赛尔原创 | ACL20 用于多领域端到端任务型对话系统的动态融合网络
来自:工大SCIR
论文名称:Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension
论文作者:覃立波,徐啸,车万翔,张岳,刘挺
原创作者:覃立波,王馨月
论文链接:
https://www.aclweb.org/anthology/2020.acl-main.565.pdf
代码链接:
https://github.com/LooperXX/DF-Net
一、任务定义
任务型对话系统可以用来帮助用户完成订购机票、餐厅预订等业务,越来越受到研究者的关注。近几年,由于序列到序列(sequence-to-sequence)模型和记忆网络(memory-network)的强大建模能力,一些工作直接将任务型对话建模为端到端任务型对话任务。
如图1,是一个加入来自 SMD 数据集的基于知识 (Knowledge base, KB) 的面向任务的对话的例子。

图1:SMD数据集实例
端到端任务型对话输入输出示例如下::
输入Utterance:“ Address to the gas station. ”
输入知识库 (KB)
输出Utterance:Valero is located at 200 Alester Ave.
二、背景和动机
前人的模型虽然已经达到了较好的效果,但端到端的模型依赖于大量的标注数据进行训练,这导致模型在一个新拓展的领域上很难利用。而实际上,对于一个新的领域,总是很难收集足够多的数据。这就使得将知识从具有充足标注数据的源领域迁移到一个只有少量标注数据的新领域成为非常重要的问题。
已有的端到端任务型对话系统工作可以分为两类:第一类是直接在结合了多领域的数据集进行训练,这种方法虽然够隐含地提取共享的特征却很难有效捕捉领域特有的知识,如图2 (a)所示:
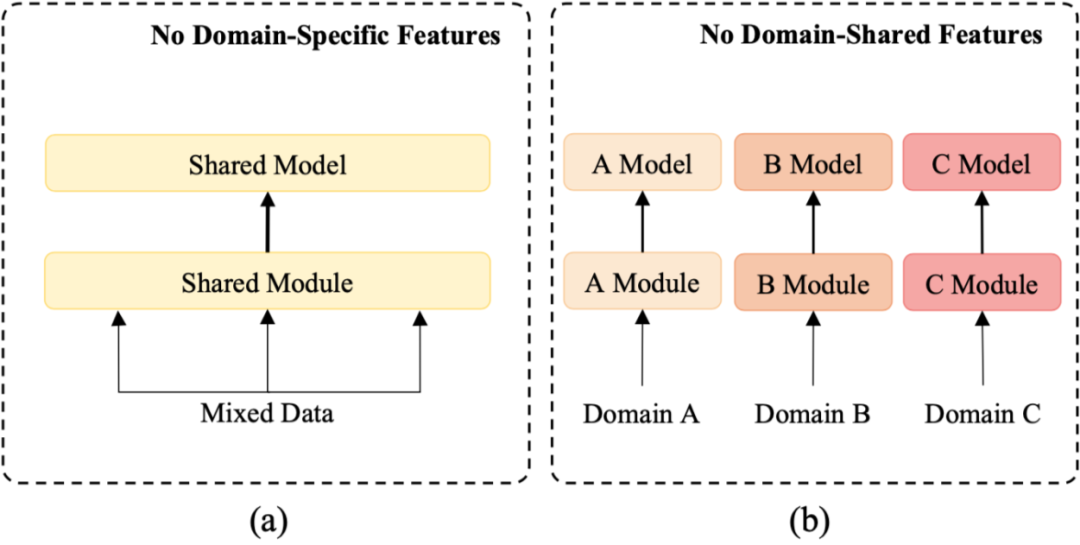
图2:以往方法
第二类是在单独地在各个领域训练不同的模型,这种方法能够很好地捕捉领域特有的知识,却忽视了不同领域间共有的知识,如图2 (b)所示。
我们这篇工作为了综合结合上面两类工作的优点,考虑在多领域端到端任务型对话系统中同时显示结合领域共有和特定的特征,提出使用共享-私有 (shared-private) 架构来建模,如图3所示:
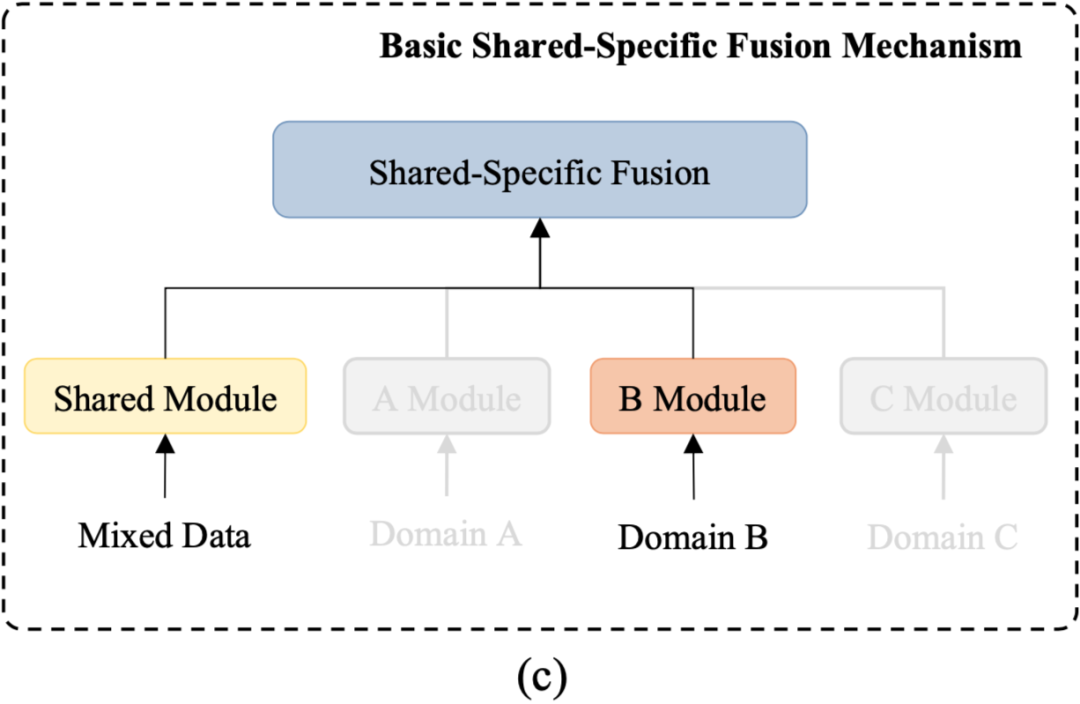
图3:基本的shared-private框架
尽管这种方法能够有效显示建模共享以及私有的特征,但依然还存在两个问题:
(1)在面对一个几乎不具备数据的新领域时,私有模块无法有效提取对应的领域知识;
