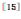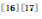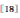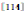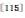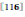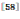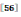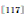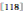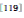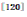CCF于1月11日发布了最新一期《中国计算机科学技术发展报告》,对软件智能化开发技术等11个方向的研究进展做了详细介绍和讨论。我们将分期分享报告中的精彩内容,加入CCF会员登录CCF官网,可在数字图书馆栏目下载和浏览。
![]()
1 引言
随着计算机网络、社交媒体、数字电视和多媒体获取设备的快速发展,以图像和视频为代表的多媒体数据的生成、处理和获取变得越来越方便, 多媒体应用日益广泛,数据量呈现出爆炸性的增长,已经成为大数据时代的主要数据对象。如何在海量的图像大数据中以较小的时空开销准确地找到一幅感兴趣的图像,已经成为近年来多媒体和信息检索领域的重要研究热点。
基于内容的图像检索(Content-based Image Retrieval, CBIR)方法利用从图像提取的特征来进行检索。常用的图像特征主要有颜色、纹理和形状,包括局部特征和全局特征。局部特征是基于图像的某个区域提取的图像描述符,如尺度不变特征SIFT(Scale Invariant Feature Transform)![]()
![]() 。全局描述符基于整幅图像提取的描述符,如GIST
。全局描述符基于整幅图像提取的描述符,如GIST![]() 。全局特征对图像的压缩率较高,但区分力不强;局部特征的区分力强,但数目太多,故而各种编码方法被提了出来,如BOF(Bag of Features,特征袋)
。全局特征对图像的压缩率较高,但区分力不强;局部特征的区分力强,但数目太多,故而各种编码方法被提了出来,如BOF(Bag of Features,特征袋)![]() ,Fisher向量 (Fisher Vectors, FV)
,Fisher向量 (Fisher Vectors, FV)![]() ,以及VLAD (Vector of Locally Aggregated Descriptors)
,以及VLAD (Vector of Locally Aggregated Descriptors)![]() 等。BOF,VLAD,FV等描述符通常继承了局部特征的部分不变性,如对平移、旋转、缩放、光照和遮挡等与语义相关不大的因素保持不变。
等。BOF,VLAD,FV等描述符通常继承了局部特征的部分不变性,如对平移、旋转、缩放、光照和遮挡等与语义相关不大的因素保持不变。
基于SIFT等图像描述符的检索效果相对于现有的其他特征明显改进,然而,SIFT存在如下几个问题:(1)缺乏空间几何信息; (2)缺乏颜色信息。(3)缺乏高层语义。为了丰富描述符的信息,通常将SIFT与其它的特征进行融合。如文献![]() 中,利用核来融合多种特征来形成语义属性特征,再与FV相串联以融合SIFT特征。文献
中,利用核来融合多种特征来形成语义属性特征,再与FV相串联以融合SIFT特征。文献![]() 则是通过图来融合SIFT与颜色特征,以提高检索的准确率。文献
则是通过图来融合SIFT与颜色特征,以提高检索的准确率。文献![]() 则是通过一个二维索引结构来融合SIFT与颜色特征。
则是通过一个二维索引结构来融合SIFT与颜色特征。
SIFT描述的是图像的底层特征,无法很好地表示图像的高层语义,因此,基于数据驱动的图像特征提取方法被提出,神经网络就是其中之一。然而,最初之时,神经网络的层与层之间是全连接的,参数太多,网络不能太深,否则,训练将非常困难。一方面,训练将非常耗时;另一方面,当时没有带标签的大数据集,训练网络时容易发生过拟合。卷积神经网络(Convolutional Neural Network, CNN)![]() 的神经元是局部连接的,是一种易于训练的网络,这使得CNN可以更深。随着ImageNet
的神经元是局部连接的,是一种易于训练的网络,这使得CNN可以更深。随着ImageNet![]() 等带标签的大数据集的提出,CNN得以广泛应用。在ILSVRC2012 (ImageNet Large Scale Visual Recognition Challenge 2012) 比赛上,Alex等
等带标签的大数据集的提出,CNN得以广泛应用。在ILSVRC2012 (ImageNet Large Scale Visual Recognition Challenge 2012) 比赛上,Alex等![]() 提出的CNN框架取了冠军,远远超过了前人的结果, 此CNN通常被称为AlexNet。AlexNet拥有5个卷积层,3个全连接层,6000万参数,65万个神经元。为了加快训练,AlexNet以ReLU
提出的CNN框架取了冠军,远远超过了前人的结果, 此CNN通常被称为AlexNet。AlexNet拥有5个卷积层,3个全连接层,6000万参数,65万个神经元。为了加快训练,AlexNet以ReLU![]() 作为激励单元, 利用GPU进行加速;此外,AlexNet在全连接层使用了Dropout
作为激励单元, 利用GPU进行加速;此外,AlexNet在全连接层使用了Dropout![]() ,以减弱过拟合现象。继AlexNet之后,VGGNet(或OxfordNet)
,以减弱过拟合现象。继AlexNet之后,VGGNet(或OxfordNet)![]() 、GoogLeNet
、GoogLeNet![]() (ILSVRC2014冠军)、ResNet
(ILSVRC2014冠军)、ResNet![]() (ILSVRC2015冠军) 等新的CNN框架相继被提出,CNN被广泛应用到图像分
(ILSVRC2015冠军) 等新的CNN框架相继被提出,CNN被广泛应用到图像分![]() 、语义分割
、语义分割![]() 、动作识别
、动作识别![]() 、语音识别
、语音识别![]() 和机器翻译
和机器翻译![]() 等领域,并几乎都获得了当时最好的结果。
等领域,并几乎都获得了当时最好的结果。
文献![]() 等表明,CNN 具有良好的跨域特性(transferability)(或通用性), 从预训练(pre-trained)的CNN提取的特征可以被广泛应用到各个领域的各种数据集。文献
等表明,CNN 具有良好的跨域特性(transferability)(或通用性), 从预训练(pre-trained)的CNN提取的特征可以被广泛应用到各个领域的各种数据集。文献![]() 中,预训练的CNN被用于图像分类、属性检测、细粒度识别、图像检索,均取得了优良的结果。文献
中,预训练的CNN被用于图像分类、属性检测、细粒度识别、图像检索,均取得了优良的结果。文献![]() 表明,源任务数据集(ImageNet)与目标任务数据集的差异越小,视觉识别任务的效果越好。基于卷积神经网络的深度学习
表明,源任务数据集(ImageNet)与目标任务数据集的差异越小,视觉识别任务的效果越好。基于卷积神经网络的深度学习![]() 得到的特征不仅保持了一定的不变性,而且还包含了更多的高层语义信息,可以有效地缩小底层特征与高层语义之间的鸿沟
