盘点我跳过的科研天坑,进坑就是半年白干

文 | 白鹡鸰 and 小轶 祝大家新年快乐!
去年白鹡鸰花了两个月,刷了八千篇Arxiv,结果发现很多论文存在一些比较“基本”的常见问题:
-
研究问题和问题假设存在严重的漏洞,或者缺少充分的相关工作调研,导致所谓的新问题只是新瓶装旧酒。 -
模型的选择与想解决的问题牛头不对马嘴。 -
实验设计错误, 并没有针对所声称的模型优势来进行实验设计(还试图用不合理的实验分析去强行圆回来)。比如,一篇论文号称自己可解释性强,却拿着精度当指标。
以上本应是研究的基本要求,只有满足了这些条件才能再去讨论一份工作是否有所创新,有所贡献。但现在不少论文都本末倒置了。很多人在科研的过程中,一些最基本的科研要求往往被忽视,更多关注的反倒是“创新”(novelty)和“贡献”(contribution)之类更高层次的要求。殊不知,后者必须建立在前者的基础上。否则,所谓的创新与贡献恐怕只是水中捞月的假象——
“创新性”被替换为“方法够不够花哨复杂”。为了这虚假的 “创新”,模型被强行塞入无效模块,或是添上意义不大的技巧。
“贡献度”被替换为“有没有刷到 SOTA”。但 SOTA 有时候也并不能代表全部:或许模型并没有掌握任务所必须具备的能力,只是过拟合了特定的数据集;或许模型的性能提升不是论文提出的核心方法带来的,而只是某个一笔带过的技巧、或者是不公平的比较方式导致的。
Severus 曾在往期推文中谈过他对“算法岗”的理解。其中一些观点与我们这里想说的不谋而合。他认为很多毕业生刚进入工业界时,最大的短板是缺少扎实地分析问题的能力,导致方法难以落地。并且吐槽了科研界很多 idea 的形成过程只是“灵光一现”,评价方式则“唯指标论”。其实,做科研何尝不需要扎实的分析能力?不止需要,而且是基本技能之一。只是,忽视这些基本要求,不知从什么时候开始已经成为主流了。
这就像一个歌手,唱歌“是否音准”本应是基本要求,“有没有流传度高的音乐作品”是较高层次的要求。而现在却变成了:基本要求被忽视,高级要求则被“粉丝多少/身价高低”取代。
科研误解的流行从何而来?
那么,为何会存在这么普遍的科研误解,以致于工业界的大佬会认为:只经历过科研训练的毕业生,往往连最基本问题分析能力都没有?大抵可以归为这样两个原因:
其一, “基本”要求≠“简单”的要求。虽然“扎实的问题分析、相关工作调研充分、解决方法合理、实验设计有针对性”是一篇工作的基本要求,但并不代表这些要求是容易达成的。就像“音准”等等是一个歌手的基本要求,但好的唱功又谈何容易。即使已经具备一定歌唱实力,也难免会有失误的时候。同理,扎实的科研基本功岂是朝夕可得。
其二, 研究的思维误区和思维惯性、知识的局限性息息相关,不能一劳永逸地避免。无论是小轶还是白鹡鸰,在刚入门科研的时候,文章开头所提到的坑基本全都踩了个遍。只是有幸碰到了好的引导者,而且经验不断积累,才逐渐能够有意识地去规避这些问题。但是,在某个思维松懈的瞬间,或是出于无法避免的知识局限性,哪怕是已经有一定经验的研究者,仍然可能再次踏入陷阱。
如果身边能有一位有经验的前辈在科研进程中定期讨论,避免踩坑的概率会大大降低一些,也会更快地对科研形成正确认识。这位前辈倒也不必事事躬亲地教,只需帮助识别出一些常见的坑,发出“别跳”的警告即可。遗憾的是,在近年来全民 AI 的趋势下,许多入门科研的年轻人并没有条件得到这样的指导,只能摸黑前进。投入了大量时间、精力,甚至牺牲健康才完成的工作,却因为从根本上就存在漏洞,使得一切努力都成了泡影。到最后,可能都还没对科研形成最基本的正确认识,就带着误解毕业了。
有的工作不能够达到某些基本科研要求,或许是作者的无心之失。但也不否认有一些工作是在有意识地粗制滥造,将存在问题的工作加以包装,以次充好。模型上堆叠各式各样模块,把各种当下热点技术都沾了点边。然后煞费苦心调出实验结果。最后再胡诌个似是而非的 motivation,补齐相关工作。面对这类工作,也许有经验的审稿人很容易就能发现问题。但若是遇到个经验不足的审稿人,很可能就打出了高分。毕竟这样的论文经过一番包装,确实金玉其外。再加上这样的工作制造成本低廉,大可以多做几份,搞“海投战术”——只要分母够大,总有能中的。这种行为的流行将戕害到整个 AI 行业。随着海投的水文越来越多,审稿需求就越来越大。审稿人的平均水准也相应越来越低,于是漏网之鱼的录用水文也越来越多。从此进入恶性循环。
如何避免科研误区?
