干货 | 自然语言处理(1)之聊一聊分词原理
微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第一
【Python】:排名第三
【算法】:排名第四
前言
在做文本挖掘时,首先要做的预处理就是分词。英文单词天然有空格隔开容易按照空格分词,但有时也需要把多个单词做为一个分词,比如一些名词如“New York”,需要做为一个词看待。而中文由于没有空格,分词就是一个需要专门去解决的问题了。无论是英文还是中文,分词的原理都类似,本文就对文本挖掘时的分词原理做一个总结。
分词的基本原理
现代分词都是基于统计的分词,而统计的样本内容来自于一些标准的语料库。假如有一个句子:“小明来到荔湾区”,我们期望语料库统计后分词的结果是:"小明/来到/荔湾/区",而不是“小明/来到/荔/湾区”。那么如何做到这一点呢?
从统计的角度,我们期望"小明/来到/荔湾/区"这个分词后句子出现的概率要比“小明/来到/荔/湾区”大。如果用数学的语言来说说,如果有一个句子S,它有m种分词选项如下:

其中下标ni代表第i种分词的词个数。如果我们从中选择了最优的第r种分词方法,那么这种分词方法对应的统计分布概率应该最大,即:
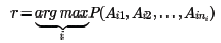
但概率分布P(Ai1,Ai2,...,Aini)并不容易计算,因为涉及到ni个分词的联合分布。在NLP中,为了简化计算,我们通常使用马尔科夫假设,即每一个分词出现的概率仅仅和前一个分词有关,即:
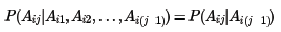
使用了马尔科夫假设,则联合分布为:
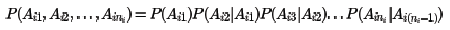
而通过标准语料库可以近似的计算出所有的分词之间的二元条件概率,比如任意两个词w1,w2,它们的条件概率分布可以近似的表示为:
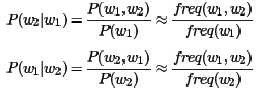
其中freq(w1,w2)表示w1,w2在语料库中相邻一起出现的次数,而其中freq(w1),freq(w2)分别表示w1,w2在语料库中出现的统计次数。
利用语料库建立的统计概率,对于一个新的句子就可以通过计算各种分词方法对应的联合分布概率,找到最大概率对应的分词方法,即为最优分词。
N元模型
只依赖于前一个词或许太武断,则依赖于前两个词呢?即:
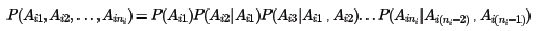
这样也可以,只是联合分布的计算量大大增加。一般称只依赖于前一个词的模型为二元模型(Bi-Gram model),而依赖于前两个词的模型为三元模型。以此类推,我们可以建立四元模型,五元模型,...一直到通用的N元模型。越往后,概率分布的计算复杂度越高。当然算法的原理是类似的。
在实际应用中,N一般都较小,一般都小于4,主要原因是N元模型概率分布的空间复杂度为O(|V|^N),其中|V|为语料库大小,而N为模型的元数,当N增大时,复杂度呈指数级的增长。
基于N元模型的分词方法虽然很好,但在实际中应用也有很多问题,首先,某些生僻词,或者相邻分词联合分布在语料库中没有,概率为0。这种情况我们一般会使用拉普拉斯平滑,即给它一个较小的概率值。第二个问题是如果句子长,分词情况多,计算量非常大,可以用维特比算法来优化算法时间复杂度。
维特比算法在分词中的应用
为便于描述,所有讨论以二元模型为基础
对于一个有多种分词可能的长句子,可以使用暴力方法计算出所有的分词可能的概率,再找出最优分词方法。但用维特比算法可以大大简化求出最优分词的时间。
维特比算法常用于隐式马尔科夫模型HMM的解码过程,但它是一个通用的求序列最短路径的方法,也可以用于其他的序列最短路径算法,比如最优分词。
维特比算法采用的是动态规划来解决这个最优分词问题的。首先看一个简单的分词例子:"人生如梦境"。它的可能分词可以用下面的概率图表示:
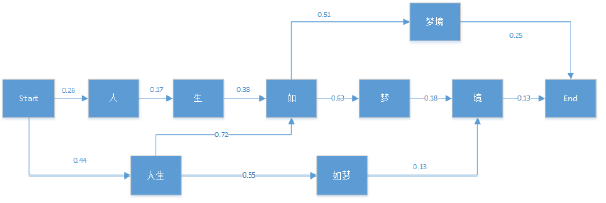
图中箭头为通过统计语料库得到的各分词条件概率。维特比算法需要找到从Start到End之间的一条最短路径。对于在End之前的任意一个当前局部节点,需要计算到达该节点的最大概率δ,和到达当前节点满足最大概率的前一节点位置Ψ。
维特比算法的计算过程
首先初始化为:
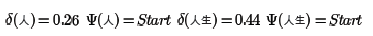
对于节点"生",只有一个前向节点,因此有:
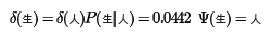
对于节点"如",情况稍微复杂一点,因为它有多个前向节点,要计算出到“如”概率最大的路径:
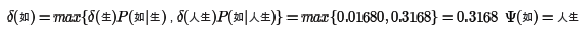
类似的方法可以用于其他节点如下:
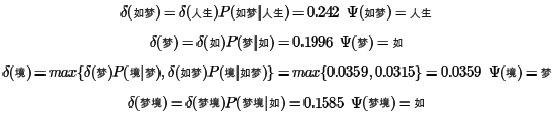
最后看最终节点End:
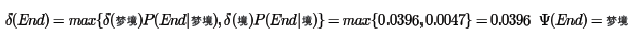
由于最后的最优解为“梦境”,现在开始用Ψ反推:
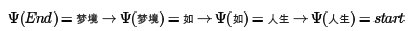
从而最终的分词结果为"人生/如/梦境"。
常用分词工具
对于文本挖掘中需要的分词功能,一般会用现有的工具。简单的英文分词不需要任何工具,通过空格和标点符号就可以分词,而进一步的英文分词推荐使用nltk(下载地址:http://www.nltk.org/)。对于中文分词,则推荐用结巴分词(下载地址:https://github.com/fxsjy/jieba/)。
总结
分词是文本挖掘的预处理的重要的一步,分词完成后,可以继续做一些其他的特征工程,比如向量化(vectorize),TF-IDF以及Hash trick,这些在后面会逐一给出。
欢迎分享给他人让更多的人受益

参考:
宗成庆《统计自然语言处理》 第2版
博客园
http://www.cnblogs.com/pinard/p/6677078.html
李航《统计学习方法》维特比算法
nltk:http://www.nltk.org/
结巴分词:https://github.com/fxsjy/jieba/
近期热文
干货 | 高盛:2017人工智能报告中文版(附PDF版下载)

进机器学习微信交流群
请加微信(guodongwe1991)
备注(姓名-单位-研究方向)
广告、商业合作
请发邮件:357062955@qq.com