(2)忽略了一些领域子集间细粒度的相关性(比如和天气领域相比,导航领域和规划领域更相关)。
为了解决这个问题,我们进一步提出 Dynamic Fusion Network (DF-Net)来考虑领域之间的细粒度相关性,如图4所示:
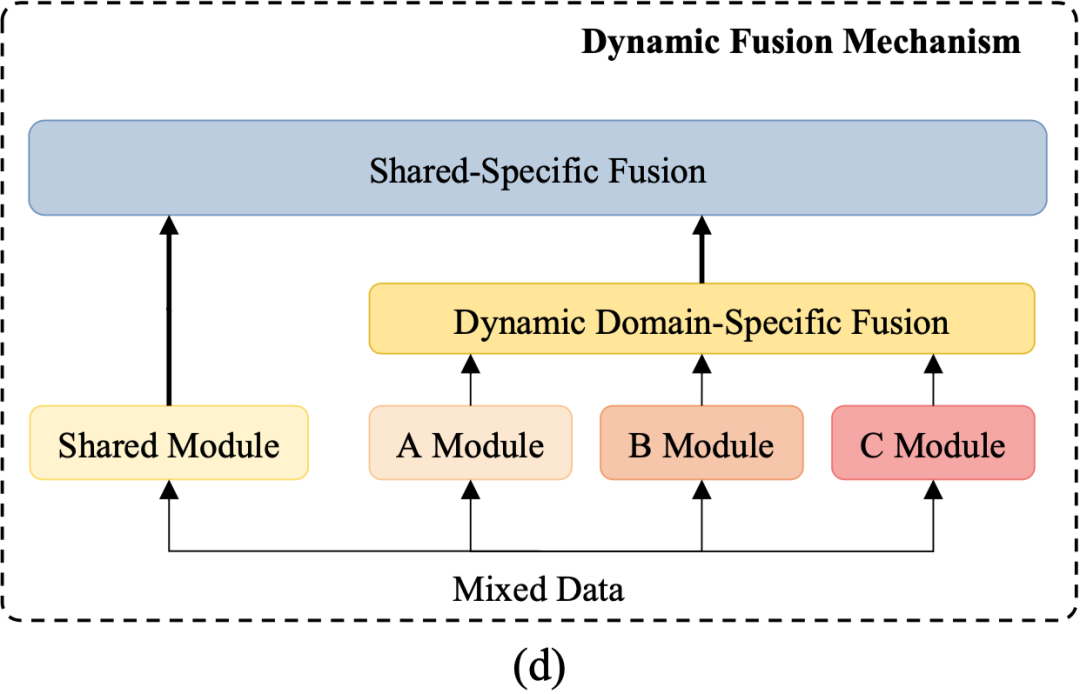
图4:DF-Net框架结构
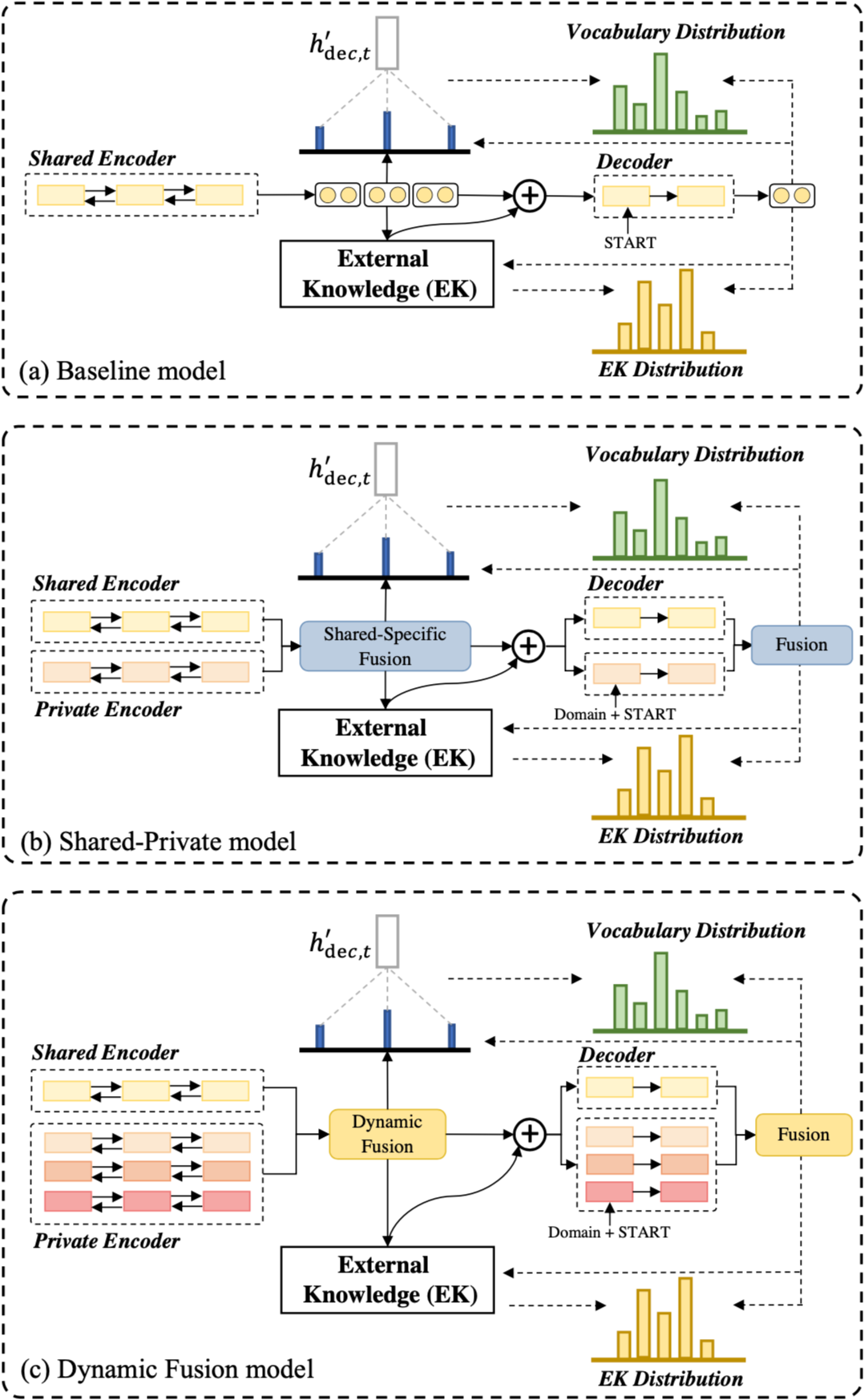
图5:整体框架结构
3.1 Seq2Seq对话生成
GLMP: GLMP 是基于 Mem2Seq 的改进,整体框架基于 MemNN,包含 encoder 和 decoder,encoder 编码对话历史,输出全局记忆指针和全局上下文表示。decoder 提出 sketch RNN,先产生 sketch 的未填充 slot 的响应,再根据全局记忆指针过滤外部知识库查找信息,最后用局部记忆指针实例化未填充的 slot。
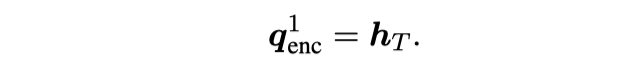
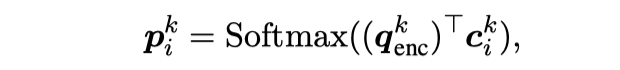
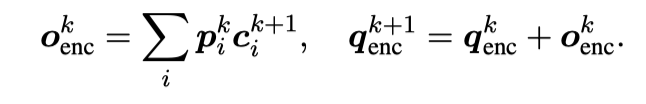
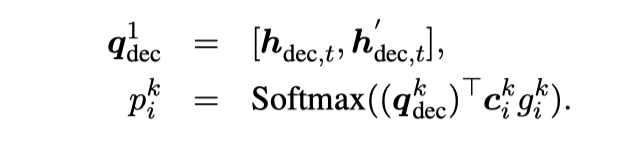