科研误区可能是无心之失,或刻意而为。后者牵扯到太多利益纠葛,不多加讨论。但对于还对科研带有热情,有心做出有价值的工作的同行,我们在此想分享一份 机器学习避坑指南 ,互相提醒,互相勉励。

Warning:下文一半是搬运,一半是个人理解。感兴趣的朋友还请移步原文。
论文题目:
How to Avoid Machine Learning Pitfalls: A Guide for Academic Researchers
论文链接:
http://arxiv.org/abs/2108.02497
原作者热烈欢迎大家一起补充完善这份指南。
建模前需要做的准备
1. 花点时间了解你的数据
当你的数据来源可靠时,你训练的模型才可能可信。在使用来自网络的数据时,稍微看一眼,数据是哪里来的?有没有对应的文章或文档说明?如果有说明,多看几眼数据的采集方法,检查一下作者有没有提及数据的局限性(可能没有,所以还要自己多想想)。不要因为一个数据集被很多文章采用了,就假设它是可信的。即使是标杆级别的数据集,数据也可能没经过仔细筛选(请参见《Google掀桌了,GLUE基准的时代终于过去了?》)。而不靠谱的数据,只会导致 garbage in,garbage out。所以,在开始跑实验之前,先好好地探索一下你的数据吧!在工作开始的时候就对数据有一个整体把控,总比最后再不得不向审稿人解释你的模型表现是受到了垃圾数据影响要好。
2. 不要过度地分析数据
当你对数据集有一定了解之后,可能会发现一些肉眼可见的规律。但是, 千万不要基于初步的数据分析作出任何没经过检验的假设! 提出假设本身没有错,重点是避免“没经过检验”的假设,一方面是因为数据集都会带有偏差,你无法确定你发现的规律是不是基于特定的偏差的;另一方面,在没有区分训练和测试数据前就基于数据开始大胆猜测(带入先验知识),这其实也是测试数据泄漏到训练过程的一种形式。总之,轻率地提出假设对于模型的可靠性百害无一利,如果你发现之前很多论文都用了相同的假设,也请谨慎确定这个假设适用于你的数据。假如你发现这个领域长期公认的假设其实是不合理的——嗨呀,送上门的文章快写吧。
3. 确保你拥有足够的数据
这其实不止是对数据的要求,也要求你要对自己的模型有一定的了解:到底需要多少数据,才能保证你的模型的泛化性?此外,数据的“量”是否充足,和数据的“质”有一定的关联。如果数据中噪声太大,那即使量够大,也不一定能获得很好的模型训练效果。而如果数据类与类不均衡,模型的泛化性也会受到影响。如果数据因各式各样的原因不够充足,你可以考虑交叉验证、数据增强、均衡训练等操作,如果数据无论怎样操作都不足以支撑你的模型,那就趁早换个复杂度低一点的模型吧。
4. 和领域内的专家保持交流
领域内专家的意见是很重要的(特别是你的导师)。基于丰富的经验,他们能更好地估计研究的可行性和研究价值;对于研究结果的预期可能会更准确,因此当你误入歧途时,更可能及时地指出;而对于你的成果面向的受众也会更了解,能帮助你选择论文投稿的正确的期刊。因此,多和前辈们交流。记住,前辈不限于你的导师,院系内类似工作的老师、学长学姐都是可以请教的对象。多交流还能防自闭!
