【AlphaGoZero核心技术】深度强化学习知识资料全集(论文/代码/教程/视频/文章等)
点击上方“专知”关注获取更多AI知识!
【导读】昨天 Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知特别收录整理聚合了关于强化学习的最全知识资料,欢迎大家查看!
先看下Google DeepMind 研究人员David Silver介绍 AlphaGo Zero:
专知 -Deep Reinforcement Learning 最全资料集合:
Nature 论文
Mastering the game of Go without human knowledge
Nature 550, 7676 (2017). doi:10.1038/nature24270
Authors: David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel & Demis Hassabis
网址:https://www.nature.com/nature/journal/v550/n7676/full/nature24270.html
请下载pdf查看!

Mastering the game of Go with deep neural networks and tree search
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Vedavyas Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy P. Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, Demis Hassabis:
Nature 529(7587): 484-489 (2016)
Papers
Mastering the Game of Go without Human Knowledge |
https://deepmind.com/documents/119/agz_unformatted_nature.pdf |
Human level control with deep reinforcement learning |
http://www.nature.com/nature/journal/v518/n7540/full/nature14236.html |
Play Atari game with deep reinforcement learning |
https://www.cs.toronto.edu/%7Evmnih/docs/dqn.pdf |
Prioritized experience replay |
https://arxiv.org/pdf/1511.05952v2.pdf |
Dueling DQN |
https://arxiv.org/pdf/1511.06581v3.pdf |
Deep reinforcement learning with double Q Learning |
https://arxiv.org/abs/1509.06461 |
Deep Q learning with NAF |
https://arxiv.org/pdf/1603.00748v1.pdf |
Deterministic policy gradient |
http://jmlr.org/proceedings/papers/v32/silver14.pdf |
Continuous control with deep reinforcement learning) (DDPG) |
https://arxiv.org/pdf/1509.02971v5.pdf |
Asynchronous Methods for Deep Reinforcement Learning |
https://arxiv.org/abs/1602.01783 |
Policy distillation |
https://arxiv.org/abs/1511.06295 |
Control of Memory, Active Perception, and Action in Minecraft |
https://arxiv.org/pdf/1605.09128v1.pdf |
Unifying Count-Based Exploration and Intrinsic Motivation |
https://arxiv.org/pdf/1606.01868v2.pdf |
Incentivizing Exploration In Reinforcement Learning With Deep Predictive Models |
https://arxiv.org/pdf/1507.00814v3.pdf |
Action-Conditional Video Prediction using Deep Networks in Atari Games |
https://arxiv.org/pdf/1507.08750v2.pdf |
Control of Memory, Active Perception, and Action in Minecraft |
https://web.eecs.umich.edu/~baveja/Papers/ICML2016.pdf |
PathNet |
https://arxiv.org/pdf/1701.08734.pdf |
Papers for NLP
| Coarse-to-Fine Question Answering for Long Documents | https://homes.cs.washington.edu/~eunsol/papers/acl17eunsol.pdf |
| A Deep Reinforced Model for Abstractive Summarization | https://arxiv.org/pdf/1705.04304.pdf |
