NLP.TM | 再看word2vector

【NLP.TM】
本人有关自然语言处理和文本挖掘方面的学习和笔记,欢迎大家关注。
往期回顾:
NLP.TM似乎很久没有更新了哈哈哈,其实有些积累了,后面慢慢开始写。
word2vector是自然语言处理中非常非常经典的embedding,即词嵌入模型,主要完成的功能是将文字转化为可供计算的词向量,虽然目前已经被BERT等新型模型逐渐取代,但是在目前一些基线的使用上,仍有非常大的应用空间,这次我计划重看word2vector,主要有下面几个目标:
部分细节已经不太熟悉,希望复习一下,避免有暗坑
一些数据处理上的trick值得再深入挖掘
某些关键API需要确认一下,并且可以避免以后重复查
当然了,熟悉我的朋友都知道,我在文章里,是希望能给大家一些在其他地方找不到或者不好找的东西,重复性的工作和文章我写出来意义不大,且可能写的不如一些前辈更好,所以重复性内容我会用参考文献或者跳转的方式去介绍给大家。
word2vector简述
对于w2v的原理,网上已经有非常多的解释,同时也非常精细,此处我筛选了一些我认为写的非常好的博客和论文,大家可以阅读看看。
[NLP] 秒懂词向量Word2vec的本质:这篇知乎文章对w2v有比较简洁但是完善的理解,高赞:https://zhuanlan.zhihu.com/p/26306795
word2vec Parameter Learning Explained:这篇论文看懂了,w2v基本没啥问题了
《word2vec Parameter Learning Explained》论文学习笔记:上面论文的笔记,可以参照着读吧:https://blog.csdn.net/lanyu_01/article/details/80097350
开始之前提醒一下先修知识,理解基本神经网络的正反向传播以及SGD算法。
word2vector顾名思义,其实就是旨在把每个单词转化为词向量,其实很多方式都可以实现这个功能,最简单的当然就是one-hot了,但是面对无敌庞大的词库,直接使用one-hot来进行表示将会面临很大的内存占用和很高的计算时间,于是有了LDA、GloVe以及现在比较新的bert等,都是尝试通过使用连续的词向量模型来进行词向量转化,从而进行后续的自然语言处理任务。
那么word2vector是通过什么方式来产生词向量呢——答案就是上下文+网络的模式,而这种上下文如何体现,就是通过类似完形填空的方式进行,对于上下文若干个单词,来预测我挖空位置的单词,这就是CBOW的目前最为常见的方式,看好,是最为常见的方式,即multi-word context(多词语境)形式,这种形式是目前很多文章里面提到的形式,但他的形式并不唯一,这个在《word2vec Parameter Learning Explained》论文里面谈到了,只是一种目前出现最多的形式,其实它的原始形式是一种只有一个单词输入的形式。
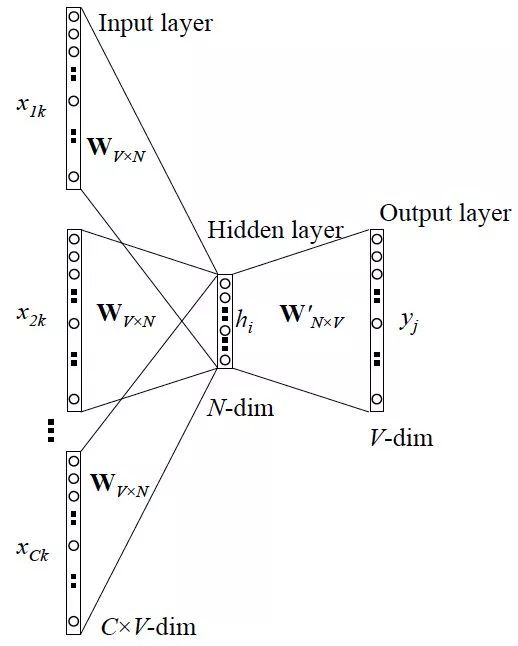
而反过来,我们同样可以通过该单词预测上下文,这就是Sikp-gram的形式。
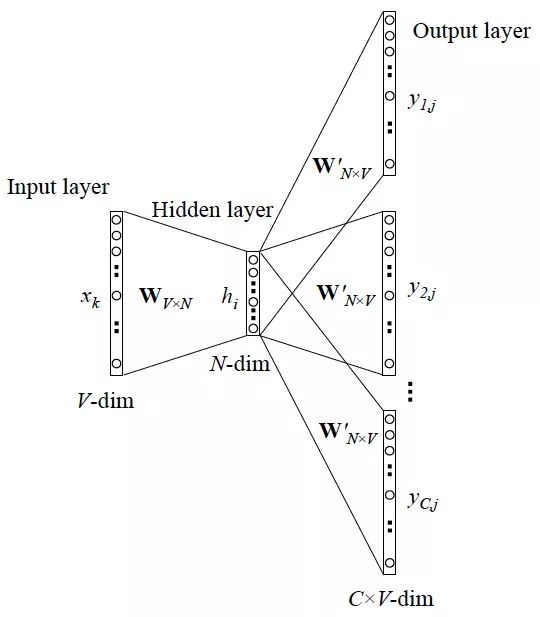
两个图的含义非常类似,input layer和output layer都是one-hot类型的文本信息,CBOW和Skip-gram的区别在于是多输入单输出和单输入多输出,中间是一个隐含层,这种模式训练(SGD训练)之后,隐含层的输出结果提取出来其实就是对应词汇的词向量了。
word2vector的优化
模型其实并不复杂,然而在实际操作中其实会遇到大量问题,而针对这些问题,很多人提出了很好的方案,而这些方案,也成为了计算中的技巧,这些技巧其实同样可以在现实中得到实践。
Hierarchical Softmax
Hierarchical Softmax是一种为了解决词汇表过大导致计算维度过大问题的解决方案,借助树结构的层次性来缓解维度过大的问题,按照出现时间来看其实方法本身的提出甚至早于word2vector本身,它的实质是构建一棵二叉树,每个单词都挂在叶子节点上,对于大小为 V的词库,非叶子节点则对应有 V-1个,由于树本身无环的特性(在离散数学中,树的定义是连通但无回路的图),每个单词都能通过从根节点开始的唯一一条路径进行表示。
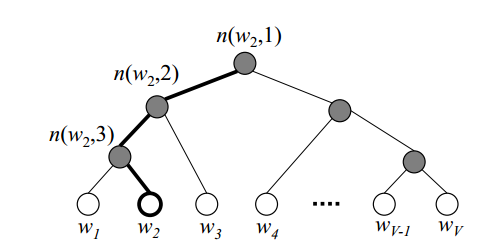
很多文章都有讨论过这个结构,我这里有一个比较规范化的理解,看看对于各位的理解有无帮助。