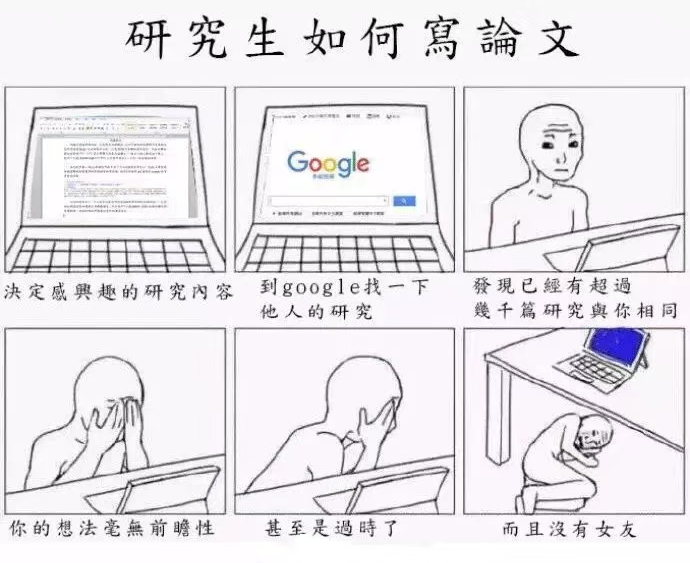
5. 好好做文献调研!好好做文献调研!
重复一遍是因为小轶觉得这点简直是坑中之坑!需要鞭策自己!
当你想到一个研究问题的时候,你很可能不是第一个想到的。 如果你没找到相关的研究,可能只是因为他人描述问题的形式和你不尽相同,更糟糕的是可能是因为你的问题根本不具备研究价值。无论哪种情况,都是由于文献调研还不够充分导致的。需要多读论文,然后通过交流讨论,确定这个研究问题能不能做下去。不要担心那些和你研究同一个问题的论文:创新性可以来自很多方面,新方法,新结论,新应用点,世界这么大,只要你会讲故事,没那么多论文能和你完全一样(真一样的话就说明是有缘人,发邮件交个朋友去吧)。前人的工作将为你提供很多宝贵的结论、经验、教训,也必然存在不完善的地方,沿着前人的不足做下去就好了。
6. 考虑好要如何部署模型
“你为什么一定要用深度学习模型?传统方法它不香吗?”这是每一篇应用机器学习模型的论文必须回答的问题。
目前,有很大一部分的机器学习模型并不具有实用价值,它们只代表了建模和数据分析的发展方向。如果只是运用机器学习模型,一定要注意模型的适用范围(实时性、计算力等),还要对如何魔改模型的输入输出心里有数。“因为没人把机器学习用在我的领域,所以我把模型套过来跑一跑”的行为早就饱受诟病了(详见《近期神奇机器学习应用大赏》)。
如何建立可靠的模型
1. 不要混淆训练和测试数据!
要使用能证明模型泛化性的测试集。 训练集上表现再好也可能只是过拟合,只有在一个尽可能贴近实际场景的测试集中表现过关,才能证明模型的训练是有效的。你的训练集中数据可以是在单一条件下采集的,但测试集中数据必须包括各式各样的情况。而且测试集和训练集绝对不能有重合。
2. 多尝试几个模型
根据 No Free Lunch 理论,任何的机器学习方法都不可能在所有领域表现最好。所以,当你将机器学习引入自己的领域的时候,多试几个模型,确保你用的是最合适的那一个,当然,也可能没有一个适合你 :)
3. 不要使用不合适的模型
由于现在机器学习的库太多了,生搬硬套的现象也越来越普遍。搞不清模型输入输出,只想用新兴神经网络炮轰一切问题的,看到个新模型就想拿来用的,是不是听起来就要血压升高?

