CMU最新视觉特征自监督学习模型——TextTopicNet

作者 | Yash Patel,Lluis Gomez,Raul Gomez,Marcal Rusinol,Dimosthenis Karatzas, C.V. Jawahar
译者 | 林椿眄
编辑 | Jane
出品 | 人工智能头条
▌摘要
深度学习方法在计算机视觉领域所取得的巨大成功,要归功于大型训练数据集的支持。这些带丰富标注信息的数据集,能够帮助网络学习到可区别性的视觉特征。然而,收集并标注这样的数据集通常需要庞大的人力成本,而所标注的信息也具有一定的局限性。作为替代,使用完全自监督方式学习并设计辅助任务来学习视觉特征的方式,已逐渐成为计算机视觉社区的热点研究方向。
我们提出了一种 TextTopicNet 的方法,通过挖掘大规模多模态网络文档的大规模语料库(如维基百科文章),以自监督的方式来学习视觉特征。我们的方法能够通过训练一个 CNN 模型,针对特定出现并作为描述的图片,预测其文本的上下文语义信息并高效地学习视觉特征。更具体地说,我们使用流行的文本嵌入技术,以自监督学习的方式训练深度 CNN。大量的实验结果表明:与先前自监督学习的方法相比,我们的方法能够在图像分类、目标检测和多模态检索任务上取得了 state-of-the-art 的表现。
▌简介
大规模带标注的数据集的出现是深度学习在计算机视觉领域取得巨大成功的关键因素之一。然而,监督式学习存在一个主要问题:过于依赖大规模数据集,而数据集的收集和手动数据标注需要耗费大量的人力成本。
作为替代方案,自监督学习旨在通过设计辅助任务来学习可区别性的视觉特征,如此,目标标签就能够自由获取。这些标签能够直接从训练数据或图像中获得,并为计算机视觉模型的训练提供监督信息,这与监督式学习的原理是相同的。但是不同于监督式学习的是,自监督学习方法通过挖掘数据的性质,从中学习并生成视觉特征的语义标签信息。还有一类方法是弱监督学习,这种学习方式能够利用低水平的注释信息来解决更复杂的计算机视觉任务,如利用自然场景下每张图像的类别标签进行目标检测任务。
我们的目标是探索一种自监督的解决方案,利用图像和图像之间的相关性来替代完全监督式的 CNN 训练。此外,我们还将探索非结构化语言语义信息的强弱,并将其作为文本监督信号来学习视觉特征。
本文的工作主要总结如下:
我们扩展了之前提出的方法并展示了以自监督的方式进行插图文章的学习,这能够进一步扩展到更大的训练数据集(如整个英语维基百科)。
通过实验,我们验证了 TextTopicNet 的表现优于其他基准评估中的自监督或自然监督的方法。此外,我们还在更具挑战性的 SUN397 数据集上测试了我们的方法,结果表明 TextTopicNet 能够减少自监督学习和监督学习之间的性能差距。
我们展示了将上下文的文本表征用于模型的训练,这能够有助于网络自动学习多模态的语义检索。在图像——文本的检索任务中,TextTopicNet 的表现超过了无监督学习的方法,而与监督学习的方法相比,我们的方法能够在无需任何特定类别信息的情况下还能表现出有竞争力的性能。
在自监督学习设置下,我们对不同的文本嵌入方法进行了对比分析,如word2vec,GloVe,FastText,doc2vec 等。
此外,我们还公开发布了我们所收集的数据集,该数据集采自整个英语维基百科,由 420 万个图像组成,每张图像都有对应的文字描述信息。
▌维基图像——文本数据集
我们以维基百科作为数据的来源,这是一个基于网络的多语言的百科全书项目,目前有 4000 多万篇文章,含 299 种不同语言。维基百科文章通常由文字及其他多媒体类型的对象(如图像,音频或视频文件) 组成,因此可以将其视为多模态的文档数据。对于我们的实验,我们使用两个不同的维基百科文章集合:(a) ImageCLEF 2010 维基百科数据集;(b) 我们所收集的英语维基百科图像——文本数据集,包含 420 万图像文本对组成的数据,下图1展示了 11 种类别的文章分布情况。
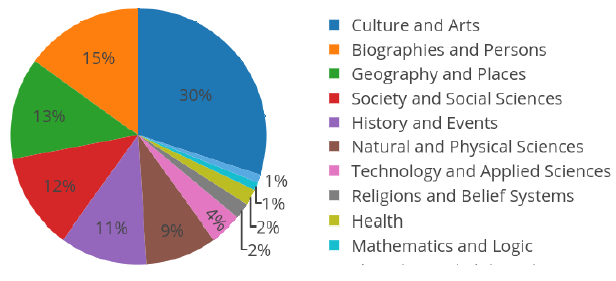
图1 英语维基百科种11种类别的文章分布情况
▌TextTopicNet
我们提出了一种 TextTopicNet 的方法,通过挖掘大规模多模态网络文档的大规模语料库(如维基百科文章),以自监督的方式来学习视觉特征。在自监督学习设置下,TextTopicNet 能够使用免费可用的非结构化、多模态的内容来学习可区别的视觉特征,并在给定图像的下,通过训练 CNN 来预测可能插图的语义环境。我们的方法示意图如下图 2 所示,该方法采用一个文本嵌入算法来获取文本部分的向量表征,然后将该表征作为 CNN 视觉特征学习的一种监督信号。我们进一步使用多种类别的文档以及词级(word-level) 的文本嵌入方法,发现通过 LDA 主题模型框架发现的隐藏语义结构,能够在主题层面最佳地展现文本信息。
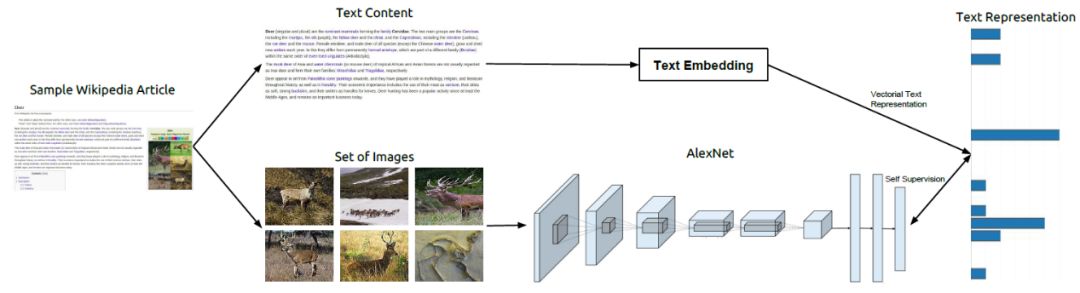
图2 方法概览。维基百科文章包含一个主题的文本描述,这些文章同时也附有支持文本的插图。文本嵌入框架能够与文本信息相关的全局上下文表征。而整篇文章的这种文本表征向量被用于为 CNN 的训练提供自监督信号
如图 3 所示,作为主题层面的语义描述器,需要大量可用的关于特定类别或细粒度类别的视觉数据。虽然在我们收集的数据中,这类数据非常有限,但是这很容易在更广泛的目标类别(如哺乳动物) 中找到足够多的、有代表性的图像。因此,在给定的目标主题情况下,我们的方法能够学习到期望的视觉特征,这种特征是通用的,即同样适用于其他特定的计算机视觉任务。

