低耗时、高精度,微软提出基于半监督学习的神经网络结构搜索算法 SemiNAS

编者按:近年来,神经网络结构搜索(Neural Architecture Search, NAS)取得了较大的突破,但仍然面临搜索耗时及搜索结果不稳定的挑战。为此,微软亚洲研究院机器学习组提出了基于半监督学习的神经网络结构搜索算法 SemiNAS ,能在相同的搜索耗时下提高搜索精度,以及在相同的搜索精度下减少搜索耗时。SemiNAS 可在 ImageNet(mobile setting) 上达到23.5%的 top-1 错误率和6.8%的 top-5 错误率。同时,SemiNAS 第一次将神经网络结构搜索引入文本到语音合成任务(Text to Speech, TTS)上,在低资源和鲁棒性两个场景下取得了效果提升。
NAS 在近些年取得了突破性进展,它通过自动化设计神经网络架构,在很多任务(如图像分类、物体识别、语言模型、机器翻译)上取得了比人类专家设计的网络更好的结果。
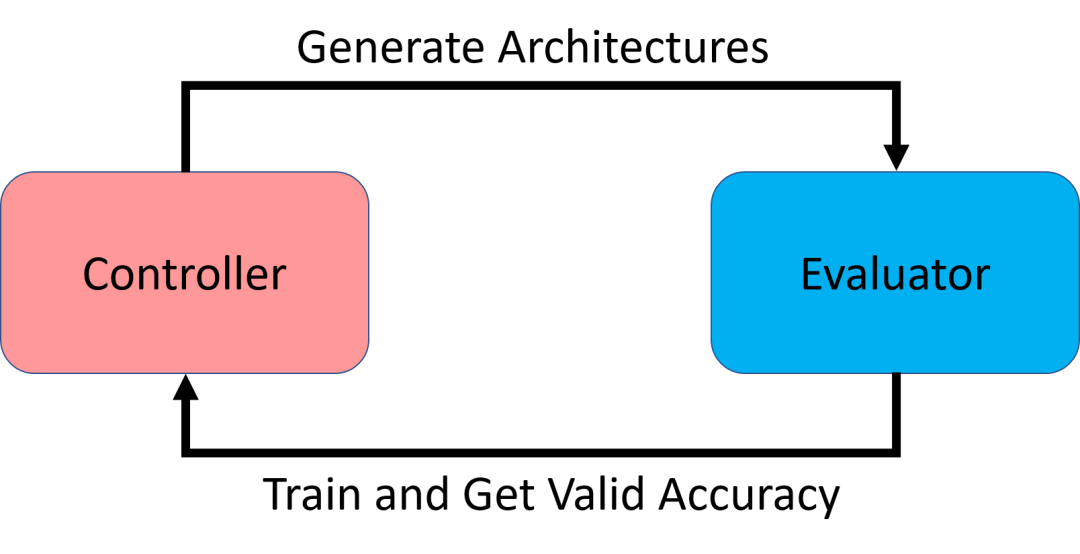
图1:NAS 框架示意
NAS 主要包括一个控制器(controller)和一个评估器(evaluator),其中控制器负责生成不同的网络结构,然后交由评估器进行评估,如图1所示。评估器需要对网络进行训练,然后获得其在目标任务验证数据集上的准确率,并返回给控制器。控制器利用网络结构及其对应的准确率进行学习,进而生成更好的网络结构。这一过程中,评估器对网络进行评估的过程非常耗时,因为它需要对每个网络结构进行训练,而控制器的学习又需要尽可能多的网络结构-准确率对作为训练数据,从而使得整个搜索过程中评估器的耗时非常高。之前的工作中,评估器的耗时在至少上百 GPU/day (等价于几百块 GPU 运行1天)。随后,研究者们提出了利用参数共享(weight-sharing)的 one-shot 神经网络结构搜索算法。具体来说就是构建一个超网络,包含了搜索空间中所有可能的结构,不同结构之间共享相同子结构的参数。训练超网络相当于同时训练了若干个网络结构。此方法直接将耗时降到了 10 GPU/day 以内,但是由于自身问题(如平均训练时间不足)导致网络结构的准确率和其真实准确率排序关系较弱,进而影响控制器的学习,难以稳定地搜索出很好的网络结构,甚至有时和随机搜索的效果差不多。
为了解决传统方法训练耗时高,而 one-shot 方法搜索不稳定性能较差的问题,微软亚洲研究院机器学习组的研究员们提出了基于半监督学习的神经网络结构搜索方法 SemiNAS,可以降低搜索耗时,同时提升搜索精度。
NAS 中的控制器利用大量的神经网络结构及其对应的准确率作为训练数据进行监督学习(supervised learning)。训练大量的网络结构直到收敛以获取其准确率是非常耗时的,但是获取无监督数据(即只有神经网络结构本身而没有对应的准确率)是非常容易的(例如随机生成网络结构)。因此,我们希望利用大量的易于获取的无监督数据(神经网络结构)来进一步帮助控制器的学习 ,这种方法称作半监督学习(semi-supervised learning)。这样做有两点好处:1. 提升性能:在几乎相同的训练代价(相同的有监督数据)下,可以利用大量的无监督数据来进一步提高搜索算法性能,以搜索出更好的网络结构;2. 降低时间:在达到相同搜索精度的情况下,通过利用大量的无监督数据,可以大大减少有监督数据的数量,以降低训练耗时。
为了利用大量的无标签的网络结构,先在少量的有标签的网络结构上进行学习,然后对无标签的网络结构进行标注(预测它们的准确率),然后把它们加入到原始训练数据中进行学习。具体而言,我们构建了一个性能预测器 f_p 来预测一个网络结构的准确率,它通过最小化 MSE 损失来训练,如公式1所示,其中 L_p 是损失:
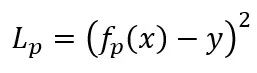
公式1
我们在有限的监督数据集上训练 f_p,待其收敛后,用其对无标签的神经网络结构 x' 进行预测,得到准确率 y'=f_p (x')。我们将预测得到的数据和原始的监督数据混合在一起进一步训练性能预测器 f_p 以达到更高的精度。
训练好的性能预测器 f_p 可以与多种 NAS 算法结合,为其预测网络结构的准确率以供其学习。比如对于基于强化学习的算法(如 NASNet [3],ENAS [6] 等)和基于进化算法的算法(如 AmoebaNet [4],Single Path One-Shot NAS [7] 等),f_p 可以用于为生成的候选网络结构预测准确率。对于基于梯度的算法(如 DARTS [5] 和NAO [1]),可以直接用 f_p 预测的网络结构的准确率对网络结构求导,更新网络结构。
本文中,我们基于之前的工作 NAO(Neural Architecture Optimization)[1],实现了 SemiNAS 搜索算法。NAO 主要包含一个编码器-性能预测器-解码器框架,编码器将离散的神经网络结构映射到连续空间中的向量表示,性能预测器用于预测其准确率,解码器负责将连续向量表示解码成离散的神经网络结构表示。在训练时,三者进行联合训练,性能预测器通过回归任务进行训练,解码器通过重建任务进行训练。在生成新网络结构时,我们输入一个网络结构,计算性能预测器对输入网络结构的梯度,通过梯度上升来获得一个更好的神经网络结构。更多关于 NAO 的介绍可参见原始论文。
结合本文提出的学习方法,在 SemiNAS 中,我们首先用少量有标签的数据训练整体框架,然后从搜索空间中采样获得大量无标签的神经网络结构,利用训练好的框架对这些网络结构预测准确率。然后使用原始的有标签的数据和自标注好的无标签数据一起充分训练整个框架。之后按照 NAO 中的方法进行优化,生成更好的网络结构。
我们在多个任务和数据集上验证了 SemiNAS 方法,包括图像分类(NASBench-101 [2]、ImageNet)和文本到语音合成 。值得一提的是,NAS 首次被应用于语音合成任务,并取得了不错的结果。
NASBench-101
首先,我们在 NASBench-101 [2] 数据集上进行了实验。NASBench-101 是一个开源的用于验证 NAS 算法效果的数据集,包含了 423k 个不同的网络结构和其在 CIFAR-10 分类任务上的准确率,即提供了一个开箱即用的评估器,方便研究者快速验证其搜索算法本身,并和其它工作进行公平对比(消除了不同训练技巧、随机种子及数据集本身带来的差异)。实验结果如表1所示。
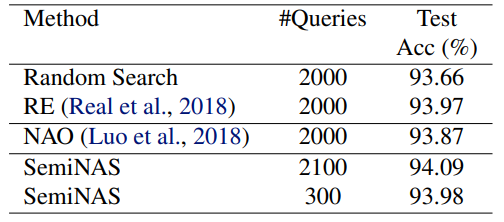
表1:不同方法在 NASBench-101 上的表现
在 NASBench-101 上,随机搜索方法(Random Search)、基于进化算法的方法(Regularized Evolution, RE)以及 NAO 在采样了2000个网络结构后分别取得了93.66%,93.97%和93.87%的平均测试准确率。而 SemiNAS 在仅采样了300个网络结构后就取得了93.98%的平均测试准确率,在取得和 RE 和 NAO 一样性能的同时,大大减少了所需资源。进一步地,当采样几乎差不多的网络结构(2100个)时,SemiNAS 取得94.09%的平均测试准确率,超过了其他的搜索方法。
ImageNet
我们进一步在更大的 ImageNet 分类任务上验证 SemiNAS 的表现,搜索过程中我们仅实际训练评估了400个结构,最终结果如表2所示。