4. 好好调参!好好调参!
重复一遍是因为白鹡鸰特别懒不喜欢调参需要鞭策自己
很多模型中都有超参数,它们对模型的表现影响重大,而不同的领域/数据集对超参数的要求又各有不同。所以,即使是懒,也必须采用一些自动化方法来调参,比如网格搜索,简单粗暴,我的挚爱。如果模型很大,训练成本高昂,甚至可以利用一些工具包帮忙调参。
需要指出的是,尽管经常会听到一些关于调参的诟病(类似于“这篇论文效果好完全是靠调参!”的抱怨),但是调参是有其必要性的。应该避免的是不规范的调参和不公平的实验比较方式。比如,不能用测试集数据调参;以及,不能仅对自己提出的模型疯狂调参,而应对所有使用中的模型都进行同等程度的调参方式等等。
5. 注意调参和选择特征的阶段
超参数调整和特征选择都应当是训练的一部分,而不是说训练之前运行一次就以为万事大吉。特别是特征选择,如果对整个数据集统一进行特征选择,很可能又会把测试数据和训练数据中包含的知识混在一起,导致测试结果不可靠,因此,最好只对你训练用的那一部分数据进行调参和特征选择。一种推荐的方法是嵌套交叉验证,这种方法在交叉验证外面再套了一圈验证,用来测试不同超参数和特征选择对模型的影响。
如何合理地评估模型
1. 选择合适的测试集
能够证明模型泛化性才是好的测试集。训练集上表现再好也可能只是过拟合,只有在一个尽可能贴近实际场景的测试集中表现过关,才能证明模型的训练是有效的。你的训练集中数据可以是在单一条件下采集的,但测试集中数据必须包括各式各样的情况。而且测试集和训练集绝对不能有重合。
2. 验证集是有必要的
在刚开始做机器学习的时候,我对于验证集的概念不甚清楚,也不明白为什么要掐出来那么多数据当验证集(甚至有人告诉过我验证集可有可无,谢谢您嘞!)。验证集主要是用在训练过程中,用来对比多个模型的表现的。当你需要同时训练好几个超参数设置不一样的模型时,帮助挑选这些模型的就是验证集。虽然测试集没有直接参与模型的训练,但它指导了训练的方向。验证集就是训练和测试之间的缓冲地带,保证了模型的训练集和测试集没有任何重叠。验证集的另一个好处就是,你可以用它来检查你的模型是否真的学到了数据的规律,见势不妙时可以趁早停下;如果模型在验证集中表现先升后降,很可能是模型过拟合的标志。
3. 一个模型多验证几次
机器学习的模型能有多不稳定,我相信所有用过GAN和RL的人都有话要说,随机采样训练样本的情况下,模型能往各种神奇的方向发展,收敛到各式各样的局部最优。这就是为什么我们需要交叉验证法,它能尽可能地保证模型训练效果,一定程度上防止过拟合。需要注意的是,如果数据集中存在类别不均衡的问题,最好保证每个验证组中都能包含所有类别。在交叉验证的过程中,强烈推荐大家记录每轮中测试的均值和方差,在比较模型表现时这些数据会起到重要作用。
4. 留点数据用于最终验证
在训练过程中,交叉验证可以很大程度上保证一类模型的训练效果的稳定性,但是,对于训练中的每个模型个体,这样的验证还不够充分,因为每组交叉验证的子集中数据量往往都不大,不一定具有泛化性,说不定,表现最好的模型只是恰好遇到了最简单的验证子集。因此,如果你的数据还算充裕,最好能留一部分数据,在训练结束之后再无偏验证一下模型们的表现。
5. 数据不均衡的时候,精度是没有意义的
数据采集不均衡的情况很常见。例如,很多的自动驾驶的数据集中,行人、自行车、卡车的数量加起来还没有小轿车多。这种情况下,用模型对交通参与物分类的精度作为衡量模型表现的标准,恐怕意义不大。这种情况下,应当先对不同类别样本的分类精度进行一致性检验,或者采用一些适用于不均衡数据的评估指标,例如Kappa系数,Matthews相关系数等。