得到的特征不仅保持了一定的不变性,而且还包含了更多的高层语义信息,可以有效地缩小底层特征与高层语义之间的鸿沟![]() 。CNN全连接层特征性能较好,是最常使用的CNN特征,然而,CNN全连接层特征的几何不变性无法与SIFT相比,且缺乏对局部细节的描述,因而卷积层特征也成为了研究的热点。
。CNN全连接层特征性能较好,是最常使用的CNN特征,然而,CNN全连接层特征的几何不变性无法与SIFT相比,且缺乏对局部细节的描述,因而卷积层特征也成为了研究的热点。
本报告将从浅层特征、深层特征和特征融合三个方面对国内外研究进展和面临的挑战进行介绍,并对未来的发展趋势进行展望。
2 国内研究现状
2.1 浅层特征
为了提高描述符的不变性,通常通过在训练集中加入水平翻转后的图片,但是这会使用算法的时空开销加倍。Xie等提出了一个对于水平翻转具有不变性的局部描述符MAX-SIFT![]() 。MAX-SIFT是对原SIFT和从水平翻转后的图片得到的SIFT的进行max-pooling得到的。MAX-SIFT并没有从水平翻转后的图片再提取SIFT,而是利用原图片的SIFT来得到翻转图片的的SIFT,因为原SIFT与翻转图片的SIFT间存在一种简单的排列关系。这使得MAX-SIFT与SIFT的速度相当。在场景分类与细粒度分类等数据集上的实验结果表明,MAX-SIFT要优于SIFT。而且也要优于2014年提出的“基于狄利克雷分布的直方图特征变换(Dirichlet-based Histogram Feature Transform,DHFT)”
。MAX-SIFT是对原SIFT和从水平翻转后的图片得到的SIFT的进行max-pooling得到的。MAX-SIFT并没有从水平翻转后的图片再提取SIFT,而是利用原图片的SIFT来得到翻转图片的的SIFT,因为原SIFT与翻转图片的SIFT间存在一种简单的排列关系。这使得MAX-SIFT与SIFT的速度相当。在场景分类与细粒度分类等数据集上的实验结果表明,MAX-SIFT要优于SIFT。而且也要优于2014年提出的“基于狄利克雷分布的直方图特征变换(Dirichlet-based Histogram Feature Transform,DHFT)”![]() 。虽然MAX-SIFT对水平翻转具有不变性,但对于其它严重变形的情形,MAX-SIFT可能与SIFT同样无能为力。
。虽然MAX-SIFT对水平翻转具有不变性,但对于其它严重变形的情形,MAX-SIFT可能与SIFT同样无能为力。
Gao等对TE+DA编码方法进行了改进,提出了快速DA(Fast Democratic Aggregation, FDA)![]() 。 Gao等主要从两个方面对TE+DA进行了改进:(1)提高核矩阵的计算速度。TE要使用嵌入到高维空间的向量来计算核矩阵,然后利用核矩阵来计算DA的权值。但是,Gao等认为没有必要将SIFT映射到高维向量,对RootSIFT进行白化后,whitened-RootSIFT也可以获得TE后的高维向量的属性:相似的特征间的相似度较大,不相似的特征间的相似度较小。利用whitened-RootSIFT计算核矩阵极大的减少了算法的时空开销。(2)在提取SIFT时会引入人工“视觉并发(visual co-occurence)现象”:同一个图像分片被多个SIFT表示,这些SIFT仅仅是方向不同。Gao等提出利用描述符间的空间上下文(如空间位置)来减弱这种现象。Gao等利用空间上下文信息提出了一个依赖矩阵,利用依赖矩阵与原来的核矩阵的加权平均来形成一个新的核矩阵。实验结果表明,FDA比DA要快一个量级,而且FDA的准确率比DA要略高。
。 Gao等主要从两个方面对TE+DA进行了改进:(1)提高核矩阵的计算速度。TE要使用嵌入到高维空间的向量来计算核矩阵,然后利用核矩阵来计算DA的权值。但是,Gao等认为没有必要将SIFT映射到高维向量,对RootSIFT进行白化后,whitened-RootSIFT也可以获得TE后的高维向量的属性:相似的特征间的相似度较大,不相似的特征间的相似度较小。利用whitened-RootSIFT计算核矩阵极大的减少了算法的时空开销。(2)在提取SIFT时会引入人工“视觉并发(visual co-occurence)现象”:同一个图像分片被多个SIFT表示,这些SIFT仅仅是方向不同。Gao等提出利用描述符间的空间上下文(如空间位置)来减弱这种现象。Gao等利用空间上下文信息提出了一个依赖矩阵,利用依赖矩阵与原来的核矩阵的加权平均来形成一个新的核矩阵。实验结果表明,FDA比DA要快一个量级,而且FDA的准确率比DA要略高。
2.2 深度特征
2.2.1 全连接层
CNN的全连接层特征通常有4096维,对其进行pooling后得到的维度将更大。中国科技大学的Song等![]() 提出利用CNN来学习一个低维的表示。Song等减少ZFNet
提出利用CNN来学习一个低维的表示。Song等减少ZFNet![]() 的FC7层的滤波器数(一般用1024),以此作为一个瓶颈层, 此特征也被称为DBF(Deep Bottleneck Feature)。Song等利用滑动窗口法从输入图提取224*224的分片,从每一个分片提取一个DBF, 然后用一种被称之为“二阶池化(second-order pooling)”
的FC7层的滤波器数(一般用1024),以此作为一个瓶颈层, 此特征也被称为DBF(Deep Bottleneck Feature)。Song等利用滑动窗口法从输入图提取224*224的分片,从每一个分片提取一个DBF, 然后用一种被称之为“二阶池化(second-order pooling)”![]() 的方法来对它们进行聚合,得到的描述符称之为BoDBF(Bag of DBF)
的方法来对它们进行聚合,得到的描述符称之为BoDBF(Bag of DBF)![]() 。在PascalVOC2007
。在PascalVOC2007![]() 对象分类数据集以及MIT场景分类数据集上的结果表明,BoDBF描述符优于MOP-CNN
对象分类数据集以及MIT场景分类数据集上的结果表明,BoDBF描述符优于MOP-CNN![]() 和SCFV
和SCFV![]() 。Song等也测试使用IFV对DBF特征进行pooling,但分类结果不如二阶池化方法,证明了二阶池化方法的优越性。BoDBF由于使用的是简单的二阶池化,而且DBF特征维度较小,计算量比同样使用全连接层特征的SCFV、MOP-CNN等方法要小。
。Song等也测试使用IFV对DBF特征进行pooling,但分类结果不如二阶池化方法,证明了二阶池化方法的优越性。BoDBF由于使用的是简单的二阶池化,而且DBF特征维度较小,计算量比同样使用全连接层特征的SCFV、MOP-CNN等方法要小。
图像分类问题与图像检索有很多相似之处,这两个问题都可以用BOW来解决,不同的是,图像检索是“BOW+检索过程”,而分类问题是“BOW+分类器”。Xie等表明,图像分类与检索本质上是相同的,并提出了ONE(Online Nearest-neighbor Estimation,在线近邻估计)![]() 这一算法来统一分类与检索问题。ONE是通过统一分类与检索的相似性计算算法来达到这一目的的。ONE的过程如下:(1)使所有的数据库图片属于不同的类(N张图片属于N个类);(2)用密集采样的方式从每一张图片提取LO个尺度的多个图像分片。分片与图片本身属于同一个类。(3)提取每个分片的CNN特征(VGGNet的全连接层特征);(4)近邻搜索:提取查询图片的分片,计算查询图像(分片集合)到每一个类(图像分片集合)的距离。此计算过程类似于“多分辨率搜索”
