Wide&Deep模型的八个实战细节
分享给大家我之前一篇WDL学习笔记,大家记得星标我的公众号哦
我的其他NLP文章可以去这里star:
https://github.com/DA-southampton/NLP_ability
全文目录如下:
0.背景
1. wide & deep 在推荐场景的实践
1.1 如何构建样本
1.2 如何选择正负样本
1.3 如何控制样本不平衡
1.4 解决噪声样本
1.5 特征处理:
1.6 特征工程
1.7 模型离线训练
1.8 模型上线
2. WDL代码实现
0.背景
wide&deep 理论的介绍可以参考我之前写的这个文章:聊一下 Wide & Deep。
WDL在实际应用的时候,有很多细节需要注意。
在我自己的应用中,对WDL模型做了一个简单的修改,加入了多模态(图片加标题)的特征,效果比单纯的xgboost要提升不少。
因为涉及到具体业务,所以不能详细展开。
不过我之前有读一个很不错的文章:wide&deep 在贝壳推荐场景的实践,顺着这个文章的脉络,我们可以来看看WDL需要注意的地方。
全文思维导图:
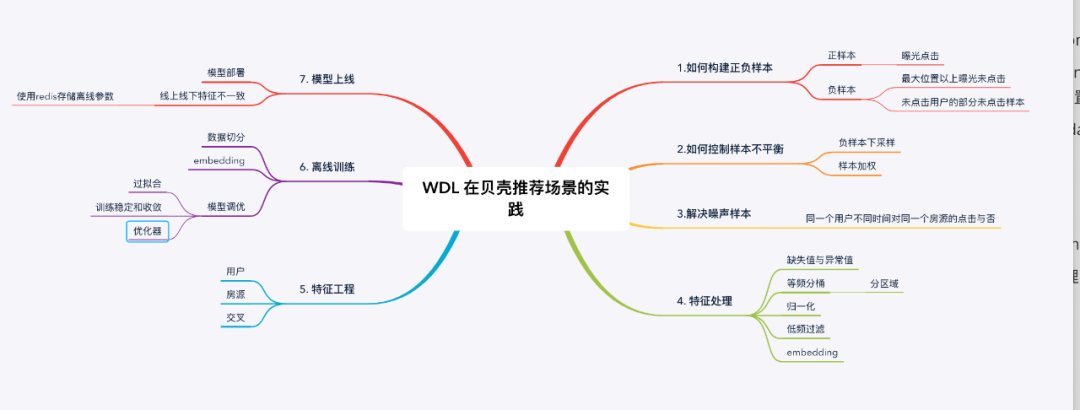
1. WDL 在推荐场景的实践
这个文章中,WDL模型应用场景是预测用户是否点击推荐的房源。我大概整理了需要注意的八个细节点,分享给大家。
1.1 如何构建样本
首先,模型离不开样本,样本一般从日志中获取。一般是通过埋点,记录用户行为到日志,然后清洗日志,获得用户行为。
贝壳这里样本格式是三元组:userid,itemid和label;
至于对应的特征,一般是需要根据userid,itemid到对应hive表格获取整合。
-
正样本:用户点击的房源 -
负样本:用户点击最大位置以上曝光未点击的房源;从未点击的用户部分曝光未点击的房源。
1.2 如何选择正负样本
在这里,想要详细说一下正负样本构建的细节。
首先是对于日志的处理,需要区分web端和app端。不要增加无效的负样本
其次,用户点击最大位置以上曝光未点击的房源,这个方法其实叫做Skip Above,也就是过滤掉最后一次的点击。这样做我们是基于用户对之后的item是没有观测到的。
其次为了避免高度活跃用户的对loss的影响,在训练集中对每个用户提取相同数量的样本。
然后我们来想一下这个问题:从未点击的用户部分曝光未点击的房源。
首先,去除了这部分用户,会出现什么问题?
模型学习到的只有活跃用户和有意向用户的行为习惯,这样线上和线下的数据分布会不一致。我们在线上的遇到的数据,肯定会出现那种不活跃用户。
如果不去除这部分用户,会出现什么情况?