如何公平地比较模型
1. 不要以为分高了模型就好
这真是非常常见的问题:“XX模型精度94%,我们的模型精度95%,所以我们nb”。然而,可能存在几种可能性:两个模型是在不同的数据集上测试的(直接毙了吧);两个模型用的同一个数据集,但是训练和测试集划分并不一样,特别有些论文,直接引用他人模型训练出来的精度,连复现都不带的(危);复现的模型超参数可能和原论文存在出入,或者没有费心去调参。总之,比较模型表现的时候,可能出现各种各样的事故,一定要记得将模型放在同样的起跑线上,进行同样的优化步骤,最后,多测试几次来证明模型的表现确实有显著的进步。
2. 比较模型时,用点统计学
看到这一条的时候,实在忍不住想到,现在比较模型的方法,有时甚至不如宝可梦对战。宝可梦好歹还可能因为属性和技能导致的胜负反转。模型之间就列一两个指标,拿着1%的差异说事。还是多用用压箱底的统计学知识吧,例如,比较分类器的时候可以上McNemar检验,检查模型对数据拟合的分布时,可以试试Student's T检验。关于模型到底有没有显著的改进这个问题,这些方法能够提供更有力的理论支撑。
3. 如何正确地比较多个模型
如果用了统计学的知识来好好验证模型效果,你需要注意到,比较多个模型的操作有点复杂。进行统计检验时,置信度往往设为95%,那么从统计学上来说,每20次检测就会有1次的结论可能不可信。而模型越多,比较次数越多,出现失误的概率也就越大。为了避免这一风险,比对模型后,应当进行矫正,Bonferroni校正便是一种常用的方法,能够简单地根据测试的数量修正显著性的阈值(这一操作目前仍然存在争议)。
Bonferroni 校正:如果在同一数据集上同时检验n个独立的假设,那么用于每一假设的统计显著水平,应为仅检验一个假设时的显著水平的1/n。
4. 不要盲信benchmark的结果
基准测试之所以存在,是希望大家使用统一的数据训练和测试模型,使模型之间更容易比较。但是,即使你自己的模型训练完全符合规范,也不能保证他人是否将测试集用于训练了。实际上,很多表现最好的模型可能只是恰好过拟合了测试集,泛化性未必有保障。总之,一定要谨慎地对待基准测试的结果,不要以为在基准数据集上有一点点性能提升就能证明模型的显著性。
5. 记得考虑集成模型
虽然有些人可能很嫌弃,但应用到子领域的的时候,能抓老鼠的就是好猫。缝合怪没有错。有时候,把不同的模型集成成为一个大一统模型,确实能够利用它们各自的特点补齐短板,提升模型在面对多样化场景时的泛化性。比如最近几年兴起的全景分割,目前最流行的操作就是把语义分割和像素分割的模型拼在一起,从而得到对前景中独立个体和背景内容的全面信息。集成模型的难点就是集成,如何结合每个子模型提取的数据特征,如何选择合理的输入和输出格式。我有一位朋友,似乎每天在因为这些问题愁得掉头发。
如何描述你的结果
1. 尽可能透明公开
机器学习领域的透明公开,一方面是指论文当中对实验关键步骤的详细描述,另一方面则是指公开代码。公开代码能够节约其他研究者复现论文的时间,也是督促你自己谨慎实验的动力。
2. 多角度评估表现
用多个数据集、多个指标显然能更好地评估模型的性能,比如实时性、泛用性、鲁棒性。
需要注意的是,如果你采用的指标非常常见,如AP,MSE,就别在论文里列公式了,占地方。但是如果你采用的指标是近年新出的,甚至是你自己新提出的,花上几行好好解释一下这个指标的意义吧!你论文的贡献说不定也包括这几行!