这一算法来统一分类与检索问题。ONE是通过统一分类与检索的相似性计算算法来达到这一目的的。ONE的过程如下:(1)使所有的数据库图片属于不同的类(N张图片属于N个类);(2)用密集采样的方式从每一张图片提取LO个尺度的多个图像分片。分片与图片本身属于同一个类。(3)提取每个分片的CNN特征(VGGNet的全连接层特征);(4)近邻搜索:提取查询图片的分片,计算查询图像(分片集合)到每一个类(图像分片集合)的距离。此计算过程类似于“多分辨率搜索”![]() 中的相似性计算过程。(5)返回结果。分类问题:返回距离最小的类;检索问题:根据距离排序。第(4)步是一个比较耗时的过程,Xie等用3种方法来加速:(1)PCA降维;4096维->512维。(2)ANN(Approximate Nearest Neighbor)搜索:用积量化算法编码;(3)GPU加速。ONE在3个场景分类数据集、3个细粒度分类数据集、2个图像检索数据集上都取得了当时最先进的结果。尤其是,ONE在当时最大的场景分类数据集SUN-397上使得准确率提升了将近10个百分点。ONE在Holidays/UKB数据集上达到了0.887/3.873。Xie等将SIFT-BOW与ONE相结合,使得检索准确率进一步提升,不过很有限。
中的相似性计算过程。(5)返回结果。分类问题:返回距离最小的类;检索问题:根据距离排序。第(4)步是一个比较耗时的过程,Xie等用3种方法来加速:(1)PCA降维;4096维->512维。(2)ANN(Approximate Nearest Neighbor)搜索:用积量化算法编码;(3)GPU加速。ONE在3个场景分类数据集、3个细粒度分类数据集、2个图像检索数据集上都取得了当时最先进的结果。尤其是,ONE在当时最大的场景分类数据集SUN-397上使得准确率提升了将近10个百分点。ONE在Holidays/UKB数据集上达到了0.887/3.873。Xie等将SIFT-BOW与ONE相结合,使得检索准确率进一步提升,不过很有限。
MOP-CNN使用滑动窗口法来生成多个尺度的图像分片, 这些分片中有不少含有噪声,而OLDFP![]() 使用简单的max-pooling来对从分片提取的CNN特征进行聚合,造成了信息的损失。鉴于此,Bao等
使用简单的max-pooling来对从分片提取的CNN特征进行聚合,造成了信息的损失。鉴于此,Bao等![]() 使用VLAD-pooling来对从各分片提取的全连接层特征进行聚集,由此而形成的描述符称之为基于对象的深度特征聚集 (Object-based Aggregation of Deep Feature, OADF)
使用VLAD-pooling来对从各分片提取的全连接层特征进行聚集,由此而形成的描述符称之为基于对象的深度特征聚集 (Object-based Aggregation of Deep Feature, OADF)![]() 。与OLDFP相同,OADF也利用Selective Search 来生成图像分片, 其与OLDFP的不同在于对分片使用了VLAD-pooling, 因而可以看作是OLDFP的一个改进版。OADF在Holidays和Oxford数据集上取得了优于MOP-CNN和OLDFP的性能。Bao等认为可以利用分片之间的关联来进一步提升性能。
。与OLDFP相同,OADF也利用Selective Search 来生成图像分片, 其与OLDFP的不同在于对分片使用了VLAD-pooling, 因而可以看作是OLDFP的一个改进版。OADF在Holidays和Oxford数据集上取得了优于MOP-CNN和OLDFP的性能。Bao等认为可以利用分片之间的关联来进一步提升性能。
2.2.2 卷积层
Gao等![]() 研究了用深度特征进行图像识别的系统中各种因子的作用,以得到一个简单、有效和准确率高的图像分类系统。Gao等主要研究了5种因子:(1)层,是使用卷积层还是使用全连接层;(2)标准化;(3)FV的GMM的Gaussian分量数(K);(4)空间信息;(5)多尺度。基于对这些影响因子的研究,提出了深度空间金字搭(Deep Spatial Pyramid, DSP)
研究了用深度特征进行图像识别的系统中各种因子的作用,以得到一个简单、有效和准确率高的图像分类系统。Gao等主要研究了5种因子:(1)层,是使用卷积层还是使用全连接层;(2)标准化;(3)FV的GMM的Gaussian分量数(K);(4)空间信息;(5)多尺度。基于对这些影响因子的研究,提出了深度空间金字搭(Deep Spatial Pyramid, DSP)![]() 描述符。DSP对卷积层特征图(而非对输入图像)使用Spatial Pyramid (SP)分割以捕获空间信息,然后使用IFV对分割后的每一个块进行编码,将各个块的IFV描述符串联起来后便得到DSP描述符。因为是在特征图上使用SP分割,而不是在原输入图像上进行,所以只需前向通过CNN一次,节省了时间开销。MPP
描述符。DSP对卷积层特征图(而非对输入图像)使用Spatial Pyramid (SP)分割以捕获空间信息,然后使用IFV对分割后的每一个块进行编码,将各个块的IFV描述符串联起来后便得到DSP描述符。因为是在特征图上使用SP分割,而不是在原输入图像上进行,所以只需前向通过CNN一次,节省了时间开销。MPP![]() 对原输入图像构建多分辨率金字塔, MOP-CNN则是对输入图像使用滑动窗口法来获取多个尺度的信息。此外,Gao等提出了一个新的特征标准化方法:2-范数矩阵标准化(L2 matrix normalization),使用图片所有卷积层特征形成的矩阵的谱范数来对特征进行标准化。2-范数矩阵标准化使用了来自整幅图像的信息,可以捕获一些全局信息,对光照和尺度变化等更具有较强的抵抗力。Gao等发现,当FV的K在1~4之间时(基于SIFT的FV使用的K值通常位于64~ 256),DSP即可取得最优的结果。如此小的K值将极大的减小DSP的维度。极小的K值之所以有效,Gao等认为是由于从卷积层提取的局部特征太少了(100个左右),不足以用于准确估计较大的GMM模型。为了进一步捕获多个尺度的信息,Gao等提出了DSP的一个多尺度版本-Multi-scale DSP(Ms-DSP)。Ms-DSP对5个尺度的输入图片提取DSP,然后取平均。DSP在对象识别、场景识别、动作识别等数据集上都取得较好的结果。
对原输入图像构建多分辨率金字塔, MOP-CNN则是对输入图像使用滑动窗口法来获取多个尺度的信息。此外,Gao等提出了一个新的特征标准化方法:2-范数矩阵标准化(L2 matrix normalization),使用图片所有卷积层特征形成的矩阵的谱范数来对特征进行标准化。2-范数矩阵标准化使用了来自整幅图像的信息,可以捕获一些全局信息,对光照和尺度变化等更具有较强的抵抗力。Gao等发现,当FV的K在1~4之间时(基于SIFT的FV使用的K值通常位于64~ 256),DSP即可取得最优的结果。如此小的K值将极大的减小DSP的维度。极小的K值之所以有效,Gao等认为是由于从卷积层提取的局部特征太少了(100个左右),不足以用于准确估计较大的GMM模型。为了进一步捕获多个尺度的信息,Gao等提出了DSP的一个多尺度版本-Multi-scale DSP(Ms-DSP)。Ms-DSP对5个尺度的输入图片提取DSP,然后取平均。DSP在对象识别、场景识别、动作识别等数据集上都取得较好的结果。
在进行细粒度图片是识别时,总是要用到部件或对象级别的标注来构建基于部件的图片表示,这造成了很多的不便。Zhang等提出了SWFV-CNN(Spatially Weighted FV based on CNN feature)![]() 描述符以解决此问题, SWFV-CNN不管是在训练阶段,还是在测试阶段都不需要部件或对象级别的标注,节省了很多人工工作。SWFV-CNN主要由两步构成:(1)寻找区分力强的卷积层滤波器。Zhang等基于CNN的卷积层特征图来选择对特定模式敏感的滤波器,因为卷积层滤波器在低层对边/角响应,而在高层则对语义相似的区域响应较为强烈。卷积层滤波器在一定程度上就如部件检测子一样。(2)Zhang等提出一个“部件显著性图(part saliency map)”,用于对描述符进行加权,此即为SWFV(Spatially Weighted FV)。“部件显著性图”表示了对象的存在概率。Zhang等将SWFV-CNN与全连接层特征融合,在细粒度分类数据集上的准确率甚至超过了使用部件/对象级别标注的方法。