Enhancing Encoder
对于给出的一个实例以及其领域,shared-private encoder-decoder 生成一个 encoder 向量的序列标记为 ,最终的 shared-specific 编码表示为:
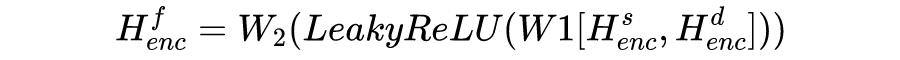
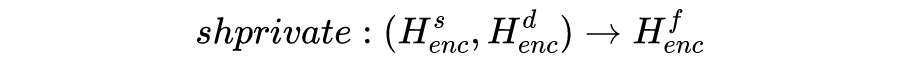
Enhancing Decoder
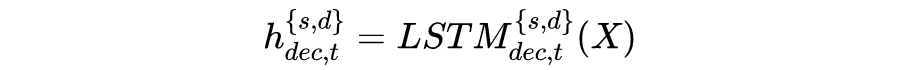
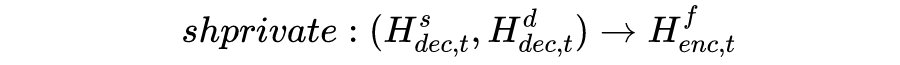
尽管共享-私有架构可以捕捉对应的特有特征,但忽略了领域的一些子集之间的细粒度相关性。本文进一步提出了动态融合层来明确地利用所有领域知识。
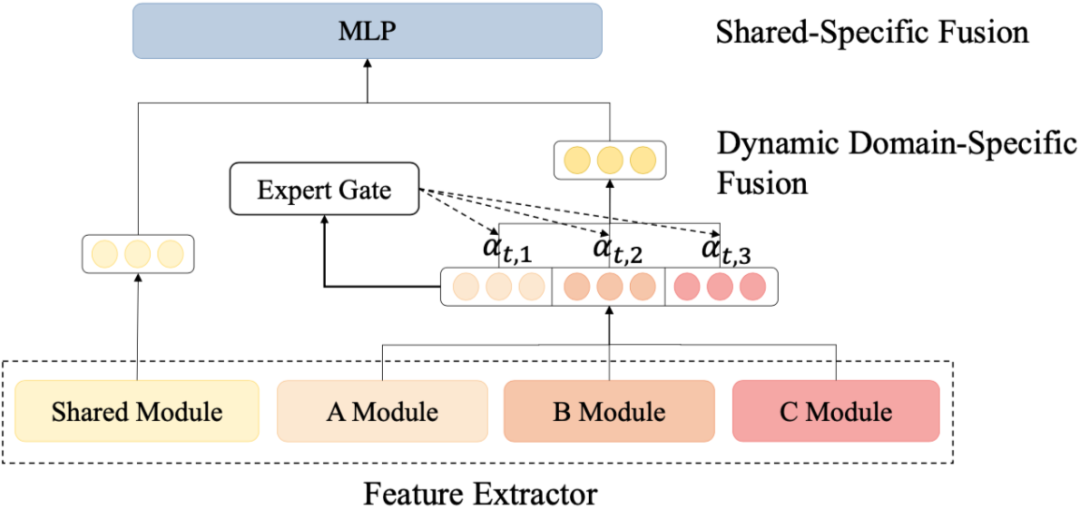
图6:动态聚合结构
动态领域特有特征融合是指给出来自所有领域的领域特有特征,利用一个多专家 (Mixture-of-Experts mechanism, MoE) 机制动态地为当前 encoder 和 decoder 的输入收纳所有领域特有知识。
对于 decoding 过程第 t 步的 fusion 过程如下:
在 decoding 第 t 步时给出所有领域特征表示 ,其中 表示领域的数量。接着将领域特征表示 作为 expert gate 的输入,输出一个度量各个领域与当前输入 token 的相关性的 softmax score 。这一步通过一个简单的前馈层达到:
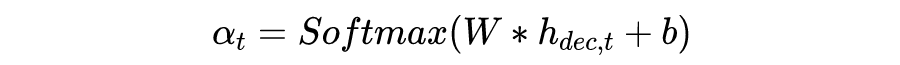
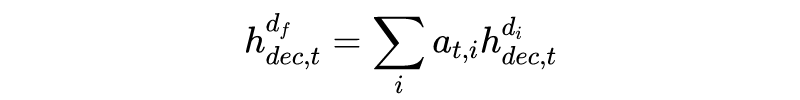
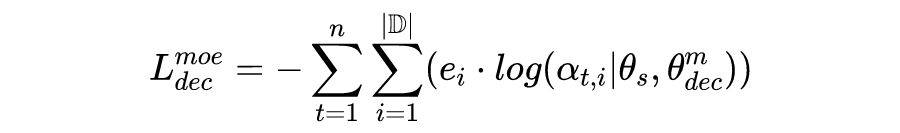
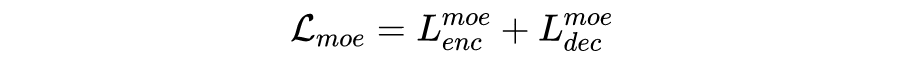
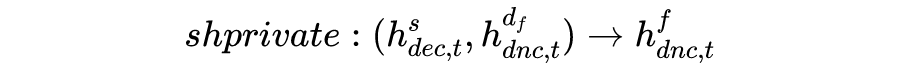
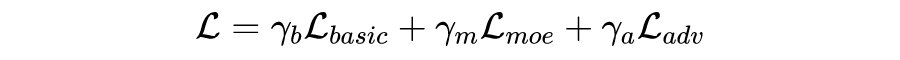
四、实验结果
我们在公开的SMD和Multi-WOZ2.1数据集上进行了实验,数据集统计如表1所示:
表1:数据统计表

结果如表2所示:
表2:主实验结果表
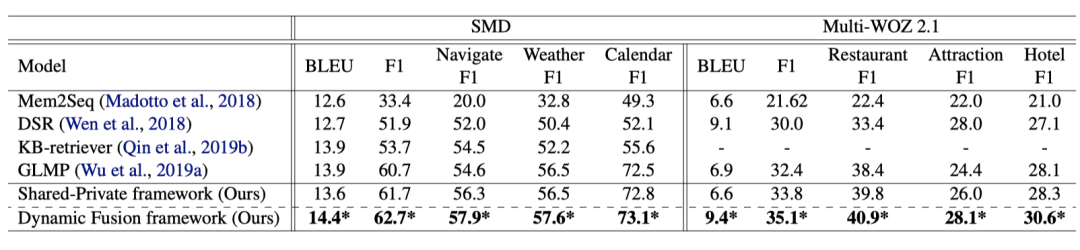
从表中可以得出以下两个结论:
(1)vanilla的 shared-private 框架超过了之前的最好模型GLMP,表明显示融合领域共享与领域特有知识的有效性。