| Reinforcement Learning for Simultaneous Machine Translation | https://www.umiacs.umd.edu/~jbg/docs/2014_emnlp_simtrans.pdf |
| Dual Learning for Machine Translation | https://papers.nips.cc/paper/6469-dual-learning-for-machine-translation.pdf |
| Learning to Win by Reading Manuals in a Monte-Carlo Framework | http://people.csail.mit.edu/regina/my_papers/civ11.pdf |
| Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning | http://people.csail.mit.edu/regina/my_papers/civ11.pdf |
| Deep Reinforcement Learning with a Natural Language Action Space | http://www.aclweb.org/anthology/P16-1153 |
| Deep Reinforcement Learning for Dialogue Generation | https://arxiv.org/pdf/1606.01541.pdf |
| Reinforcement Learning for Mapping Instructions to Actions | http://people.csail.mit.edu/branavan/papers/acl2009.pdf |
| Language Understanding for Text-based Games using Deep Reinforcement Learning | https://arxiv.org/pdf/1506.08941.pdf |
| End-to-end LSTM-based dialog control optimized with supervised and reinforcement learning | https://arxiv.org/pdf/1606.01269v1.pdf |
| End-to-End Reinforcement Learning of Dialogue Agents for Information Access | https://arxiv.org/pdf/1609.00777v1.pdf |
| Hybrid Code Networks: practical and efficient end-to-end dialog control with supervised and reinforcement learning | https://arxiv.org/pdf/1702.03274.pdf |
| Deep Reinforcement Learning for Mention-Ranking Coreference Models | https://arxiv.org/abs/1609.08667 |
精选文章
| wiki | https://en.wikipedia.org/wiki/Reinforcement_learning |
| Deep Reinforcement Learning: Pong from Pixels | http://karpathy.github.io/2016/05/31/rl/ |
| CS 294: Deep Reinforcement Learning | http://rll.berkeley.edu/deeprlcourse/ |
| 强化学习系列之一:马尔科夫决策过程 | http://www.algorithmdog.com/%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0-%E9%A9%AC%E5%B0%94%E7%A7%91%E5%A4%AB%E5%86%B3%E7%AD%96%E8%BF%87%E7%A8%8B |
| 强化学习系列之九:Deep Q Network (DQN) | http://www.algorithmdog.com/drl |
| 强化学习系列之三:模型无关的策略评价 | http://www.algorithmdog.com/reinforcement-learning-model-free-evalution |
| 【整理】强化学习与MDP | http://www.cnblogs.com/mo-wang/p/4910855.html |
| 强化学习入门及其实现代码 | http://www.jianshu.com/p/165607eaa4f9 |
| 深度强化学习系列(二):强化学习 | http://blog.csdn.net/ikerpeng/article/details/53031551 |
| 采用深度 Q 网络的 Atari 的 Demo: Nature 上关于深度 Q 网络 (DQN) 论文: |
http://www.nature.com/articles/nature14236 |
| David视频里所使用的讲义pdf | https://pan.baidu.com/s/1nvqP7dB |
| 什么是强化学习? | http://www.cnblogs.com/geniferology/p/what_is_reinforcement_learning.html |
| DavidSilver 关于 深度确定策略梯度 DPG的论文 | http://www.jmlr.org/proceedings/papers/v32/silver14.pdf |
| Nature 上关于 AlphaGo 的论文: | http://www.nature.com/articles/nature16961 |
| AlphaGo 相关的资源 | deepmind.com/research/alphago/ |