描述符以解决此问题, SWFV-CNN不管是在训练阶段,还是在测试阶段都不需要部件或对象级别的标注,节省了很多人工工作。SWFV-CNN主要由两步构成:(1)寻找区分力强的卷积层滤波器。Zhang等基于CNN的卷积层特征图来选择对特定模式敏感的滤波器,因为卷积层滤波器在低层对边/角响应,而在高层则对语义相似的区域响应较为强烈。卷积层滤波器在一定程度上就如部件检测子一样。(2)Zhang等提出一个“部件显著性图(part saliency map)”,用于对描述符进行加权,此即为SWFV(Spatially Weighted FV)。“部件显著性图”表示了对象的存在概率。Zhang等将SWFV-CNN与全连接层特征融合,在细粒度分类数据集上的准确率甚至超过了使用部件/对象级别标注的方法。
2.3.1 串连
为了同时利用局部特征与全局特征,以增强特征的区分力与抗噪性能,Sun等提出了OR![]() 。Sun等首先利用BING(BInarized Normed Gradients, 二值化梯度范数)
。Sun等首先利用BING(BInarized Normed Gradients, 二值化梯度范数)![]() 来获取图像分片(BING不仅检测率高,而且检测速度相当快,在一台笔记本电脑上的速度达到了300fps);从每一个分片提取一个VLAD描述符(用SIFT生成)和一个CNN描述符(全连接特征),PCA-whitening后串连起来即为OR描述符。Sun等进一步利用积量化和倒排索引来加速检索,以适应大规模数据集。
来获取图像分片(BING不仅检测率高,而且检测速度相当快,在一台笔记本电脑上的速度达到了300fps);从每一个分片提取一个VLAD描述符(用SIFT生成)和一个CNN描述符(全连接特征),PCA-whitening后串连起来即为OR描述符。Sun等进一步利用积量化和倒排索引来加速检索,以适应大规模数据集。
SIFT自从被提出以来,由于其对尺度、旋转、平移的不变性,具有强大的描述能力,而且计算速度也很快,被广泛应用于计算机视觉的各个领域。但是,近年来CNN在各个领域都取得当前最先进的结果,那么我们是否可以抛弃SIFT直接使用CNN特征呢?Yan等认为,SIFT与CNN是互补的关系,并提出了CCS(Complementary CNN and SIFT)![]() 描述符来融合SIFT与CNN特征。CCS是一种多层表示,融合了多个层次的信息:(1)场景层。场景层代表的是高层的语义信息,提取GoogLeNet的pool5层作为此层的表示。(2)对象层。利用EdgeBox
描述符来融合SIFT与CNN特征。CCS是一种多层表示,融合了多个层次的信息:(1)场景层。场景层代表的是高层的语义信息,提取GoogLeNet的pool5层作为此层的表示。(2)对象层。利用EdgeBox![]() 提取图像分片, 选取得分最高的前100个分片,从每一个分片提取pool5层的特征,然后用于生成VLAD。(3)点层。利用SIFT生成VLAD。融合SIFT可以有效的提高描述符的几何不变性。CCS利用PCA将VLAD降到1024维,然后将3个层次的描述符串连起来并进行归一化,进行PCA-whitening处理,再归一化后即为最终的CCS描述符。CCS在Oxford数据集、Paris数据集和UKB数据集上取得了优于SPoC, MOP_CNN, OLDFP的准确率,证明融合SIFT与CNN的有效性。不过,CCS的VLAD的码书很大,取的是500(一般的情况下只取64~256),这么大的码书会导致VLAD的维度很高,PCA矩阵的计算将比较困难。
提取图像分片, 选取得分最高的前100个分片,从每一个分片提取pool5层的特征,然后用于生成VLAD。(3)点层。利用SIFT生成VLAD。融合SIFT可以有效的提高描述符的几何不变性。CCS利用PCA将VLAD降到1024维,然后将3个层次的描述符串连起来并进行归一化,进行PCA-whitening处理,再归一化后即为最终的CCS描述符。CCS在Oxford数据集、Paris数据集和UKB数据集上取得了优于SPoC, MOP_CNN, OLDFP的准确率,证明融合SIFT与CNN的有效性。不过,CCS的VLAD的码书很大,取的是500(一般的情况下只取64~256),这么大的码书会导致VLAD的维度很高,PCA矩阵的计算将比较困难。
为了利用多种互补的特征,Ge等![]() 提出利用稀疏编码
提出利用稀疏编码![]() 来对不同的特征进行编码,然后串连起来以达到融合的目的,此描述符在此处称之为“稀疏编码的特征(Sparse-Coded Features,SCF)”
来对不同的特征进行编码,然后串连起来以达到融合的目的,此描述符在此处称之为“稀疏编码的特征(Sparse-Coded Features,SCF)”![]() 。对于每一种特征,Ge等先利用稀疏编码方法来生成特征的稀疏编码, 然后利用max-pooling对稀疏编码进行聚合。Ge等研究了特征的检测子与描述子的组合问题,提出利用Harris-DAISY
。对于每一种特征,Ge等先利用稀疏编码方法来生成特征的稀疏编码, 然后利用max-pooling对稀疏编码进行聚合。Ge等研究了特征的检测子与描述子的组合问题,提出利用Harris-DAISY![]() 和LOG-SIFT两种局部特征描述符。另外,Ge等还提出了一种新局部颜色描述符micro。micro的提取过程如下:(1)密集采样(dense sampling)。(2)提取CIE-Lab颜色空间大小为k*k的图像分片。对每一个分片,将3通道像素串联,形成的特征即为micro特征。利用“稀疏编码+max-pooling”对所有分片的micro特征进行编码,就形成了一个新的颜色描述符-Sparse-coded micro feature (SCMF)。micro特征利用了图片的自相似性。将Harris-DAISY, LOG-SIFT和micro 3个特征的稀疏编码描述符串连起来就是最终的融合描述符。Ge等还研究了用PCA和积量化对此描述符进行压缩以用于大规模图像检索的情形。实验表明,此描述符要优于VLAD,FV以及颜色袋(Bag-of-Color, BOC)
和LOG-SIFT两种局部特征描述符。另外,Ge等还提出了一种新局部颜色描述符micro。micro的提取过程如下:(1)密集采样(dense sampling)。(2)提取CIE-Lab颜色空间大小为k*k的图像分片。对每一个分片,将3通道像素串联,形成的特征即为micro特征。利用“稀疏编码+max-pooling”对所有分片的micro特征进行编码,就形成了一个新的颜色描述符-Sparse-coded micro feature (SCMF)。micro特征利用了图片的自相似性。将Harris-DAISY, LOG-SIFT和micro 3个特征的稀疏编码描述符串连起来就是最终的融合描述符。Ge等还研究了用PCA和积量化对此描述符进行压缩以用于大规模图像检索的情形。实验表明,此描述符要优于VLAD,FV以及颜色袋(Bag-of-Color, BOC)![]() 。虽然此稀疏编码特征在UKB上超越了当时的其它方法,但是,在Holidays数据集上要逊色于LBOC(Local BoC)
。虽然此稀疏编码特征在UKB上超越了当时的其它方法,但是,在Holidays数据集上要逊色于LBOC(Local BoC)![]() 和HE。
和HE。
简单的串连会增加特征的维度,Yeh等提出用MKL来融合来自不同域的特征,此法称之为GL-MKL (Group Lasso Muti-Kernel Learning)![]() 。GL-MKL使每种特征对应多个核,以每种特征作为一个组。GL-MKL混合使用-范数约束和-范数约束(称为-norm约束),以作为一个组lasso约束子(group lasso regularizer)。GL-MKL使用MKL来学习每个组中核的权值。组lasso约束子增强了组间的稀疏性, 但组内却不用是稀疏的。组间稀疏性使得仅有少数区分力强的特征被使用, 所以GL-MKL也是一种特征选择方法。Yeh等将GL-MKL用于视频物体分类和图片分类。在处理视频物体分类问题时,使用了MFCC (Mel-frequency cepstral coefficient,梅尔频率倒谱系数)音频特征,SIFT特征,HOG特征,Gabor 滤波器
。GL-MKL使每种特征对应多个核,以每种特征作为一个组。GL-MKL混合使用-范数约束和-范数约束(称为-norm约束),以作为一个组lasso约束子(group lasso regularizer)。GL-MKL使用MKL来学习每个组中核的权值。组lasso约束子增强了组间的稀疏性, 但组内却不用是稀疏的。组间稀疏性使得仅有少数区分力强的特征被使用, 所以GL-MKL也是一种特征选择方法。Yeh等将GL-MKL用于视频物体分类和图片分类。在处理视频物体分类问题时,使用了MFCC (Mel-frequency cepstral coefficient,梅尔频率倒谱系数)音频特征,SIFT特征,HOG特征,Gabor 滤波器![]() 和EDH(Edge Direction Histogram,边缘方向直方图)
和EDH(Edge Direction Histogram,边缘方向直方图)![]() 。实验结果表明,GL-MKL要优于 LP-β
。实验结果表明,GL-MKL要优于 LP-β![]() 。本质上,GL-MKL可以看成是LPBoosting的进一步推广,引入了组稀疏性的概念。
。本质上,GL-MKL可以看成是LPBoosting的进一步推广,引入了组稀疏性的概念。
Xie等对Graph Fusion![]() 进行改进,提出了对排序敏感的图融合(Rank-aware graph fusion, RA-GraphFusion)
进行改进,提出了对排序敏感的图融合(Rank-aware graph fusion, RA-GraphFusion)![]() 。RA-GraphFusion主要提出:(1)特征层: 上下文不相似性度量(Contextual Dissimilarity Measurement ,CDM)。CDM以描述符为顶点建立一个全连接图,以描述体符间的距离来表示边的权值。以此策略可以校正距离函数,进而校正边的权值。(2)排序层: 排序衰减系数(Rank Decay Coefficient,RDC)。RDC利用了检索引过程中的排序信息进一步校正边的权值。利用SIFT与CNN(AlexNet)特征(全连接层特征)的融合来进行实验,在Holidays与UKB数据集上证明了CDM和RDC两种策略的有效性。
。RA-GraphFusion主要提出:(1)特征层: 上下文不相似性度量(Contextual Dissimilarity Measurement ,CDM)。CDM以描述符为顶点建立一个全连接图,以描述体符间的距离来表示边的权值。以此策略可以校正距离函数,进而校正边的权值。(2)排序层: 排序衰减系数(Rank Decay Coefficient,RDC)。RDC利用了检索引过程中的排序信息进一步校正边的权值。利用SIFT与CNN(AlexNet)特征(全连接层特征)的融合来进行实验,在Holidays与UKB数据集上证明了CDM和RDC两种策略的有效性。
Liu等![]() 认为GraphFusion方法易受离群图片(outliers)的影响,因为:(1)特征。并不是所有特征都是有效的,无效特征会引入离群图片;(2)K近邻数。GraphFusion使用的是K-互近邻,K值理论上应当与查询图片的真实相关图片(groundtruth)数相等,但每张查询图片的相关图片数是不一样的,这意味着K并非对所有查询图片都是最优的,如果K大于相关图片数,就会引入离群图片。鉴于此,Liu等提出了一个更不易受离群图片影响的方法-ImageGraph
认为GraphFusion方法易受离群图片(outliers)的影响,因为:(1)特征。并不是所有特征都是有效的,无效特征会引入离群图片;(2)K近邻数。GraphFusion使用的是K-互近邻,K值理论上应当与查询图片的真实相关图片(groundtruth)数相等,但每张查询图片的相关图片数是不一样的,这意味着K并非对所有查询图片都是最优的,如果K大于相关图片数,就会引入离群图片。鉴于此,Liu等提出了一个更不易受离群图片影响的方法-ImageGraph![]() 。ImageGraph是GraphFusion方法的改进版,与GraphFusion方法有如下不同:(1)图。GraphFusion用的是K-互近邻图,而ImageGraph用的是一个单向K-近邻图(仅含出边,指向K-近邻)。K-近邻图的结点数比K-互近邻图的结点数更多,可以提高检索的查全率。(2)相关性度量。Liu等提出一个被称为Rank Distance的方法来度量两幅图片的相关程度。Rank Distance 利用了两幅图片的排序,不易受离群图片的影响。(3)相似性度量。GraphFusion用的是Jaccard相似性,ImageGraph的相似性度量方法称之为“贝叶斯相似性”,是基于Rank Distance方法求的概率模型。(3)排序方法。GraphFusion的排序方法可能会导致不相关的图片间有很多边。ImageGraph的方法称为“Local Ranking”。Local Ranking旨在寻找一个最大加权子图,是一个局部最优的方法,而非全局最优,以避免被紧密相连的离群图片影响。ImageGraph用到了SIFT,GIST,HSV和CNN特征,并在Holidays和UKB数据集上取得了优于GraphFusion和“查询自适应晚期融合”
。ImageGraph是GraphFusion方法的改进版,与GraphFusion方法有如下不同:(1)图。GraphFusion用的是K-互近邻图,而ImageGraph用的是一个单向K-近邻图(仅含出边,指向K-近邻)。K-近邻图的结点数比K-互近邻图的结点数更多,可以提高检索的查全率。(2)相关性度量。Liu等提出一个被称为Rank Distance的方法来度量两幅图片的相关程度。Rank Distance 利用了两幅图片的排序,不易受离群图片的影响。(3)相似性度量。GraphFusion用的是Jaccard相似性,ImageGraph的相似性度量方法称之为“贝叶斯相似性”,是基于Rank Distance方法求的概率模型。(3)排序方法。GraphFusion的排序方法可能会导致不相关的图片间有很多边。ImageGraph的方法称为“Local Ranking”。Local Ranking旨在寻找一个最大加权子图,是一个局部最优的方法,而非全局最优,以避免被紧密相连的离群图片影响。ImageGraph用到了SIFT,GIST,HSV和CNN特征,并在Holidays和UKB数据集上取得了优于GraphFusion和“查询自适应晚期融合”![]() 的结果。
的结果。
从IMI (Inverted Multi-Index)![]() 得到启发,Zheng等提出了耦合多维索引 (coupled Multi-Index, c-MI)