(2) 本文提出的DF-Net框架在 SMD 和 Multi-WOZ 2.1.达到了 SOTA 性能,表明考虑不同领域的细粒度关系能够进一步提高模型性能。
五、分析
除了在主试验验证了我们模型的有效性外,我们还进行了大量的分析试验。
5.1 消融实验
我们首先在SMD数据集进行了丰富的消融实验,结果如表3所示:
表3:消融实验结果表
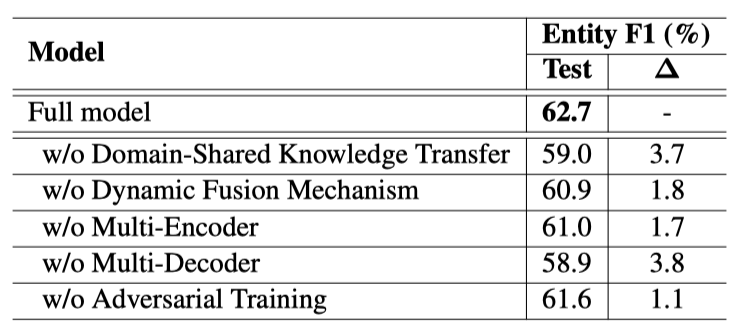
从结果可以看出,所有模块的提出都对最后整个的性能都有一定的提升。
5.2 few-shot场景实验
我们还做了低资源设定下的实验,对训练数据进行了[1%,5%,10%,20%, 30%,50%] 的sample进行训练,结果如图7所示:
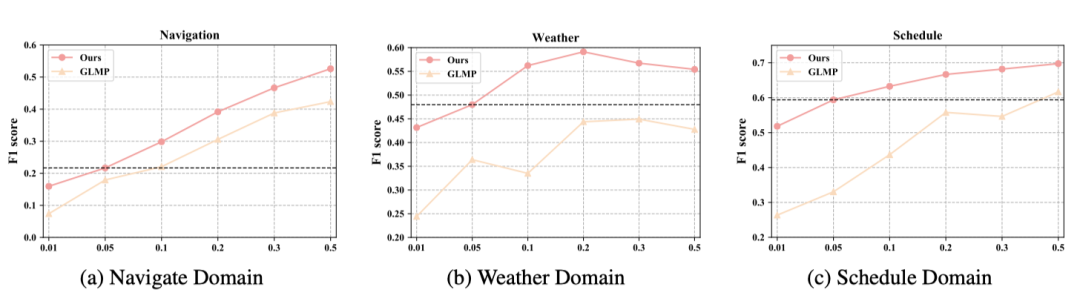
图7: few-shot实验
从结果可以得出我们提出的模型在不同资源情况都超过了 GLMP,证明了我们模型在少资源情况下的有效性和鲁棒性。更重要的是,在 5% 数据的情况下,在所有领域平均超过 GLMP13.9%。且本文的模型在仅用 5% 的数据训练情况下表现依旧由于 GLMP 用 50% 的数据训练的结果,这也进一步证明了模型能够有效的地迁移到低资源新领域。
5.3 zero-shot实验