3. 不要轻易推广结论
“因为我的模型在XX数据集表现良好,它在XX任务上必然是未来之星“。这类说法不是很严谨,因为数据集永远是真实世界的子集,无论你是否看得见,偏差必然存在。虽然这个说法一般不会直接导致论文被拒,但可能成为需要大修的理由之一。
4. 谨慎地讨论显著性
统计检验不是万能的,不同的指标可能高估或低估模型之间的差异。在描述模型差异前,请先想清楚,这个差异重要吗?只要数据集足够大,哪怕模型性能相差无几,实际测试结果也必然存在差异。或许,效应量 (effect size)也是不错的选择,效应量可以量化模型之间差异的大小,例如Cohen's d,或者更为鲁棒的Kolmogorov-Smirnov。
5. 模型:请再多懂我一点
这一点我非常痛苦地赞同。看别人的论文时,我最关心的就是讨论部分,分析 一个模型为什么会表现好,机理上有什么改变。但这也是论文、尤其是使用机器学习的论文最难写的部分,因为很多作者自己都解释不清为什么模型性能表现好。想要提供模型的可解释性,目前最常见的做法就是可视化(我对你的爱,是为你而留的神经元~♡),XAI现在也在不断发展,可以参考的方法越来越多。好好写讨论,论文的可信度会上升不少,被接收/引用的概率也会显著提升。
尾声
这其实不仅仅是对跑实验过程的指南。如果按照这个规范来做实验,你会发现论文会变得很好写,而不是等要投稿了,再绞尽脑汁去想自己的工作到底有什么意义。因为你将有充分的理由去研究一个问题,有充分的理由把机器学习方法应用到这个问题上,你的实验过程是经得起推敲的,你的结果分析是面面俱到的。最终,你会发自内心地觉得自己没有浪费生命,而是真的做出了一份有价值的工作,并获得相当的成就感。
引用原作者的话作为结尾:
这份指南并不完善,未必告诉了你所有你应当知道的内容,提到的一些方法和技巧也是经验性的,它们可能在未来被证明有误,或者存在争议——但这恐怕是由研究的本性决定的。如何跑机器学习的方法论总是会落后于实践,学者们总会在最佳的做事方法上争论不休,而我们今日所信奉的正确可能在明天就会被证伪。因此,研究机器学习,其实与做其他研究无异:永远保持开放的思维,愿意跟进最新的研究进展,并保持谦逊,承认你并非无所不知。
祝大家新年快乐!
萌屋作者:白鹡鸰
白鹡鸰(jí líng)是一种候鸟,浪形的飞翔轨迹使白鹡鸰在卖萌屋中时隐时现。已在上海交大栖息四年,进入了名为博士的换毛期。目前蹲在了驾驶决策的窝里一动不动,争取早日孵出几篇能对领域有贡献的论文~
知乎ID也是白鹡鸰,欢迎造访。
作品推荐:
 萌屋作者:白鹡鸰
萌屋作者:白鹡鸰
萌屋作者:小轶
是小轶,不是小秩!更不要叫小铁!高冷的形象是需要大家共同维护的!作为成熟的大人,正在勤俭节约、兢兢业业,为成为一名合格的(但是仍然发量充足的)PhD而努力着。日常沉迷对话系统。说不定,正在和你对话的,并不是不是真正的小轶哦(!?)
“高冷?那是站在冰箱顶端的意思啦。” ——白鹡鸰
作品推荐:
 萌屋作者:小轶
萌屋作者:小轶
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【