图 3 描述特定实体的维基百科文章。如 (a) 中“羚羊”或 (b) 中的“马”,每个实体通常包含五张图像。对于一些特定实体,如 (c) 中的“食草哺乳动物”,相关的图像很容易就达到数百或成千上万张。
我们还训练一个 CNN 模型,它能够直接将图像投影到文本的语义空间,而 TextTopicNet 不仅能够在无需任何标注信息的情况下从头开始学习数据的视觉特征,还可以以自然的方式进行多模态的检索,而无需额外的注释或学习成本。
▌实验
我们通过大量的实验来展示 TextTopicNet 模型所学习到的视觉特征质量。衡量的标准是所习得的视觉特征具有足够好的可区别性和鲁棒性,并能进一步适用于那些未见过的类别数据。
首先,为了验证图像—文本对的自监督学习,我们比较了各种文本嵌入方法。其次,我们在 PASCAL VOC 2007 数据集的图像分类任务中对 TextTopicNet 模型每层的特征进行基准分析,以找到了 LDA 模型的最佳主题数量。然后,我们分别在 PASCAL、SUN397 和 STL-10 数据集的图像分类和检测任务中进一步与当前最佳的自监督方法和无监督方法进行了比较。最后,我们利用维基百科检索数据集对我们的方法进行了图像检索和文本查询实验。
▌自监督视觉特征学习的文本嵌入算法比较
在自监督视觉特征学习的设置下,我们对 word2vec,GloVe,FastText,doc2vec 及 LDA 算法进行了比较分析。对于每种文本嵌入方法,我们都将训练一个 CNN 模型并利用网络不同层获得的特征信息去学习一个一对多的SVM (one-vs-all SVM)。下表1显示了在 PASCAL VOC2007 数据集中,使用不同文本嵌入方法,模型所展现的分类性能。我们观察到在自监督的视觉特征学习任务中,基于嵌入的 LDA 方法展现了最佳全局表现。
表1:使用不同文本嵌入方法的 TextTopicNet 模型在 PASCAL VOC2007 数据集 图像分类任务上的性能表现(%mAP)

▌LDA 模型的超参数设置
我们用 ImageCLEF Wikipedia 数据集上 35582 篇文章训练了一个 LDA 模型,以确定 LDA 模型的主题数量。下图4展示了实验结果,我们可以看到拥有 40 个主题数的 LDA 模型能够获得最佳的 SVM 验证准确性。

图4 随着 LDA 主题数量的变化,PASCAL VOC2007 数据集上 One vs. Rest 线性 SVM 所取得的验证准确性(%mAP)
▌图像分类和图像检测
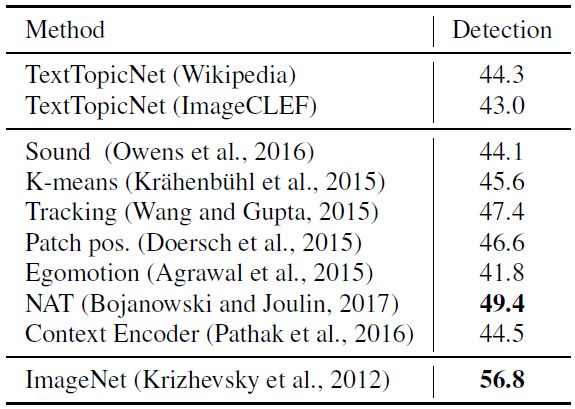
我们分别在 PASCAL、SUN397 和 STL-10 数据集进行图像分类和检测任务,比较并分析 TextTopicNet 以及当前最佳的自监督和无监督模型的表现。下表 2、3和4 分别展示各模型在 PASCAL VOC 2007、SUN397 和 STL-10 数据集上的分类表现,表 5 展示了在 PASCAL VOC 2007 数据集上模型的检测性能。
表 2 PASCAL VOC2007 数据集上各模型的分类表现(%mAP)
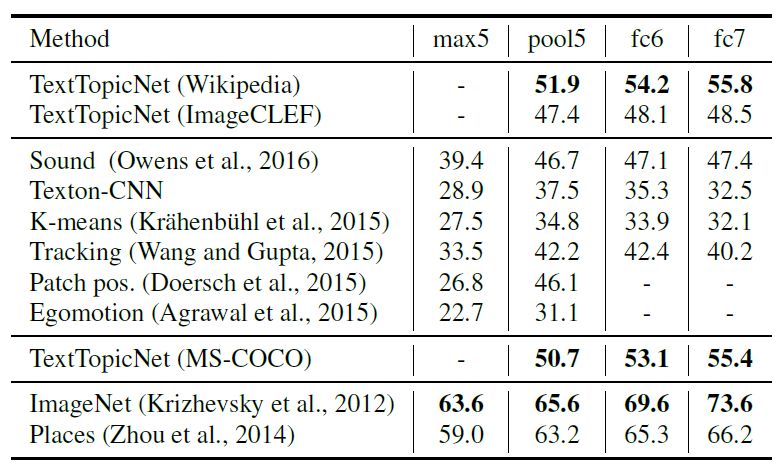
表 3 SUN397 数据集上各模型的分类表现(%mAP)
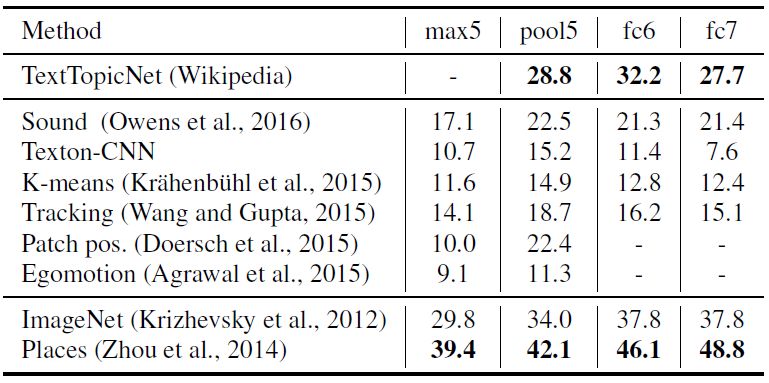
表 4 STL-10 数据集上各模型的分类表现(%mAP)

