异动分析技术解决方案—异动归因之指标拆解

一 前言
二 目的
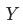 , 波动为
, 波动为
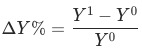 ,其中
,其中
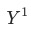 是当月的数据,
是当月的数据,
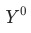 为上个月(同比/环比)的数据。
的集合
为上个月(同比/环比)的数据。
的集合
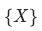 对于
对于
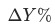 的贡献:
的贡献:
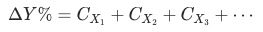
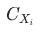 表示指标(或维度)
表示指标(或维度)
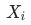 对于
对于
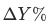 的贡献度(contribution)。
组成
的方式包括:
的贡献度(contribution)。
组成
的方式包括:
-
加法 (例,各渠道uv加和)
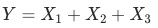 (例,各渠道uv加和)
(例,各渠道uv加和) -
乘法 (例,已知rpm=cpc*ctr下,算出cpc、ctr分别对rpm的贡献)
-
比率型指标 (例,各广告计划的cpf, 或者各个渠道的cpuv等)
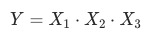 (例,已知rpm=cpc*ctr下,算出cpc、ctr分别对rpm的贡献)
(例,已知rpm=cpc*ctr下,算出cpc、ctr分别对rpm的贡献)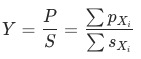 (例,各广告计划的cpf, 或者各个渠道的cpuv等)
(例,各广告计划的cpf, 或者各个渠道的cpuv等)三 贡献率的拆解方法
1 加法拆解
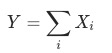
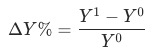
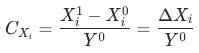 ,证明见附录。
,证明见附录。
2 乘法拆解
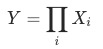