我们还进行了零样本设定下的实验,结果如图8所示:
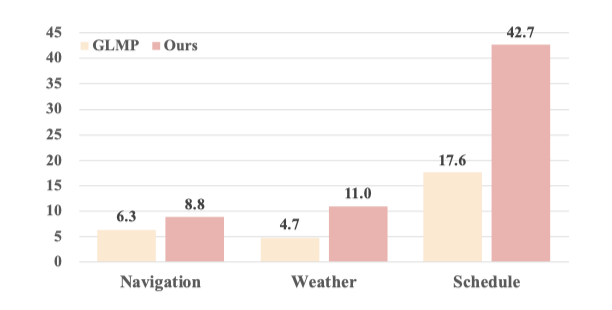
图8: zero-shot实验
同样可以看出在零样本基础上,我们模型在所有领域都超过了前人sota模型GLMP,进一步验证了我们模型的迁移性。
5.4 可视化
为了更直观地理解动态融合层,我们在 5% 的低资源情况下,将每个领域 gate 的分布做了可视化,如图9所示。每个领域的列包含 100 个例子,每一行是其对应的专家值(可以理解为行列对应的线条颜色越深两个领域越相关,可迁移的知识越多)。
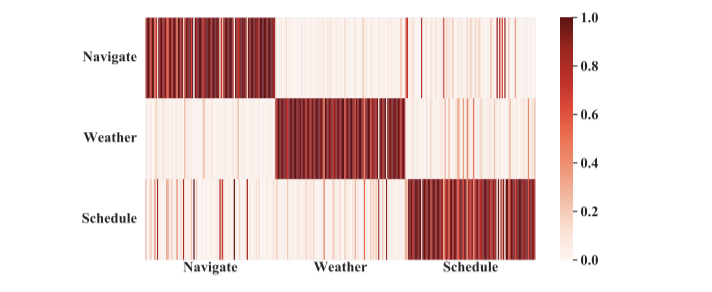
图9: 可视化实验
六、结论
我们首次将 shared-private 应用在了多领域端到端对话任务中,并成功将融合了领域共享和特定特征的表示用于query知识库提高性能。shared-private 的思想此前在多领域文本分类和文本风格转换上已经有了相关工作,我们的实验结果表明,这种思想在多领域任务型对话方面的应用也能取得很好的效果。并且我们还提出了动态融合网络,很有效地捕捉了领域间更细粒度的相关性,在低资源情况下也取得了很好的效果。
本期编辑:王若珂
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记