这样的用户在本质上是无效用户。为什么这么说呢?我们模型的作用是为了提升用户点击。
如果频繁给这个用户推荐物品,他一直不点击,也就是说没有正反馈。两种情况,一种是我们推荐的是有很大问题的,但是这种概率极低。还有一种情况,就是这个用户是有问题的。
所以简单来说,我们需不需要对这样的用户做为样本?
很简单,做A/B测试,看是否需要这部分用户以及需要多少这部分用户作为样本。
还有一定需要注意的是,特征需要控制在样本时间之前,防止特征穿越。
1.3 如何控制样本不平衡
一般来说,负样本,也就是未点击的房源肯定是更多的。所以在训练模型的时候,肯定是存在样本不平衡的问题。
贝壳这里采用的是下采样负样本和对样本进行加权。
之前写个一个简单的文章,来讲述了一下如何缓解样本不平衡,可以参考这里:
文章总结的结论就是,无论你使用什么技巧缓解类别不平衡,其实都只能让模型有略微的提升。最本质的操作还是增加标注数据。
就拿贝壳的操作来说,下采样和样本加权,本质上都修改了样本的分布情况。
就会出现训练样本分布和线上真实分布不一致的情况,那么你现在训练的模型究竟在线上真实环境能不能有好的提升,就看模型在真实数据上的评估情况了。
1.4 解决噪声样本
噪声样本指的是:用户在不同时间对同一房源可能会存在不同的行为,导致采集的样本中有正有负。
对于这种样本,如果时间间隔比较短,可以全部删除,也可以保留其中一个。
如果时间间隔比较长,我认为可以全部保留,因为可能上下文环境会发生变化。时间特征会有一定的概率区分出样本的不同,学习到用户短期兴趣变化。
1.5 特征处理:
-
缺失值与异常值处理:常规操作;不同特征使用不同缺失值填补方法;异常值使用四分位;
-
等频分桶处理:常规操作;比如价格,是一个长尾分布,这就导致大部分样本的特征值都集中在一个小的取值范围内,使得样本特征的区分度减小。
不过有意思的是,贝壳使用的是不同地区的等频分布,保证每个城市下特征分布均匀。
-
归一化:常规操作;效果得到显著提升;
-
低频过滤:常规操作;对于离散特征,过于低频的归为一类;
-
embedding:常规操作;小区,商圈id做embedding;
1.6 特征工程
预测目标是用户是否点击itme,所以特征就是从三方面:用户,item,交互特征;
-
用户:
注册时长、上一次访问距今时长等基础特征,最近3/7/15/30/90天活跃/浏览/关注/im数量等行为特征,以及画像偏好特征和转化率特征。
-
房源:
价格、面积、居室、楼层等基础特征,是否地铁房/学区房/有电梯/近医院等二值特征,以及热度值/点击率等连续特征。
-
交叉:
将画像偏好和房源的特征进行交叉,主要包含这几维度:价格、面积、居室、城区、商圈、小区、楼层级别的交叉。交叉值为用户对房源在该维度下的偏好值。
1.7 模型离线训练
-
数据切分:采用7天的数据作为训练集,1天的作为测试集 -
embedding:尝试加入,没有获得很好的效果 -
模型调优: -
防止过拟合:加入dropOut 与 L2正则 -
加快收敛:引入了Batch Normalization -
保证训练稳定和收敛:尝试不同的learning rate(wide侧0.001,deep侧0.01效果较好)和batch_size(目前设置的2048) -
优化器:我们对比了SGD、Adam、Adagrad等学习器,最终选择了效果最好的Adagrad。
1.8 模型上线
-
模型部署:使用TensorFlow Serving,10ms解决120个请求 -
解决线上线下特征不一致:将离线特征处理的参数存储在redis中 -
效果提升: -
CTR:提升6.08% -
CVR::提升15.65%
2. WDL代码实现
Github上有太多了,TF也有官方的实现,我就不多说了
3简单总结
全文是我对wide&deep 在贝壳推荐场景的实践 的学习笔记,工作中实践的时候,参考了很多文章,这个文章比较有代表性,故此分享给大家。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏