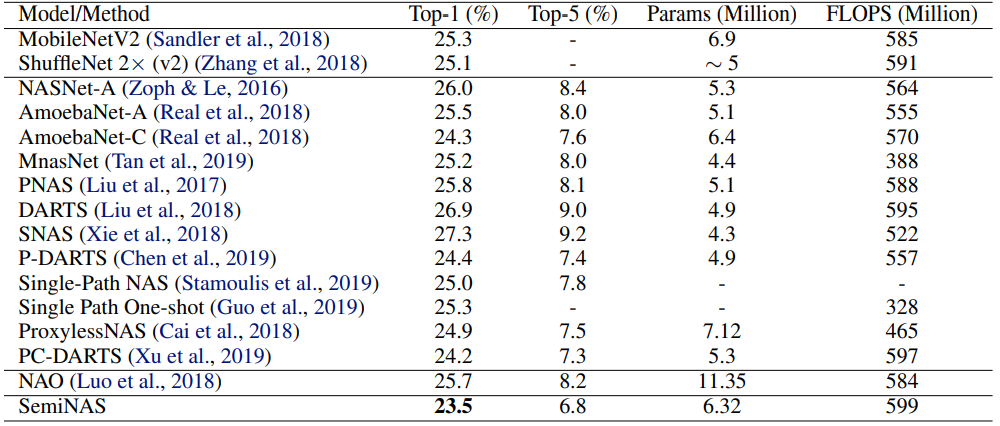
表2:不同方法在 ImageNet 分类任务上的性能
在 mobile setting 条件下(FLOPS<600M),SemiNAS 搜索出的网络结构取得了23.5%的 top-1 错误率和6.8%的 top-5 错误率,超过了其他 NAS 方法。
语音合成(TTS)
我们还探索了 SemiNAS 在新领域的应用,将其用于语音合成(Text to Speech, TTS)任务上。
在将 NAS 应用到一个新任务时,需要面临两个基本的问题:搜索空间设计以及搜索指标设计。对于搜索空间的设计,我们参照主流 TTS 模型,设计了基于编码器-解码器(encoder-decoder)的框架(backbone)。在具体搜索每层的运算操作时,候选操作包括 Transformer 层(包含不同的注意力头数量)、卷积层(包含不同卷积核大小)、LSTM 层。对于评价指标的设计,不像在分类任务、识别任务以及语言模型任务中评价标准是客观的,可以通过程序自动完成。在 TTS 任务中,合成音频的质量需要人工去评判,而 NAS 需要评价成百上千的网络模型,这在 TTS 中是不现实的。所以需要设计一种客观的评价标准。我们发现合成音频的质量和其编解码器之间的注意力机制图中的注意力权重聚焦在对角线上的程度(diagonal focus rate, DFR)有较强相关性,其对最终的音频质量有指导意义,故选择它作为搜索时的客观评价指标。
我们尝试用 NAS 解决当前 TTS 面临挑战的两个场景:低资源场景(low resource setting)和鲁棒性场景(robustness setting)。在低资源场景中,可用的 TTS 训练数据较少,而在鲁棒性场景中,测试的文本输入一般比较难。我们将 NAO 作为对比的 baseline 之一,在实验中保持 NAO 和 SemiNAS 的搜索耗时相同,来比较最终的搜索结构的性能。
我们在 LJSpeech 数据集(24小时语言文本对)上进行实验,对于低资源场景,随机选取了约3小时的语音和文本作为训练数据来模拟低资源场景,最终实验结果如表3所示。
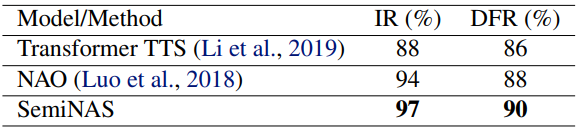
表3:不同方法在低资源场景下的性能
对于最终生成的音频,我们用可懂度(Intelligibility Rate, IR),即人能听懂的单词数量占比,来评价模型性能。可以看到,人工设计的 Transformer TTS [8] 只取得了88%的可懂度,之前的 NAS 算法 NAO 取得了94%,而 SemiNAS 取得了97%的可懂度,相比 Transformer TTS 提升了9%,相比 NAO 也有明显提升。同时可以看到,我们设计的搜索指标 DFR 和 IR 呈正相关性,验证了使用 DFR 作为客观评价指标进行搜索的有效性。
对于鲁棒性场景,我们在整个 LJSpeech 上进行训练,然后额外找了100句较难的句子(包含很多单音节或重复音节等)作为测试集,实验结果如表4所示。
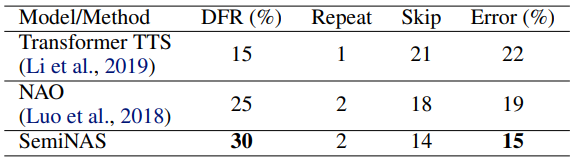
表4:不同方法在鲁棒性场景下的性能
我们计算了不同模型在测试集上发生重复吐词、漏词的句子数,并计算了整体错误率(一句话里只要出现一次重复吐词或漏词记为一次错误)。可以看到,Transformer TTS 达到了22%的错误率,SemiNAS 将其降低到了15%。
我们展示下低资源场景的合成音频示例(这里我们使用 Griffin-Lim 合成语音,所以可以更多关注合成声音是否可懂,而不是声音质量)。