得到启发,Zheng等提出了耦合多维索引 (coupled Multi-Index, c-MI)![]() , 对SIFT和CN
, 对SIFT和CN![]() 颜色特征在索引层次进行了融合。c-MI是一个二维索引,以SIFT和CN分别作为索引的一维。SIFT和CN分别对应一个码书,它们的每一个码字组合对应一个倒排列表。查询时,取出码字组合对应的倒排列表,tf-idf及CN的二进制签名计算相似度。Zheng等将c-MI的策略总结为packing(装箱)和padding(填补):“packing”是指以SIFT和CN分别作为索引的一维;”padding” 则是指使用一些别的策略来进一步提高检索的准确率与查全率。具体padding的内容有:(1)MA(Multiple Assignment,多分配)。取多个近邻的倒排列表以提高查全率。(2)SIFT的HE二进制签名;(3)burstiness 加权
颜色特征在索引层次进行了融合。c-MI是一个二维索引,以SIFT和CN分别作为索引的一维。SIFT和CN分别对应一个码书,它们的每一个码字组合对应一个倒排列表。查询时,取出码字组合对应的倒排列表,tf-idf及CN的二进制签名计算相似度。Zheng等将c-MI的策略总结为packing(装箱)和padding(填补):“packing”是指以SIFT和CN分别作为索引的一维;”padding” 则是指使用一些别的策略来进一步提高检索的准确率与查全率。具体padding的内容有:(1)MA(Multiple Assignment,多分配)。取多个近邻的倒排列表以提高查全率。(2)SIFT的HE二进制签名;(3)burstiness 加权![]() ; 消除“视觉爆发现象”。(4)Graph Fusion。可以利用Graph Fusion将c-MI的结果与HSV的结果进行融合。c-MI在Holidays、UKB等图像检索公共数据集上取得了当时最好的结果。c-MI不仅时空开销较小,而且还可以进一步与其他的特征融合,不过索引的维度越高,倒排列表将会越稀疏,要提高查全率与准确率就要访问更多的倒排列表。
; 消除“视觉爆发现象”。(4)Graph Fusion。可以利用Graph Fusion将c-MI的结果与HSV的结果进行融合。c-MI在Holidays、UKB等图像检索公共数据集上取得了当时最好的结果。c-MI不仅时空开销较小,而且还可以进一步与其他的特征融合,不过索引的维度越高,倒排列表将会越稀疏,要提高查全率与准确率就要访问更多的倒排列表。
为了有效的同时利用SIFT和CNN特征,Zhou等提出了“协同索引嵌入(Collaborative Index Embedding,CIE)![]() 。CIE利用索引矩阵对SIFT和CNN的两个特征空间的图片近邻结构进行相互迭代校正,使两个特征空间的近邻结构尽可能相似。由于两个特征空间的近邻结构接近,所以最后在查询时,只需CNN特征即可。CIE是一个迭代优化的过程,SIFT和CNN特征被隐式的融合在索引中。CIE在优化时采用了一种非对称的互近邻域:图片I属于图片J的K-近邻域,而图片J可能属于图片I的P-近邻域。此种非对称近邻域更不易受噪声影响。CIE将CNN(AlexNet)的两个全连接层特征串连起来以作为CNN特征,并通过域值化对其进行了稀疏化处理,以适应于索引,减少索引开销,加快查询速度。CIE在Holidays与UKB数据集上取得了与“查询自适应晚期融合”
。CIE利用索引矩阵对SIFT和CNN的两个特征空间的图片近邻结构进行相互迭代校正,使两个特征空间的近邻结构尽可能相似。由于两个特征空间的近邻结构接近,所以最后在查询时,只需CNN特征即可。CIE是一个迭代优化的过程,SIFT和CNN特征被隐式的融合在索引中。CIE在优化时采用了一种非对称的互近邻域:图片I属于图片J的K-近邻域,而图片J可能属于图片I的P-近邻域。此种非对称近邻域更不易受噪声影响。CIE将CNN(AlexNet)的两个全连接层特征串连起来以作为CNN特征,并通过域值化对其进行了稀疏化处理,以适应于索引,减少索引开销,加快查询速度。CIE在Holidays与UKB数据集上取得了与“查询自适应晚期融合”![]() 以及ONE
以及ONE![]() 相当的准确率。
相当的准确率。
2.3.5 得分层融合(Score-level fusion)
在利用多个特征进行检索时,对于给定的特征,并不知道哪些特征是有效的,哪些特征是无效的,所以应当开发一种自适应查询的方法。Zheng等提出了一种得分层(score-level)多特征融合方法-查询自适应晚期融合(query adaptive late fusion)![]() 。Zheng等的动机在于他们发现:对于一个好的特征而言,其排序后的score曲线应该是L型的(先快速下降,然后趋于平稳),而不好的特征的score曲线是逐渐下降的。“查询自适应晚期融合”主要有两个特点:(1)以查询自适应的方式估计特征的有效性。各特征的权值是不固定的,不易受无效特征的不良影响。(2)特征的有效性是利用无关数据集在线估计的,不依赖数据库本身,可以适应大规模数据库的动态变化。Zheng等利用不相关的数据集近似数据库图片上的score曲线的尾部,用特征的score曲线减去此尾部以突出top-k图片的作用,此score曲线与坐标轴围成的面积的倒数便反映了特征的好坏(或有效性)。以此面积的倒数作为对应特征的权值以计算相似度。Zheng等共利用了5种特征:SIFT、HSV、CaffeNet
。Zheng等的动机在于他们发现:对于一个好的特征而言,其排序后的score曲线应该是L型的(先快速下降,然后趋于平稳),而不好的特征的score曲线是逐渐下降的。“查询自适应晚期融合”主要有两个特点:(1)以查询自适应的方式估计特征的有效性。各特征的权值是不固定的,不易受无效特征的不良影响。(2)特征的有效性是利用无关数据集在线估计的,不依赖数据库本身,可以适应大规模数据库的动态变化。Zheng等利用不相关的数据集近似数据库图片上的score曲线的尾部,用特征的score曲线减去此尾部以突出top-k图片的作用,此score曲线与坐标轴围成的面积的倒数便反映了特征的好坏(或有效性)。以此面积的倒数作为对应特征的权值以计算相似度。Zheng等共利用了5种特征:SIFT、HSV、CaffeNet![]() 全连接层特征、GIST和随机特征。GIST与随机特征主要作为无效特征,以测试算法的健壮性。实验表明,“查询自适应晚期融合”要优于图融合和索引层次融合的协同索引
全连接层特征、GIST和随机特征。GIST与随机特征主要作为无效特征,以测试算法的健壮性。实验表明,“查询自适应晚期融合”要优于图融合和索引层次融合的协同索引![]() 。
。
BOW仅使用SIFT特征来进行匹配,而SIFT特征仅代表了局部的信息,忽视了其它的信息,而且被量化到同一个视觉单词的特征即认为是匹配的,这会导致大量的虚假匹配(false match)。Zheng等![]() 认为,一对关键点要成为真实匹配(true match), 需要在local/regional/global 3个层次上匹配。为达到这一目的,Zheng等提出了一个DeepEmbedding
认为,一对关键点要成为真实匹配(true match), 需要在local/regional/global 3个层次上匹配。为达到这一目的,Zheng等提出了一个DeepEmbedding![]() 框架,利用3个层次的信息来为匹配过程建立一个概率模型,此模型就是CNN特征与SIFT的融合模型。Zheng等利用空间金字塔 来对图像划分,总共分为3个尺度(1*1, 4*4, 8*8),除global尺度外,剩下的两个尺度用于region层。global层与region层均由Decaf网络的全连接层特征来描述,而local层则用SIFT来描述,region信息与global信息被称之为SIFT特征点的上下文环境。Zheng等还提出一个DeepIndexing的索引结构,仅在索引中存放SIFT的HE签名与regional、global特征的指针,而regional与global特征的LSH(Locality Sensitive Hashing,局部敏感哈希)
