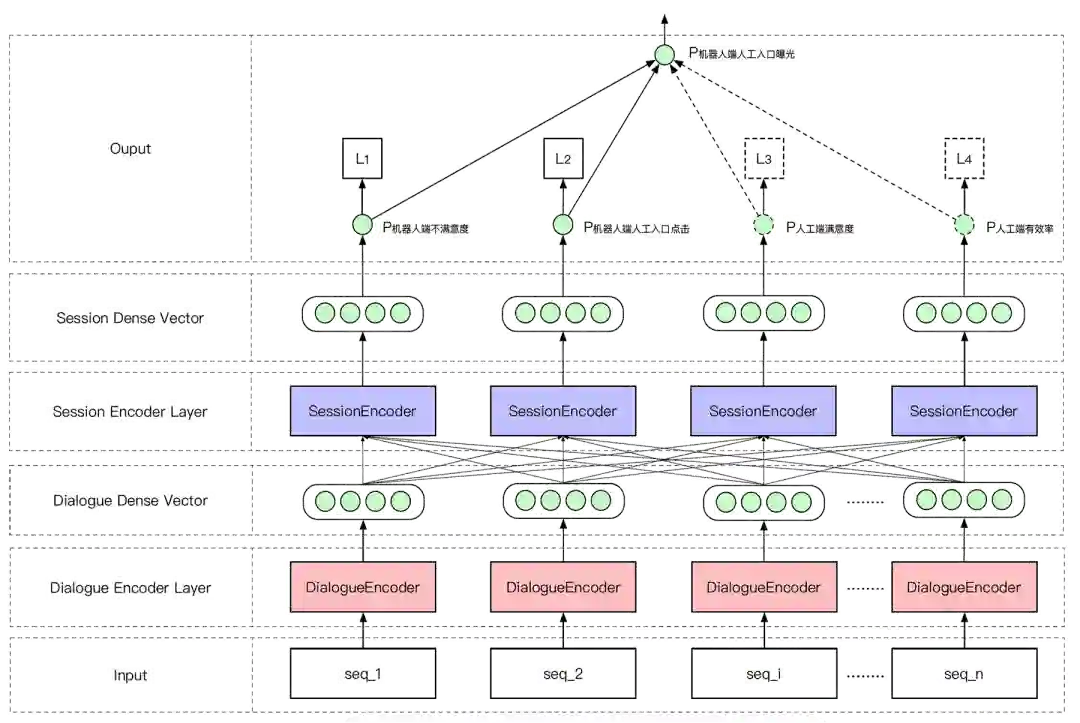
图19:智能客服系统中的智能人工入口用户排序模块
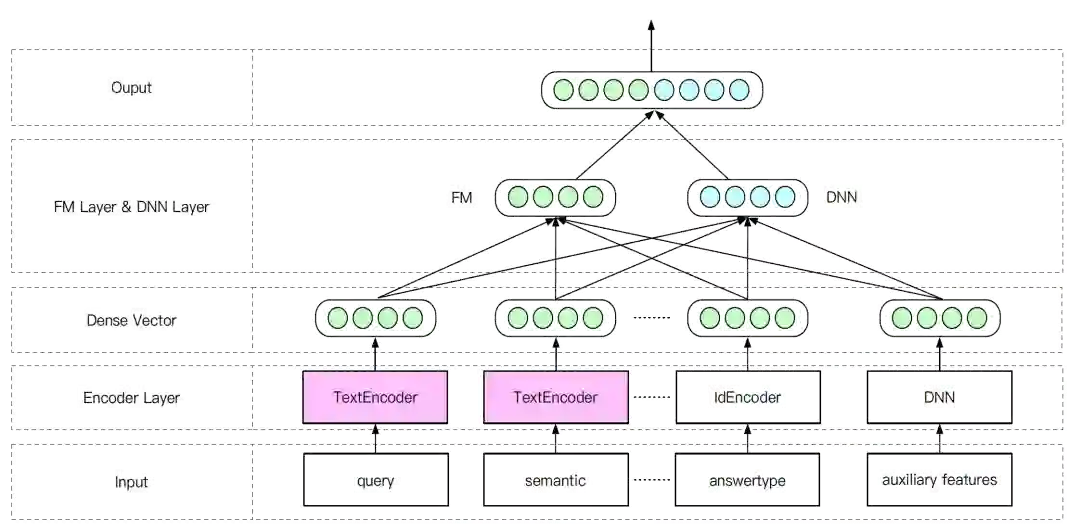
图20:基于DeepFM的DialogueEncoder