文本:No other employee has been found who saw Oswald enter that morning
TTS 实验更多的音频 demo 链接:
https://speechresearch.github.io/seminas/
SemiNAS 利用半监督学习,从大量无需训练的神经网络结构中进行学习,一方面可以在相训练代价下提升原有 NAS 方法的性能,另一方面可以在保持性能不变的条件下减少训练代价。实验表明,该方法在多个任务和数据集上均取得了非常好的效果。未来我们计划将 SemiNAS 应用到更多的搜索算法上,同时探索 NAS 在更多领域的应用。
更多详情请见论文原文:
Semi-Supervised Neural Architecture Search
论文链接:https://arxiv.org/abs/2002.10389
论文代码现已开源。
GitHub链接:https://github.com/renqianluo/SemiNAS
参考文献
[1] Luo, Renqian, et al. "Neural architecture optimization." Advances in neural information processing systems. 2018.
[2] Ying, Chris, et al. "NAS-Bench-101: Towards Reproducible Neural Architecture Search." International Conference on Machine Learning. 2019.
[3] Zoph, Barret, et al. "Learning transferable architectures for scalable image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[4] Real, Esteban, et al. "Regularized evolution for image classifier architecture search." Proceedings of the aaai conference on artificial intelligence. Vol. 33. 2019.
[5] Liu, Hanxiao, Karen Simonyan, and Yiming Yang. "DARTS: Differentiable Architecture Search." (2018).
[6] Pham, Hieu, et al. "Efficient Neural Architecture Search via Parameters Sharing." International Conference on Machine Learning. 2018.
[7] Guo, Zichao, et al. "Single path one-shot neural architecture search with uniform sampling." arXiv preprint arXiv:1904.00420 (2019).
[8] Li, Naihan, et al. "Neural speech synthesis with transformer network." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. 2019.
文本作者:罗人千、谭旭、王蕊、秦涛、陈恩红、刘铁岩
你也许还想看:

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。