首先是,这棵树怎么建立的。这棵树的实质是一棵Huffman树(给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为Huffman树),而这棵Huffman树的权重则来源于每个单词出现的频率,根据每个单词的出现频率即可构建出Huffman树。至于原因,可以比较简单的理解为,更为经常出现的单词,在训练的时候经常会出现,快点找到他更有利于进行后续的计算,因此深度可以浅一些,相反不经常出现的单词弱化存在感问题不大,所以建造这样的Huffman树有利于提升效率。
那么,建立这棵树之后,是怎么应用和计算呢。此时在word2vec中,使用的就转为分层二分类逻辑斯蒂回归,从根节点出发,分为负类则向左子树走,分为正类则向右子树走,分类的依据来源于每个非叶子节点上所带有的内部节点向量。
说完应用,就需要回头说怎么训练,训练的原理其实和一般地word2vector非常类似,就是使用基于梯度的方式,如SGD进行更新,值得注意的是,对于树内的每个分类模型,对应的权重也需要更新。
那么此处,我想要提炼的两个trick就是:
多分类问题,可以转化为多个二分类进行计算。
多个二分类问题,可以通过树结构,尤其是Huffman树进行,能进一步提升计算效率。
经过证明,使用Hierarchical Softmax的搜索复杂度是对数级的,而不使用则是线性级的,虽然复杂度都不是很高但是在与如此大的词库场景下,这个提升绝对有必要。
Negative Sampling
也称为负采样。负采样需要解决的是每次迭代的过程中都需要更新大量向量的问题,它的核心思想就是“既然要更新这么多,那就更新一部分呗”。在实际应用中,是需要正负样本输入的,正样本(输出的上下文单词)当然需要保留下来,而负样本(不对的样本)同样需要采集,但是肯定不能是词库里面的所有其他词,因此我们需要采样,这个采样被就是所谓的Negative Sampling,抽样要根据一定的概率,而不是简单地随机,而是可以根据形式的分布。
这个分布估计是这一小块方向下研究最多的,里面谈到很多,如果看单词在语料库中出现的频次,则停止词出现的会很多,当然还可能会有一些由于文本领域产生的特殊词汇,如果平均分配,则采样并没有特别意义,区分度不大,因此根据经验,如下形式似乎得到较多人认可:
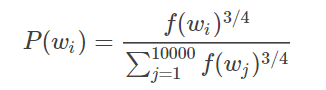
其中f表示计算对应词汇的词频,这是一个抽样的概率,当然了,还有很多诸如考虑共现概率等构建的指标也有,但是目前似乎没有得到普遍认可,不再赘述。
那么此处能够提炼的关键就是:
样本不平衡或者更新复杂的情况下可以考虑仅使用部分样本进行计算和更新
这个技巧其实在推荐系统中也非常常见,尤其是CTR预估一块,大部分场景下负样本并不少,此时需要一定的负采样。
word2vector的实现
说了这么多word2vector的理论和技巧,当然要谈到这个模型怎么用了,虽然说BERT、ELMo等目前逐渐火了起来,但是在“实现为王”的工业界,word2vector仍然是非常重要的实验基线,因此非常建议大家学起来用起来,甚至的,类似推荐系统等,都会用类似word2vector的方式进行embedding,所以使用起来真的是非常重要的。
此处个人推荐使用gensim中自带的word2vector模型,个人感觉比较合适,即gensim.models里面的word2vec。
数据载入与训练
要进行有关训练,首先需要进行数据的载入,数据载入的形式主要由进入模型的API需求决定,要找这个,就得看这里:
Word2Vec的API文档:https://radimrehurek.com/gensim/models/word2vec.html
这里补充一句严肃的话,一定一定要会自己查API文档,看看每个函数的输入是什么,需要什么格式,输出是什么,格式是什么样的,这是做这行的基本操作。

这是一个wordvector类的构造函数,运行构造函数可以得到一个word2vector模型类,而且是进行过训练后的,后续可以进行词向量提取等操作,这个文档可以让你知道,这个函数有哪些输入参数,那些是必要的,那些是不必要的,因为有些命名会比较简单,所以在个文字下面,还有更详细的说明。

例如这里的size,就是指词向量的维度,具体含义在这里就不赘述啦,自己看自己查。
然后在这里下面给出了一个非常简单的例子,如下。
from gensim.models import Word2Vec