表10:使用会话特征
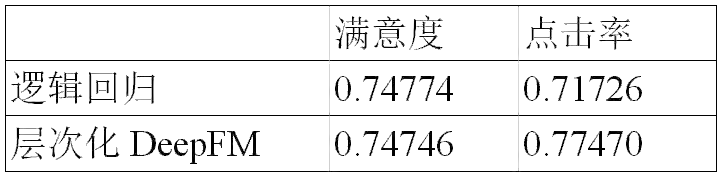
08
总结与展望
今天的分享就到这里,谢谢大家。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
社群推荐:
欢迎加入 DataFunTalk NLP 交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:datafun-coco ),逃课儿会自动拉你进群。


宋双永
阿里巴巴 | 达摩院算法专家
shuangyong.ssy@alibaba-inc.com
王超,阿里花名王栩,资深算法工程师
陈成龙,阿里花名谌龙,算法专家
参考文献:
[1] Okuda T, Shoda S. AI-based Chatbot Service for Financial Industry [J]. Fujitsu Scientific and Technical Journal, 2018, 54(2): 4-8.
[2] Zhu X. Case II (Part A): JIMI’s Growth Path: Artificial Intelligence Has Redefined the Customer Service of JD.com [M]. In Emerging Champions in the Digital Economy. Springer, Singapore, 2019: 91-103.
[3] Li F-L, Qiu M, Chen H, et al. AliMe assist: an intelligent assistant for creating an innovative e-commerce experience [C]. In Proceedings of the ACM on Conference on Information and Knowledge Management, 2017: 2495-2498.
[4] Shen D, Wang G, Wang W, et al. Baseline needs more love: On simple word-embedding-based models and associated pooling mechanisms [C]. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018: 440-450.
[5] Zeng D, Liu K, Chen, Y., et al. (2015). Distant supervision for relation extraction via piecewise convolutional neural networks [C]. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 2015: 1753-1762.
[6] Wang G, Li C, Wang W, et al. Joint Embedding of Words and Labels for Text Classification [C]. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018: 2321–2331.
[7] Pang L, Lan Y, Guo J, et al. Text Matching as Image Recognition [C]. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, 2016: 2793-2799.
[8] Yin W, Schütze H, Xiang B, et al. Abcnn: Attention-based convolutional neural network for modeling sentence pairs [J]. Transactions of the Association for Computational Linguistics, 2016(4): 259-272.
[9] Young T, Cambria E, Chaturvedi I, et al. Augmenting end-to-end dialogue systems with commonsense knowledge [C]. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, 2018: 4970-4977.
[10] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate [C]. In 3rd International Conference on Learning Representations, 2015: .
[11] Zaremba W, Sutskever I, Vinyals O. Recurrent neural network regularization [C]. In 3rd International Conference on Learning Representations, 2015.
[12] 庞亮, 兰艳艳, 徐君,等. 深度文本匹配综述[J]. 计算机学报, 2017, 40(4):985-1003.
[13] Hu B, Lu Z, Li H, et al. Convolutional neural network architectures for matching natural language sentences [C]. In Advances in neural information processing systems, 2014: 2042-2050.
[14] Lu Z, Li H. A deep architecture for matching short texts [C]. In Advances in Neural Information Processing Systems, 2013: 1367-1375.
[15] Qiu X, Huang X. Convolutional neural tensor network architecture for community-based question answering [C]. In Twenty-Fourth International Joint Conference on Artificial Intelligence, 2015: 1305-1311.
[16] McCandless M, Hatcher E, Gospodnetic O. Lucene in action: covers Apache Lucene 3.0 [M]. Manning Publications Co.2010.
[17] Guo H, Tang R, Yey Y, et al. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction [C]. In 26th International Joint Conference on Artificial Intelligence, 2017: 1725-1731.
[18] Chen C, tensorflow-XNN [EB]. 2018. https://git hub.com/ChenglongChen/tensorflow-XNN.
[19] Song S, Meng Y, Shi Z, et al. A simple yet effective method for summarizing microblogging users with their representative tweets [C]. In 2017 International Conference on Asian Language Processing, 2017: 310-313.
[20] Yu J, Qiu M, Jiang J, et al. Modelling domain relationships for transfer learning on retrieval-based question answering systems in e-commerce [C]. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, 2018: 682-690.
[21] Zhou H, Huang M, Zhang T, et al. Emotional chatting machine: Emotional conversation generation with internal and external memory [C]. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018: 730-738.
[22] Li J, Galley M, Brockett C, et al. A personabased neural conversation model [C]. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016: 994–1003.
[23] Wang Y, Huang, M, Zhao L. Attention-based LSTM for aspect-level sentiment classification [C]. In Proceedings of the 2016 conference on empirical methods in natural language processing, 2016: 606-615.
[24] Zhou L, Gao J, Li D, et al. The Design and Implementation of XiaoIce, an Empathetic Social Chatbot [R], 2018, arXiv preprint arXiv:1812. 08989.
 福利来了
福利来了
情感分析算法在阿里小蜜的应用实践


关于我们:

一个在看,一段时光!👇