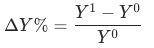
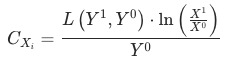 , 证明见附录。
, 证明见附录。
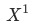 是当月的数据
是当月的数据
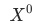 ,
,
 为上个月(同比/环比)的数据,
为上个月(同比/环比)的数据,
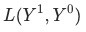 为平均对数权重:
为平均对数权重:
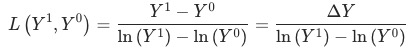
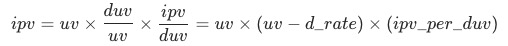
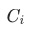 ,衡量3个指标的重要性:
,衡量3个指标的重要性:
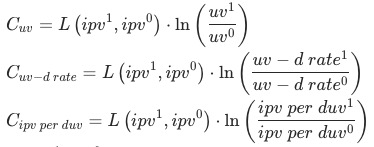
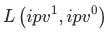
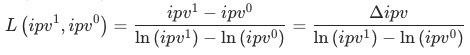
3 比率型指标拆解
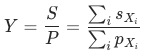 ,
,
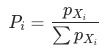 ,
,
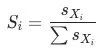 ,
,
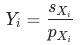
-
分项的相对数指标波动贡献 ,即当期与基期的分项规模一致时,分项指标带来的变化:
分项的指标波动贡献 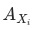
-
分项的结构变化 ,即当期与基期分项规模变化部分的指标变化:
分项的结构变化 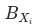
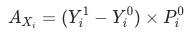
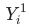

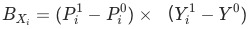
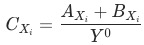
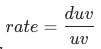 ,流量渠道可分为付费、免费、自然、其他,每种渠道的uv-d转化率为