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
model = Word2Vec(sentences, min_count=1)
这里需要大家读出一个非常重要的信息,那就是这里给出了sentences这个变量所需要的格式,句子所需要的格式是一个二维数组,第一维下是一个一个句子的句子数组,内部句子是通过字符串数组组成,那么我们就知道怎么够造句子,从而放入自己的语料进行训练。
data = []
with open(INPUTPATH) as f:
for line in f:
ll = line.strip().split(" ")
data.append(ll[1:])
model = word2vec.Word2Vec(data, size=300)
在这里,我的语料放在了INPUTPATH中,每一行是一个中文句子(已经进行好分词,用空格隔开),因此读取的石油,我用空格将其分开成字符串数组,然后把字符串数组装到data中,构成和上述sentences相同的形式,此处我们就能完成预料的导入。size=300与我实际场景应用有关,词向量长度是300。
word2vector的应用
网上说到了很多类似求距离之类的操作,其实在现实应用中,求距离是一个进行检测的方法,但是更多的,我们只需要和查字典类似,找到我们需要的词汇对应的词向量即可,因此,我们也可以这么做。
网上和API提供了很多方案,此处我给出一个我已经走通的方案。
def loadw2c(inputpath):
model = gensim.models.Word2Vec.load(inputpath)
wordEmb = {}
for k, v in model.wv.vocab.items():
wordEmb[k] = model.wv[k]
return wordEmb
首先载入模型,模型路径是inputpath,而model.wv.vocab是一个dictionary形式的数据,这里面存着所有词汇对应的词向量,此处我们将其转到wordEmb中,然后输出,这样通过wordEmb这个词典我们能更快的查找到所需词汇的词向量,当然了,大家也可以直接用model.wv.vocab甚至是model.wv来查找,一样可以。
总结
本文从基础上、优化技巧上以及实现上分别讨论了word2vector模型,虽然比较简略,忽略了大量的公式推导和推理,但是希望大家能从更为宏观的角度去理解并且能够保证实现,这里再次总结一下几个本文提到的关键trick,无论是理论上还是技术上的。
多分类问题,可以转化为多个二分类进行计算。
多个二分类问题,可以通过树结构,尤其是Huffman树进行,能进一步提升计算效率。
样本不平衡或者更新复杂的情况下可以考虑仅使用部分样本进行计算和更新.
经常查文档,阅读文章,能快速理解工具的使用方法。
另外,在文末还是给大家整理一些有关word2vector的资料,方便大家深入理解。
[NLP] 秒懂词向量Word2vec的本质:这篇知乎文章对w2v有比较简洁但是完善的理解,高赞:https://zhuanlan.zhihu.com/p/26306795
word2vec Parameter Learning Explained:这篇论文看懂了,w2v基本没啥问题了
《word2vec Parameter Learning Explained》论文学习笔记:上面论文的笔记,可以参照着读吧:https://blog.csdn.net/lanyu_01/article/details/80097350
word2vector论文:Distributed Representations of Words and Phrases and their Compositionality
[DeeplearningAI笔记]序列模型2.7负采样Negative sampling:有关负采样的文章,比较容易理解:https://blog.csdn.net/u013555719/article/details/82190917
Hierarchical softmax(分层softmax)简单描述。有关Hierarchical softmax的解释:https://cloud.tencent.com/developer/article/1387413
文章写到这里啦,希望能对大家有帮助。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



