【无监督学习最新研究】简单的「图像旋转」预测,为图像特征学习提供强大监督信号
原文:arXiv
作者:Spyros Gidaris、Praveer Singh、Nikos Komodakis
来源:新智元
【导读】在论文中,研究人员训练卷积神经网络来识别被应用到作为输入的图像上的二维旋转。从定性和定量两方面证明,这个看似简单的任务实际上为语义特征学习提供了非常强大的监督信号。
在过去的几年中,深度卷积神经网络(ConvNets)已经改变了计算机视觉的领域,这是由于它们具有学习高级语义图像特征的无与伦比的能力。然而,为了成功地学习这些特征,它们通常需要大量手动标记的数据,这既昂贵又不可实行。因此,无监督语义特征学习,即在不需要手动注释工作的情况下进行学习,对于现今成功获取大量可用的可视数据至关重要。
在我们的研究中,我们打算通过这种方式学习图像特征:训练卷积神经网络来识别被应用到作为输入的图像上的二维旋转。我们从定性和定量两方面证明,这个看似简单的任务实际上为语义特征学习提供了非常强大的监督信号。我们在各种无监督的特征学习基准中,对我们的方法进行了详尽的评估,并在所有这些基准中展示出了最先进的性能。
具体来说,我们在这些基准中的结果展现了在无监督的表征学习中,较之先前最先进的方法,我们的方法取得了巨大改进,从而显著缩小了与监督特征学习之间的差距。例如,在PASCAL VOC 2007检测任务中,我们的无监督预训练的AlexNet模型达到了54.4%的 最先进的性能表现(在无监督的方法中),比监督学习的情况下仅少了2.4个百分点。当我们将无监督的学习特征迁移到其他任务上时,我们得到了同样的惊人结果,例如ImageNet分类、PASCAL分类、PASCAL分割和CIFAR-10分类。我们论文的代码和模型将会发布在这里:
(https://github.com/gidariss/FeatureLearningRotNet)。
近年来,在计算机视觉中广泛采用的深度卷积神经网络(LeCun等人于1998年提出),在这一领域取得了巨大的进步。具体来说,通过在具有大量手动标记数据的目标识别(Russakovsky等人于2015年提出)或场景分类(Zhou等人于2014年提出)任务上对卷积神经网络进行训练,它们成功学习到了适合于图像理解任务的强大视觉表征。例如,在这种监督的方式下,卷积神经网络所学习的图像特征在它们被迁移到其他视觉任务时取得了很好的效果,比如目标检测(Girshick于2015年提出)、语义分割(Long等人于2015年提出),或者图像描述(Karpathy 和 Fei-Fei于2015年提出)。然而,监督特征学习有一个主要的限制,那就是需要大量的手动标记工作。在如今拥有大量可用的可视数据的情况下,这既昂贵又不可实行。

以90°的随机倍数(例如,0°、90°、180°、270°)旋转的图像。我们自监督特征学习方法的核心观念是,如果一个人对图像中描述的对象没有概念,那么他就不能识别应用于它们的旋转
因此,最近人们对以无监督的方式学习高级的基于卷积神经网络的表征越来越感兴趣,这种方式避免了对视觉数据的手动注释。其中,一个突出的范例就是所谓的自监督学习,它界定了一个注解不受约束的借口任务,只使用图像或视频上的视觉信息,从而给特征学习提供一个代理监督信号。例如,为了学习特征,Zhang等人和Larsson等人训练了卷积神经网络以对灰度图像进行着色,Doersch等人(于2015年)、Noroozi 和 Favaro(于2016年)预测了图像块的相对位置,以及Agrawal等人(于2015年)预测了在两个连续帧之间正在移动的车辆的运动(即自动)。这种自监督任务背后的基本原理是,解决这些问题将迫使卷积神经网络学习语义图像特征,这对其他视觉任务是有用的。事实上,通过上述自监督任务所学习的图像表征,尽管它们没能做到与监督学习表征的性能相当,但它们已经被证明在迁移到其他视觉任务上时是个好选择,诸如目标识别、目标检测和语义分割。其他成功的无监督特征学习案例是基于聚类的方法、基于重构的方法,和学习生成概率模型的方法。
我们所提出的用于语义特征学习的自监督任务的说明图
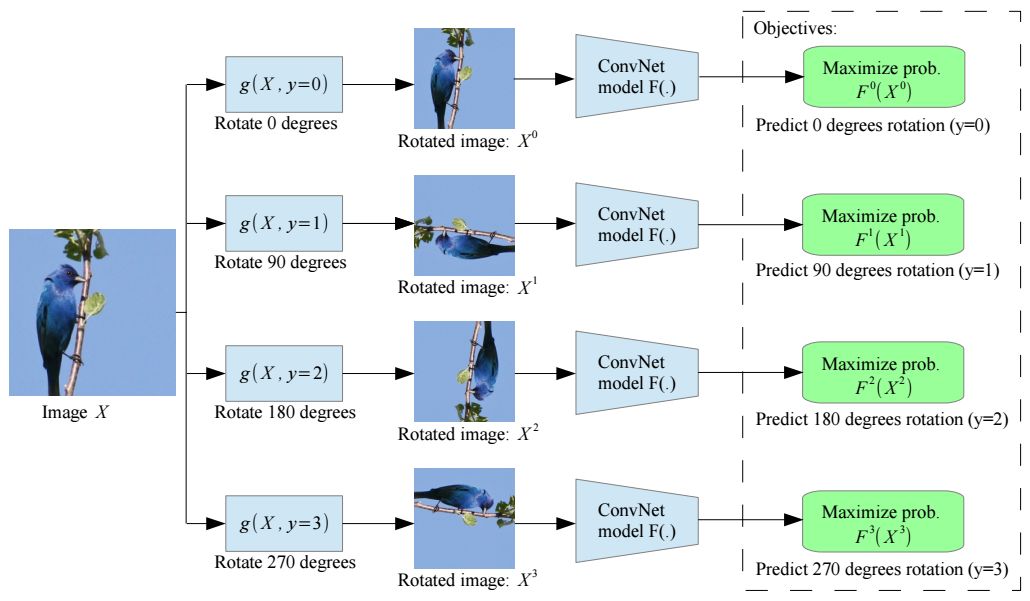
我们的研究遵循自监督范例,并提出,通过训练卷积神经网络(ConvNets)识别应用于其作为输入的图像的几何变换,从而学习图像表示。更具体地说,首先,我们定义了一组离散的几何变换,然后将这些几何变换中的每一个应用于数据集上的每个图像,并且将生成的变换图像馈送到经过训练以识别每个图像的变换的卷积神经网络模型中。在这个方法中,它是一组几何变换,实际上定义了卷积神经网络模型所必须学习的分类接口任务(classification pretext task)。因此,为了实现无监督的语义特征学习,正确地选择这些几何变换是至关重要的。我们提出的是将几何变换定义为0°、90°、180°和270°的图像旋转。因此,卷积神经网络模型在识别四个图像旋转之一(见图2)的4种图像分类任务上进行了训练。我们认为,为了让一个ConvNet模型能够识别应用于图像中的旋转变换,它需要理解图像中所描述的对象的概念(参见图1),例如它们在图像中的位置、类型和、姿势。在整篇论文中,我们从定性和定量的论证上支持这一理论。此外,我们经过实验证明,尽管我们的自监督方法很简单,但预测旋转变换的任务为特征学习提供了一个强大的替代监督信号。在相关基准测试上取得了显著的进步。