,流量渠道可分为付费、免费、自然、其他,每种渠道的uv-d转化率为
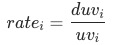 ,各渠道的商详页访问人数(duv)占比用
,各渠道的商详页访问人数(duv)占比用
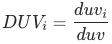 表示,各渠道人数(uv)占比用
表示,各渠道人数(uv)占比用
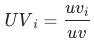 ,如果uv-d转化率同比下跌,我们想定位出哪个渠道出现了问题;各渠道的贡献
,如果uv-d转化率同比下跌,我们想定位出哪个渠道出现了问题;各渠道的贡献
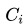 是怎么样计算为:
是怎么样计算为:
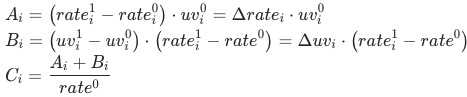
4 实例应用
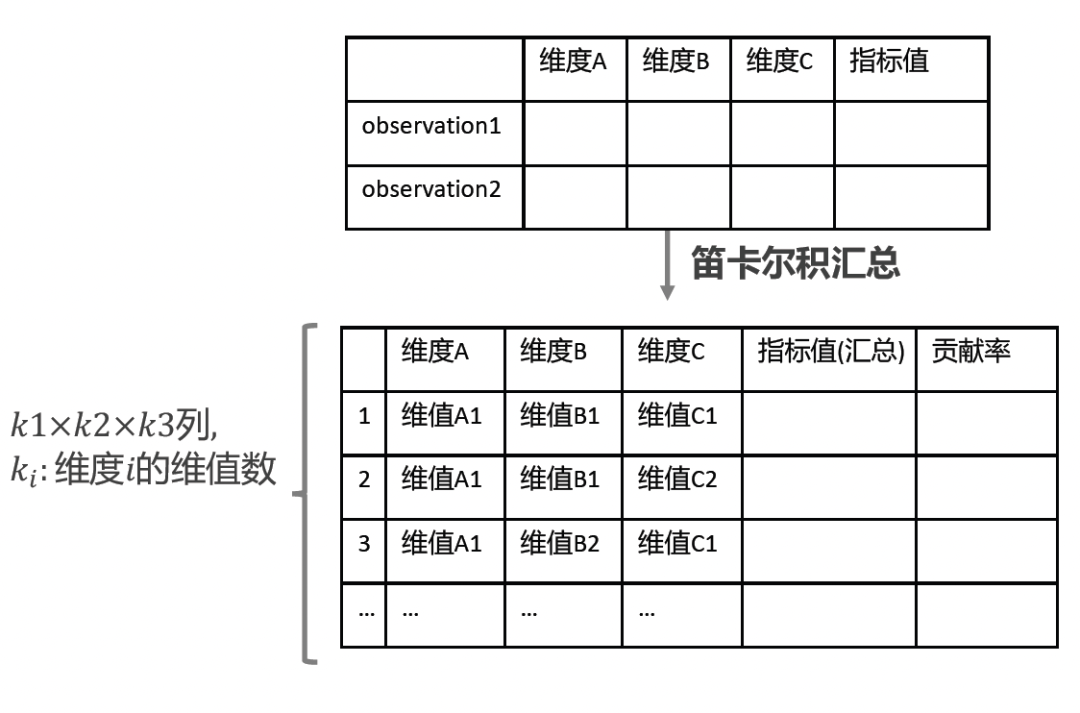
图二:计算贡献率之后的数据结果样式
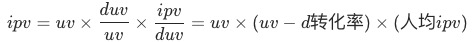
四 多层下钻归因方案—决策树
 表示两个维度,其下角标表示维度下的维值。下图具象的看出通过不同维值的组合,把数据空间切割成不同块,用不同的颜色代表。
表示两个维度,其下角标表示维度下的维值。下图具象的看出通过不同维值的组合,把数据空间切割成不同块,用不同的颜色代表。
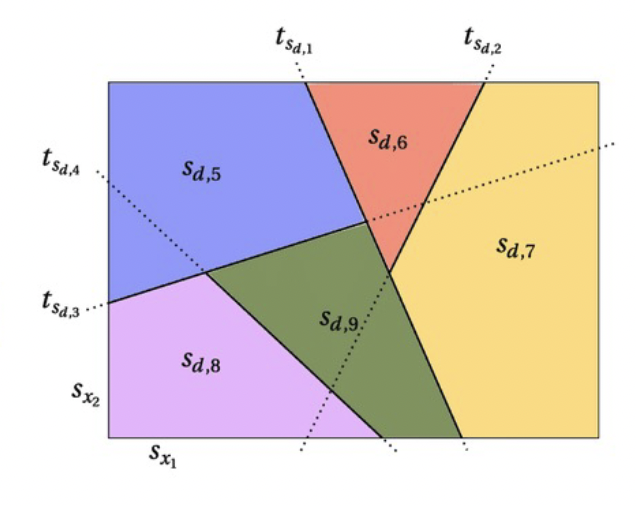
图四:决策树对数据空间的切割可视化
1 剪枝
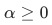 , 表示算法的复杂度:
, 表示算法的复杂度:
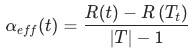
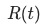 表示的是结点
表示的是结点
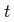 的方差(近似加权熵的概念:impurity,下文都泛称为熵,计算公式
),
的方差(近似加权熵的概念:impurity,下文都泛称为熵,计算公式
),
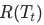 是结点的子树
是结点的子树
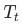 的熵的总和,
的熵的总和,
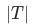 为决策树结点个数 。
为决策树结点个数 。
