数据竞赛Tricks集锦
志峰现场讲解的《Tricks in Data Mining Competitions 》
鱼佬知识星球分享的《Kaggle数据竞赛知识体系》
1 数据竞赛的流程

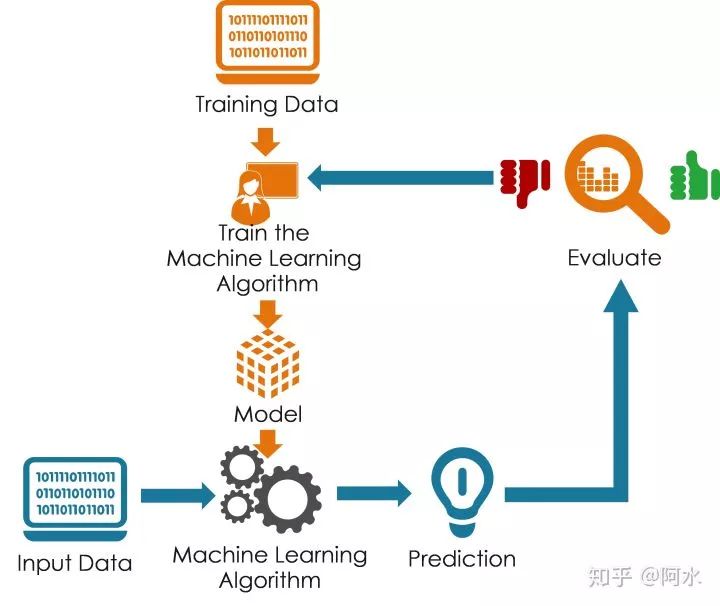
1.1 数据分析
数据是如何产生的,数据又是如何存储的;
数据是原始数据,还是经过人工处理(二次加工的);
数据由那些业务背景组成的,数据字段又有什么含义;
数据字段是什么类型的,每个字段的分布是怎样的;
训练集和测试集的数据分布是否有差异;
数据量是否充分,是否有外部数据可以进行补充;
数据本身是否有噪音,是否需要进行数据清洗和降维操作;
赛题的评价函数是什么,和数据字段有什么关系;
数据字段与赛题标签的关系;
1.2 赛题背景分析
赛题业务场景是什么,数据是如何产生的,数据标签如何得来的?
赛题任务是什么,具体要解决的问题是如何定义的;
赛题任务是否有对应的学术任务?
1.3 数据清洗
对于类别变量,可以统计比较少的取值;
对于数字变量,可以统计特征的分布异常值;
统计字段的缺失比例;
1.4 特征预处理
量纲归一化:标准化、区间放缩
特征编码:
对于类别特征来说,有如下处理方式:
自然数编码(Label Encoding)
独热编码(Onehot Encoding)
哈希编码(Hash Encoding)
统计编码(Count Encoding)
目标编码(Target Encoding)
嵌入编码(Embedding Encoding)
缺失值编码(NaN Encoding)
多项式编码(Polynomial Encoding)
布尔编码(Bool Encoding)
对于数值特征来说,有如下处理方式:
取整(Rounding)
分箱(Binning)
放缩(Scaling)
缺失值处理
用属性所有取值的平均值代替
用属性所有取值的中位数代替
用属性所有出现次数最多的值代替
丢弃属性缺失的样本
让模型处理缺失值
1.5 特征工程
数据中每个字段的含义、分布、缺失情况;
数据中每个字段的与赛题标签的关系;
数据字段两两之间,或者三者之间的关系;
2 结构化数据技巧
3 非结构化数据技巧
3.1 视觉类型任务
1. 图像分类(ImageClassification)
2. 图像检索(Image)
3. 物体检测(ObjectDetection)
4. 物体分割(ObjectSegmentation)
5. 人体关键点识别(PoseEstimation)
6. 字符识别
3.2 文本类型任务
TFIDF
词向量
GPU

4 如何选择一个合适的数据竞赛?




