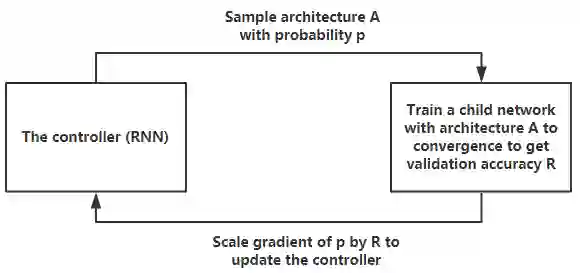
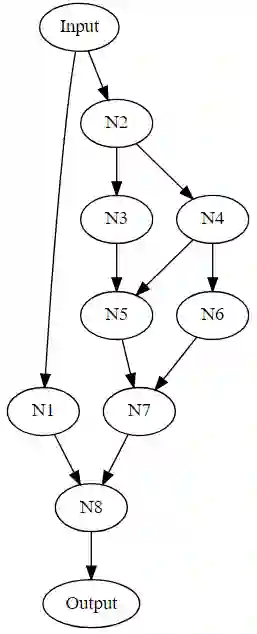
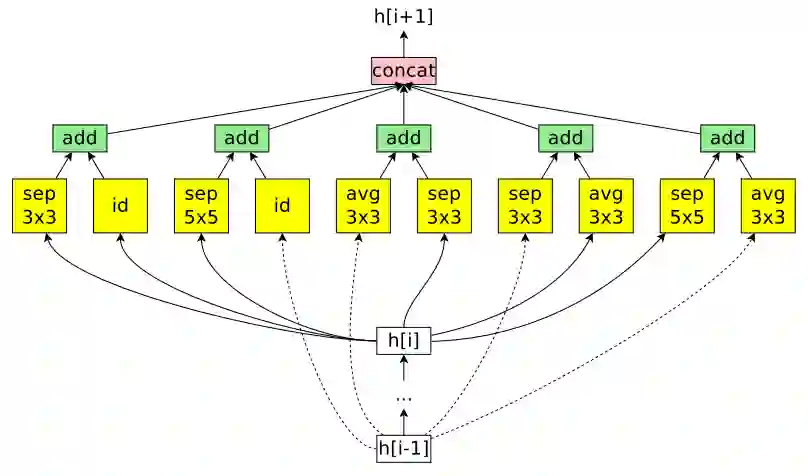
Deep learning has penetrated all aspects of our lives and brought us great convenience. However, the process of building a high-quality deep learning system for a specific task is not only time-consuming but also requires lots of resources and relies on human expertise, which hinders the development of deep learning in both industry and academia. To alleviate this problem, a growing number of research projects focus on automated machine learning (AutoML). In this paper, we provide a comprehensive and up-to-date study on the state-of-the-art AutoML. First, we introduce the AutoML techniques in details according to the machine learning pipeline. Then we summarize existing Neural Architecture Search (NAS) research, which is one of the most popular topics in AutoML. We also compare the models generated by NAS algorithms with those human-designed models. Finally, we present several open problems for future research.
翻译:深层学习深入了我们生活的方方面面,为我们带来了极大的便利,然而,为某项具体任务建立高质量的深层学习系统的过程不仅耗时费时,而且需要大量资源和依赖人的专门知识,这阻碍了产业和学术界深层学习的发展。为缓解这一问题,越来越多的研究项目侧重于自动化机学习(Automle)。在本文中,我们提供了关于最新的最新、全面的AutoML的研究。首先,我们根据机器学习管道,在细节中引入了AutoML技术。然后,我们总结了现有的神经结构搜索(NAS)研究,这是AutoML中最受欢迎的课题之一。我们还比较了NAS算法产生的模型和这些人类设计的模型。最后,我们提出了未来研究的一些尚未解决的问题。