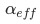 高,表示结点往下分的信息增益高。图五表示异动维数的个数与决策树层结点熵的平均数的关系:以黄线为例, 当异动的维数为2时,决策树在第二层的熵最高,从第二层往后,再往下分熵越小,信息增益少,过拟合明显。从折线明显看到,熵的拐点在第二层,决策树最大深度等于2。
高,表示结点往下分的信息增益高。图五表示异动维数的个数与决策树层结点熵的平均数的关系:以黄线为例, 当异动的维数为2时,决策树在第二层的熵最高,从第二层往后,再往下分熵越小,信息增益少,过拟合明显。从折线明显看到,熵的拐点在第二层,决策树最大深度等于2。
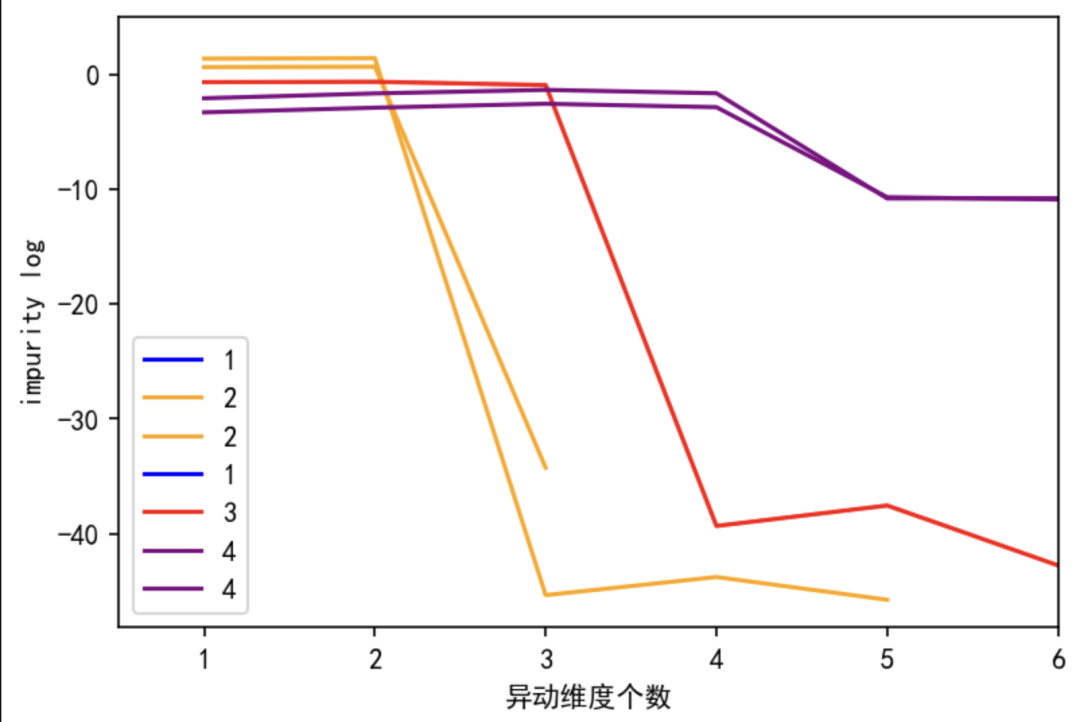
 进行剪枝。
进行剪枝。
五 模型表现
1 模拟数据
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
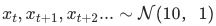 模拟无异动的维度组合的时间序列,见图六
模拟无异动的维度组合的时间序列,见图六
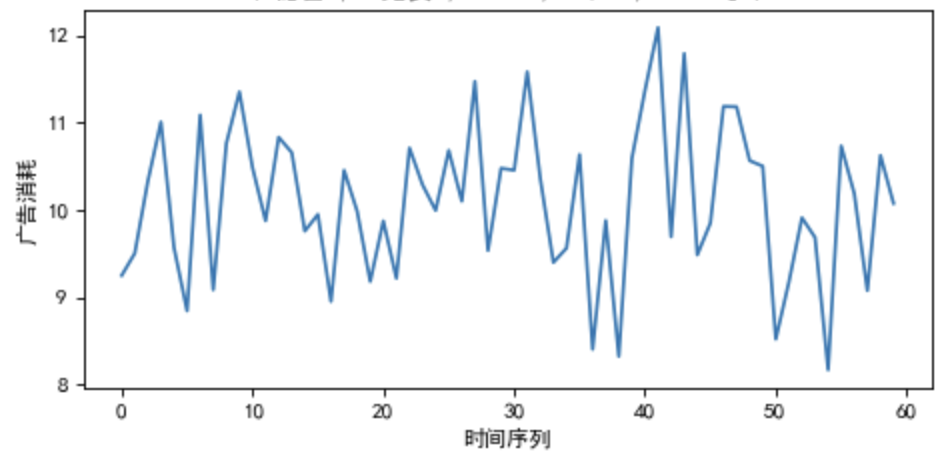
图六:无异动的时间序列
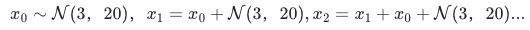
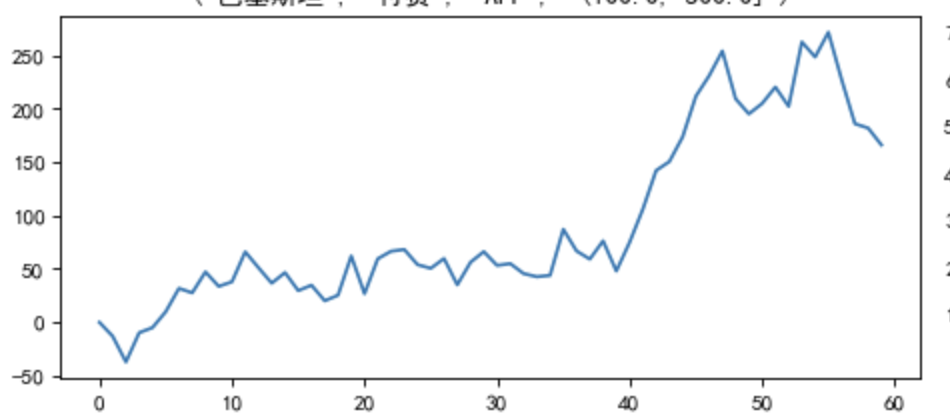
图七(a):有异动的时间序列1
2 模型评估
例一:异动维度在两处
a. 国家=伊拉克, 渠道=免费, 端型='WAP', 曝光档位=[5:100]
b. 国家=法国, 渠道=免费, 端型='PC', 曝光档位=[0:5]
将贡献度算出,数据输入决策树模型, 结果见图八,可以看出决策树精确的找到异动的数据(共精确找到7个维值,共8个), 且这两组标红数据对于异动的贡献绝对值最大。我们自定义树结构找父节点的方法,自动剪掉冗余分支,只截取重点枝干呈现。
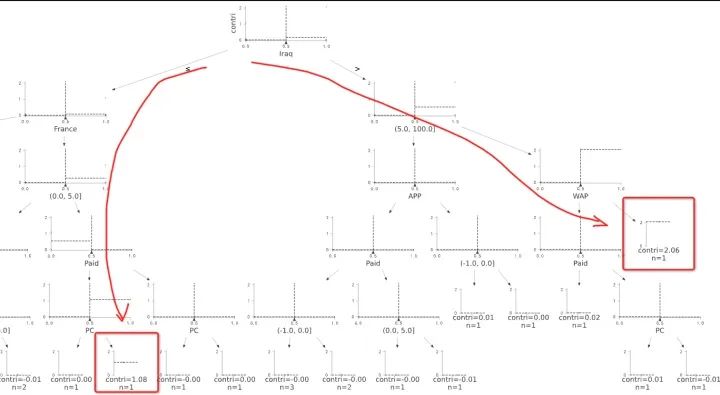
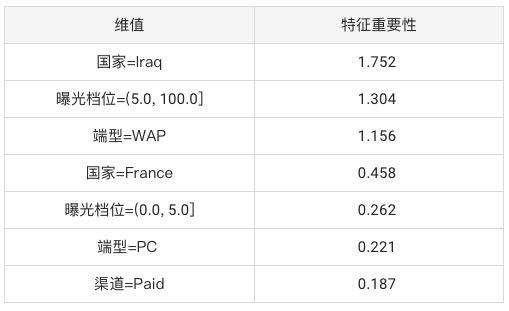
例二:异动维度在一处,只异动一个维度在付费上
通过剪枝,模型成功找到一维信息,避免提供太多噪音令用户混淆。
更多
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
六 局限
七 技术产品化

八 附录
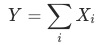
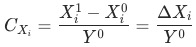 ,
,
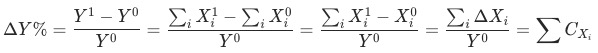