由AlexNet模型所生成的注意力图(attention map),对(a)进行训练以识别目标(监督),和对(b)进行训练以识别图像旋转(自监督)。为了生成一个卷积层的注意图,我们首先计算该层的特征映射,然后我们提高power p上的每个特征激活,最后我们对特征映射的每个位置处的激活进行求和。对于卷积层1,2和3,我们分别使用了p = 1、p = 2和p = 4
需要注意的是,我们的自监督任务不同于Dosovitskiy等人于2014年和Agrawal等人于2015年所提出的研究方法,尽管他们也涉及到几何变换。Dosovitskiy等人于2014年训练了卷积神经网络模型,以产生对图像的区分性表征,同时不改变几何和色度变换。相反,我们训练卷积神经网络模型来识别应用于图像的几何变换。这与Agrawal等人于2015年提出的自运动方法(egomotion method)有根本的不同,该方法采用了一种带有孪生(siamese)结构的卷积神经网络模型,该模型将两个连续的视频帧作为输入,并进行训练以预测(通过回归)其相机转换。相反,在我们的方法中,卷积神经网络将一个单一图像作为输入,我们已经应用了一个随机几何变换(旋转),并经过训练(通过分类)识别这种几何变换,而不需要访问初始图像。

由AlexNet模型所学习第一层过滤器在(a)监督目标识别任务和(b)识别旋转图像的自监督任务上进行的训练
我们的贡献:
•我们提出了一个新的自监督任务,这个任务非常简单,与此同时,我们也在文章中进行了展示,为语义特征学习提供了强大的监督信号。
•我们在各种环境(例如半监督或迁移学习环境)和各种视觉任务(即CIFAR-10、ImageNet、Places和PASCAL分类以及检测或分割任务)中详细评估了我们的自监督方法。
•我们提出的新的自监督方法在各个方面都展现出了最先进的成果,较先前的无监督方法有了显著改善。
•我们的研究表明,对于几个重要的视觉任务而言,我们的自监督学习方法显著缩小了与无监督和监督特征学习之间的差距。
经过研究,我们提出了一种用于自监督特征学习的新方法,它通过训练卷积神经网络模型,使其能够识别已经用作输入图像的图像旋转。尽管我们的自监督任务很简单,但我们证明,它可以成功地训练卷积神经网络模型,从而学习语义特征,这些语义特征对于各种视觉感知任务非常有用,例如目标识别、目标检测和目标分割。我们在各种无监督和半监督条件下对我们的方法进行了详尽的评估,并且在测试中实现了最先进的性能。具体而言,我们的自监督方法大幅度改进了ImageNet分类、PASCAL分类、PASCAL检测、PASCAL分割和CIFAR-10分类的无监督特征学习的最新结果,超越了以往的方法,因此大幅缩小了无监督和监督特征学习之间的差距。
原文链接:https://arxiv.org/pdf/1803.07728.pdf
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【征稿通知】IEEE IV 2018“智能车辆中的平行视觉”研讨会
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【征稿】神经计算专刊Virtual Images for Visual Artificial Intelligence
☞【学界】CVPR 2018 | 哈工大提出STRCF:克服遮挡和大幅形变的实时视觉追踪算法
☞【深度】如何「看图说话」?Facebook提出全新的基于图像实体的「图像字幕」框架