框架,利用3个层次的信息来为匹配过程建立一个概率模型,此模型就是CNN特征与SIFT的融合模型。Zheng等利用空间金字塔 来对图像划分,总共分为3个尺度(1*1, 4*4, 8*8),除global尺度外,剩下的两个尺度用于region层。global层与region层均由Decaf网络的全连接层特征来描述,而local层则用SIFT来描述,region信息与global信息被称之为SIFT特征点的上下文环境。Zheng等还提出一个DeepIndexing的索引结构,仅在索引中存放SIFT的HE签名与regional、global特征的指针,而regional与global特征的LSH(Locality Sensitive Hashing,局部敏感哈希)![]() 签名则统一放在外部的表格中,因为同一张图片的SIFT共享相同的region特征与global特征。与MA等策略相结合,DeepEmbedding在Holidays、UKB等数据集上取得了优于在索引层次融合SIFT与颜色特征的c-MI的性能。
签名则统一放在外部的表格中,因为同一张图片的SIFT共享相同的region特征与global特征。与MA等策略相结合,DeepEmbedding在Holidays、UKB等数据集上取得了优于在索引层次融合SIFT与颜色特征的c-MI的性能。
浅层描述符(主要指利用SIFT等局部特征生成的描述符)主要包括提取与编码两个步骤(这两个步骤对深度特征同样适用,因为深度特征使用了浅层特征编码方法),先提取局部特征,再编码为全局描述符。局部特征主要有两个要求:(1)不变性。提取的特征要不易受平移、旋转、伸缩、视点变化及杂乱(occlusion)场景等因素的影响。局部特征通常来自图片的视觉敏感区域。几何不变性强的特征的区分力才足够强。(2)速度。因为局部特征的数目通常较多,所以速度要足够快,否则达不到实际应用的要求。只有满足这两点,才能在理论与实际生产中被广泛使用。不过SIFT存在两个问题:(1)视觉爆发现象![]() :大量的特征被分配到少量的视觉单词。对于具有自相似性的纹理图片而言,不少SIFT从2-范数距离意义上来讲是很相似的,这会导致匹配时的假正(false positive)现象。(2)视觉并发现象
:大量的特征被分配到少量的视觉单词。对于具有自相似性的纹理图片而言,不少SIFT从2-范数距离意义上来讲是很相似的,这会导致匹配时的假正(false positive)现象。(2)视觉并发现象![]() :码字的出现并不是相互独立的。这两个问题通常在编码阶段被处理,如VLAD为了处理“视觉爆发现象”采用的内部标准化策略与IFV采用的幂律标准化策略。“视觉并发现象”通常采用PCA-whitening
:码字的出现并不是相互独立的。这两个问题通常在编码阶段被处理,如VLAD为了处理“视觉爆发现象”采用的内部标准化策略与IFV采用的幂律标准化策略。“视觉并发现象”通常采用PCA-whitening![]() 来处理。虽然都很有效,不过并没有谁找到一种最优的方法来处理这两个问题,而且这两种现象和数据集类型有很大的关系。编码方法通常分为两个步骤:(1)嵌入。将低维局部特征嵌入(或映射)到高维空间。此过程通常是为了采集局部特征分布的统计信息。如BOF只含有0阶统计信息(频数),VLAD含有1阶统计信息(均值),FV含有1阶(均值)和2阶(方差)的统计信息。不过,目前这些编码方法基本上都是基于局部特征的分布属性的方法,而且这些分布属性基本上是采用k-means、GMM等非监督聚类方法得到的。k-means等方法是基于2-范数距离的,由于“维度灾难(curse-of-dimensionality)”
来处理。虽然都很有效,不过并没有谁找到一种最优的方法来处理这两个问题,而且这两种现象和数据集类型有很大的关系。编码方法通常分为两个步骤:(1)嵌入。将低维局部特征嵌入(或映射)到高维空间。此过程通常是为了采集局部特征分布的统计信息。如BOF只含有0阶统计信息(频数),VLAD含有1阶统计信息(均值),FV含有1阶(均值)和2阶(方差)的统计信息。不过,目前这些编码方法基本上都是基于局部特征的分布属性的方法,而且这些分布属性基本上是采用k-means、GMM等非监督聚类方法得到的。k-means等方法是基于2-范数距离的,由于“维度灾难(curse-of-dimensionality)”![]() 的存在,高维向量在欧氏空间具有高度的相似性,不易区分,因而2-范数距离并非最优的。而且高维向量中通常含有大量的信息冗余。将高难空间映射到低维空间来处理从一定程度上能缓解此问题,然而降维会造成部分有用信息的损失。(2)汇聚。局部特征的数目通常非常多,而且会随图片的大小与特征的类型而变化,sum-pooling(通常是加权平均)在编码方法中被广泛的使用,以消除特征数目的影响;而max-pooling则在对CNN的卷积层汇聚时用的最多,因为max-pooling对微小的变化具有一定的不变性。不同的局部特征(SIFT/CNN卷积层特征)来自不同的位置,描述能力(或区分力)也不一样,因而对特征加权是现在经常使用并且在将来还会继续被广泛使用的策略。
的存在,高维向量在欧氏空间具有高度的相似性,不易区分,因而2-范数距离并非最优的。而且高维向量中通常含有大量的信息冗余。将高难空间映射到低维空间来处理从一定程度上能缓解此问题,然而降维会造成部分有用信息的损失。(2)汇聚。局部特征的数目通常非常多,而且会随图片的大小与特征的类型而变化,sum-pooling(通常是加权平均)在编码方法中被广泛的使用,以消除特征数目的影响;而max-pooling则在对CNN的卷积层汇聚时用的最多,因为max-pooling对微小的变化具有一定的不变性。不同的局部特征(SIFT/CNN卷积层特征)来自不同的位置,描述能力(或区分力)也不一样,因而对特征加权是现在经常使用并且在将来还会继续被广泛使用的策略。
SIFT虽然具有很强的几何不变性,但是其本身缺乏几何信息(如尺度、方向、位置),所以通常通过增强几何信息来增强区分力。目前主要通过3种策略来达到这一目的:(1)SIFT层。扩展SIFT描述符,将几何信息串连在SIFT后面。(2)编码层。如gVLAD![]() , 利用SIFT的主方向来生成包含方向信息的VLAD。(3)索引层(或score层)。如HE(Hamming Embedding)
, 利用SIFT的主方向来生成包含方向信息的VLAD。(3)索引层(或score层)。如HE(Hamming Embedding)![]() 使用尺度与角度信息来校正相似度,HE将其称之为“弱几何一致性(Weak Geometric Consistency, WGC)”。有“弱”就有强,强几何一致性通常通过仿射匹配来达到, 称之为“空间验证(Spatial Verification,SV)”
使用尺度与角度信息来校正相似度,HE将其称之为“弱几何一致性(Weak Geometric Consistency, WGC)”。有“弱”就有强,强几何一致性通常通过仿射匹配来达到, 称之为“空间验证(Spatial Verification,SV)”![]() 。SV同时考虑了位置、尺度、方向3个因子,利用它们来建立仿射模型,利用RANSAC(RANdom SAmple Consensus)
。SV同时考虑了位置、尺度、方向3个因子,利用它们来建立仿射模型,利用RANSAC(RANdom SAmple Consensus)![]() 来迭代校正模型,最后用仿射模型来验证图片的几何一致性。不过, RANSAC只能用在两个集合之间,只适合局部特征,并不适合全局特征,因为一幅图片只能生成一个全局特征,所以SV通常用于SIFT-BOW模型。所以,全局特征目前缺乏强几何一致性的验证方法,一般只能通过编码来包含少量的几何信息,或者通过空间金字塔