表 5 PASCAL VOC 2007 数据集上各模型的检测表现(%mAP)
▌图像检索和文本查询
我们还在多模态检索任务中评估所习得的自监督视觉特征:(1) 图像查询与文本数据库; (2) 文本查询与图像数据库。我们使用维基百科检索数据集,由2,866 个图像文档对组成,包含 2173 和 693 对训练和测试数据。每个图像--文本对数据都带有其语义标签。下表 6 展示了监督和无监督学习方法在多模态检索任务中的表现,其中监督学习的方法能够利用与类别相关的每个图像--文本对信息,而无监督学习方法则不能。
表 8 维基数据集上各监督学习和无监督学习方法的表现(%mAP)
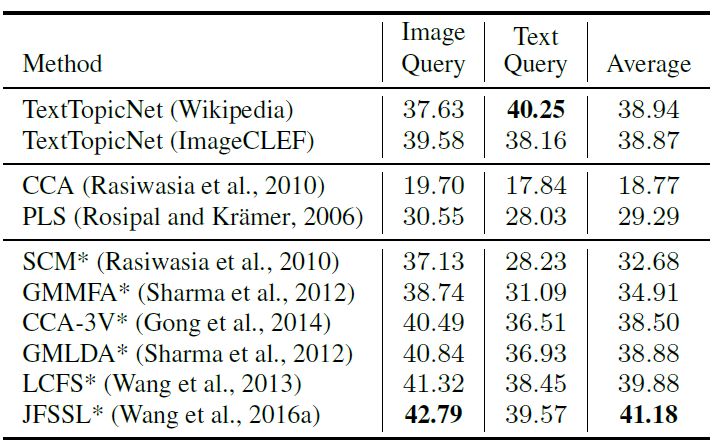
图 4 显示了与给定查询图像(最左侧) 最接近的 4 张图像,其中每行使用的是 TextTopicNet 模型不同层次获得的特征,从上到下:prob,fc7,fc6,pool5 层。这些查询图像是从 PASCAL VOC 2007 中随机选择的,且从未在训练时出现过。

图4 与查询图像(最左侧) 最相近的4张图像
图 5显示了在 TextTopicNet 主题空间中,与给定查询文本最接近的 12 个查询内容。可以看到,对于第一条查询文本(“飞机”),所检索到的图像列表几乎是其相同的同义词,如“flight”,“airway”或“aircraft”。利用文本的语义信息,我们的方法能够学习多义词的图像表示。此外,TextTopicNet 模型还能够处理语义文本查询,如检索(“飞机”+ “战斗机”或“飞行”+“天空”) 等。

图 5 与不同文本查询最接近的12个查询内容
▌结论
在本文中,我们提出了一种自监督学习方法,用于学习 LDA 模型的文本主题空间。该方法 TextTopicNet 能够在无监督设置下,利用多模态数据的优势,学习并训练计算机视觉算法。将文章插图中的文字视为噪声图像标注信息,我们的方法能够通过视觉特征的学习,训练 CNN 模型并预测在特定的上下文语义中最可能出现的插图。
我们通过实验证明我们方法的有效性,并可以扩展到更大、更多样化的训练数据集。此外,TextTopicNet 模型学到了视觉特征不仅适用于广泛的主题,而且还能将其应用到更具体、复杂的计算机视觉任务,如图像分类,物体检测和多模态检索。与现有的自监督或无监督方法相比,我们方法的表现更优。
最后,有关 TextTopicNet 的源代码,预训练模型以及维基百科数据集资源,可以在我们公开的 https://github.com/lluisgomez/TextTopicNet 获取。
原文链接:https://www.arxiv-vanity.com/papers/1807.02110/
TextTopicNet: Self-Supervised Learning of Visual Features Through Embedding Images on Semantic Text Spaces