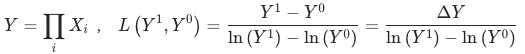
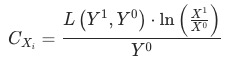 ,
,
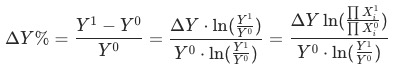
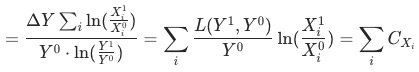
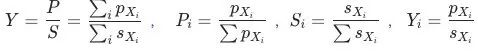
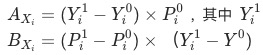
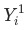
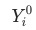
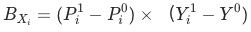
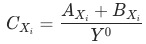
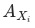 和
和
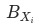 有助于我们避开辛普森悖论带来的陷阱。
有助于我们避开辛普森悖论带来的陷阱。

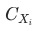 符合mece原则证明:相互独立:
符合mece原则证明:相互独立:
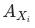 和
和
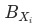 的计算公式中不涉及其他分项的完全穷尽。
的计算公式中不涉及其他分项的完全穷尽。
参考
-
Ang, Beng W., F. Q. Zhang, and Ki-Hong Choi. "Factorizing changes in energy and environmental indicators through decomposition." Energy 23.6 (1998): 489-495. -
Ang B W . The LMDI approach to decomposition analysis: a practical guide[J]. Energy Policy, 2005, 33(7):867-871. -
《波动解读—指标拆解的加减乘除双因素》 https://zhuanlan.zhihu.com/p/412117828
开源 Elasticsearch技术训练营
登录查看更多
相关内容
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月18日