来迭代校正模型,最后用仿射模型来验证图片的几何一致性。不过, RANSAC只能用在两个集合之间,只适合局部特征,并不适合全局特征,因为一幅图片只能生成一个全局特征,所以SV通常用于SIFT-BOW模型。所以,全局特征目前缺乏强几何一致性的验证方法,一般只能通过编码来包含少量的几何信息,或者通过空间金字塔![]() 来达到。但空间金字塔会使得描述符的维度成倍增加,在大规模的情况下,会增加不少的时空开销。
来达到。但空间金字塔会使得描述符的维度成倍增加,在大规模的情况下,会增加不少的时空开销。
卷积层特征与SIFT相比,有如下特点:(1)卷积层特征类似于密集SIFT特征(通过网格式的密集采样得到)。卷积层特征与SIFT一样是局部特征,对应了图片的某个区域(可以将CNN特征图上每一个点反向映射回图片), 是一种局部特征。(2)卷积层特征是通过学习得到的,SIFT是手工类型。CNN的卷积层参数是可以针对不同的数据集通过迭代训练调优的,而且可通过简单的修改进一步改进(如增加深度、宽度等)而SIFT的参数是通过预先的精密设计固定的。(3)卷积层特征具有层次性。不同的卷积层具有不同的语义层次![]() ,如浅层的特征图通常是一些边/角等,而中层则是物体的一部分,高层则通常是一个完整的物体。选用不同的层将可能达到完全不同的效果,该如何选择一个最优的层则到目前为止还没有一个最优的方法,通常通过测试多层的效果来达到。SIFT在不使用SP的情况下不具有层次性,描述的是边/角等比较低层次的特征,这也是为什么CCS
,如浅层的特征图通常是一些边/角等,而中层则是物体的一部分,高层则通常是一个完整的物体。选用不同的层将可能达到完全不同的效果,该如何选择一个最优的层则到目前为止还没有一个最优的方法,通常通过测试多层的效果来达到。SIFT在不使用SP的情况下不具有层次性,描述的是边/角等比较低层次的特征,这也是为什么CCS![]() 将SIFT与CNN融合会有效果的原因之一。(4)CNN卷积层特征维度比SIFT/SURF等浅层特征要大得多,而且计算量大,需要GPU辅助才能达到实时的效果,而且因为要存储很多卷积层特征图的原因,空间开销也要大得多。对于PC机而言,这不是什么大问题,然而未来的AI将可能无处不在,CNN在移动平台上的使用将成为一个具有挑战性的问题。随着类脑计算
将SIFT与CNN融合会有效果的原因之一。(4)CNN卷积层特征维度比SIFT/SURF等浅层特征要大得多,而且计算量大,需要GPU辅助才能达到实时的效果,而且因为要存储很多卷积层特征图的原因,空间开销也要大得多。对于PC机而言,这不是什么大问题,然而未来的AI将可能无处不在,CNN在移动平台上的使用将成为一个具有挑战性的问题。随着类脑计算![]() 如火如荼的展开,各种神经处理专用芯片(如中科院陈云霁等研发的DaDianNao
如火如荼的展开,各种神经处理专用芯片(如中科院陈云霁等研发的DaDianNao![]() , Google最近研发的TPU
, Google最近研发的TPU![]() 等)不断涌现,此问题或者也将不是问题。
等)不断涌现,此问题或者也将不是问题。
尽管CNN特征目前在图像检索领域被广泛使用,但与SIFT相比,CNN特征在图像检索方面还存在如下不足:(1)通用性。SIFT可以被用于任意数据集,不需要考虑数据集的分布。而用ImageNet预训练的CNN特征则在通用性方面要差一些,目标数据集与ImageNet的差异越大,图像检索的性能就会越差。用与目标数据集相近的数据集重新训练CNN几乎是不可能的,因为这种带标签的大数据集一般是没有的,而小数据集会导致过拟合问题。故而此问题通常通过用与目标数据集相近的小数据集微调预训练的CNN来解决,然而哪怕是收集这种小数据集也很费事,因为还要人工标注。(2)几何不变性。CNN特征与SIFT这种局特征相比,在尺度、旋转、平移及光照变化等方面的不变性要差得多。虽然MOP_CNN![]() 通过串联3个尺度的VLAD增强了尺度不变性,MOP_CNN对于旋转、平移等因素的不变性却没有得到处理。也可以在源头解决CNN特征的不变性问题,那就是“数据增强”:将训练图片经过旋转、伸缩、平移等处理后的图片也加入训练集。不过这会使得训练的时空开销成倍增加。(3)特征数。从一幅图片一般可以提取几千个SIFT,即使是小图片,也可以通过密集采样得到数目众多的SIFT。而从一幅图片提取的CNN特征则很少:1个全连接层特征或几百个卷积层特征。一般通过生成很多图像分片来解决此问题,但每个分片要通过CNN一趟,会使CNN特征提取的开销大幅增加。
通过串联3个尺度的VLAD增强了尺度不变性,MOP_CNN对于旋转、平移等因素的不变性却没有得到处理。也可以在源头解决CNN特征的不变性问题,那就是“数据增强”:将训练图片经过旋转、伸缩、平移等处理后的图片也加入训练集。不过这会使得训练的时空开销成倍增加。(3)特征数。从一幅图片一般可以提取几千个SIFT,即使是小图片,也可以通过密集采样得到数目众多的SIFT。而从一幅图片提取的CNN特征则很少:1个全连接层特征或几百个卷积层特征。一般通过生成很多图像分片来解决此问题,但每个分片要通过CNN一趟,会使CNN特征提取的开销大幅增加。
针对CNN特征的不足,未来的特征及特征融合方法的趋势可能如下:(1)CNN架构。目前的CNN架构几乎都是用于图像分类问题的,然而图像分类问题与图像检索问题有很大的不同,图像检索是一个更细粒度的问题,更观注图像包含的局部视觉模式,检索算法对这种模式的区分力是一个图像检索问题的一个决定因素。增加CNN对图片模式的区分力,找到一种更适合图像检索的CNN架构是一个值得研究的问题。(2)几何不变性。CNN特征缺乏几何不变性,但目前研究者们对此问题进行处理的人比较少。增强CNN特征对尺度、旋转、平移及光照变化等各种因素的不变性,毫无疑问,将显著提升检索算法的准确率,然而时空开销的增加将不可避免。(3)特征融合。CNN特征缺乏不变性,在不改变其本身的情况下,可以通过融合不变性强的特征来解决此问题;再者,通过融合互补的多种特征可以有效的增加描述符的区分力。然而,特征的有效性及融合方法依然需要研究。“查询自适应晚期融合”![]() 通过研究Score曲线的形状来判定特征的有效性,然而此种方法的代价较大,能否找到一种在”早期“(比如编码阶段)就能判定特征是否有效的方法呢?
通过研究Score曲线的形状来判定特征的有效性,然而此种方法的代价较大,能否找到一种在”早期“(比如编码阶段)就能判定特征是否有效的方法呢?
4 致谢
本报告的撰写得到华中科技大学、浙江大学和清华大学相关研究团队研究人员的大力支持,特此致谢。
作者介绍
华中科技大学计算机科学与技术学院,教授,博士生导师,数字媒体处理与检索实验室主任,主要研究方向为数字视频分析与检索、多核计算与流编译、网络安全大数据处理。中国计算机学会多媒体专业委员会副主任。
![]()
华中科技大学计算机科学与技术学院博士生,研究兴趣包括图像检索、深度学习。
![]()
浙江大学教授、博士生导师。主要研究领域为人工智能、跨媒体计算、多媒体分析与检索和统计学习理论。浙江大学计算机学院副院长、浙江大学人工智能研究所所长。中国计算机学会多媒体专业委员会常务委员,国家杰出青年基金获得者。
![]()
清华大学计算机系长聘教授,博士生导师,网络多媒体北京市重点实验室副主任,中国计算机学会多媒体技术专委会秘书长,2012年入选“教育部新世纪优秀人才支持计划”。研究方向包括网络多媒体、视频编码、媒体大数据、智能媒体处理、社交媒体等。曾获IEEE TCSVT、ACM MM等4项最佳论文奖,省部级一等奖2项。
![]()
参考文献及更多内容请点击“阅读原文”访问CCF数字图书馆下载和浏览。
更多内容请点击“阅读原文”访问CCF数字图书馆下载和浏览。