| What’s the Difference Between Artificial Intelligence, Machine Learning, and Deep Learning? | https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/ |
| Deep Learning in a Nutshell: Reinforcement Learning | https://devblogs.nvidia.com/parallelforall/deep-learning-nutshell-reinforcement-learning/ |
| Bellman equation | https://en.wikipedia.org/wiki/Bellman_equation |
| Reinforcement learning | https://en.wikipedia.org/wiki/Reinforcement_learning |
| Mastering the Game of Go without Human Knowledge | https://deepmind.com/documents/119/agz_unformatted_nature.pdf |
| Reinforcement Learning(RL) for Natural Language Processing(NLP) | https://github.com/adityathakker/awesome-rl-nlp |
视频教程
| 强化学习教程(莫烦) | https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/ |
| 强化学习课程 by David Silver | https://www.bilibili.com/video/av8912293/?from=search&seid=1166472326542614796 |
| CS234: Reinforcement Learning | http://web.stanford.edu/class/cs234/index.html |
| 什么是强化学习? (Reinforcement Learning) | https://www.youtube.com/watch?v=NVWBs7b3oGk |
| 什么是 Q Learning (Reinforcement Learning 强化学习) | https://www.youtube.com/watch?v=HTZ5xn12AL4 |
| 强化学习-莫烦 | https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/ |
| David Silver深度强化学习第1课 - 简介 (中文字幕) | https://www.bilibili.com/video/av9831889/ |
| David Silver的这套视频公开课(Youtube) | https://www.youtube.com/watch?v=2pWv7GOvuf0&list=PL7-jPKtc4r78-wCZcQn5IqyuWhBZ8fOxT |
| David Silver的这套视频公开课(Bilibili) | http://www.bilibili.com/video/av9831889/?from=search&seid=17387316110198388304 |
| Deep Reinforcement Learning | http://videolectures.net/rldm2015_silver_reinforcement_learning/ |
Tutorial
Reinforcement Learning for NLP http://www.umiacs.umd.edu/~jbg/teaching/CSCI_7000/11a.pdf ICML 2016, Deep Reinforcement Learning tutorial http://icml.cc/2016/tutorials/deep_rl_tutorial.pdf DQN tutorial https://medium.com/@awjuliani/simple-reinforcement-learning-with-tensorflow-part-4-deep-q-networks-and-beyond-8438a3e2b8df#.28wv34w3a 代码
OpenAI Gym https://github.com/openai/gym GoogleDeep Mind 团队深度 Q 网络 (DQN) 源码: http://sites.google.com/a/deepmind.com/dqn/ ReinforcementLearningCode https://github.com/halleanwoo/ReinforcementLearningCode reinforcement-learning https://github.com/dennybritz/reinforcement-learning DQN https://github.com/devsisters/DQN-tensorflow DDPG https://github.com/stevenpjg/ddpg-aigym A3C01 https://github.com/miyosuda/async_deep_reinforce A3C02 https://github.com/openai/universe-starter-agent
特注:
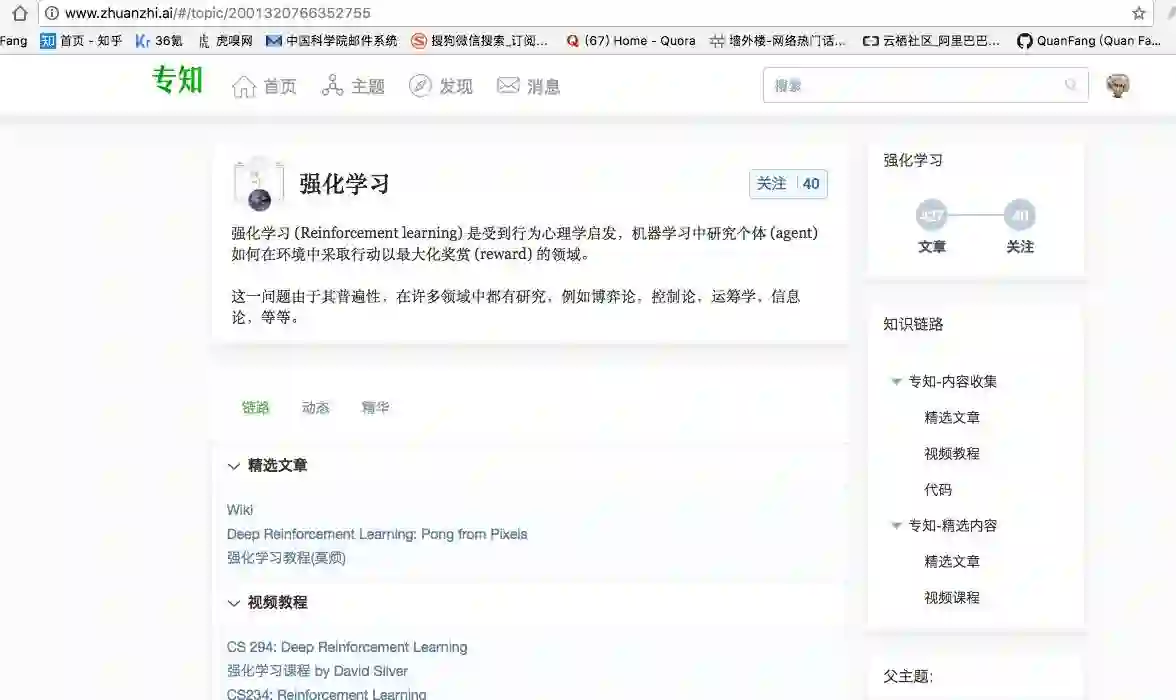
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取全部知识资料的pdf文档集合下载链接!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!




