机器学习教你学习语言:Duolingo推出CEFR语言检测器
选自duolingo
作者:Bill McDowell、Burr Settles
机器之心编译
参与:高璇、Geek AI
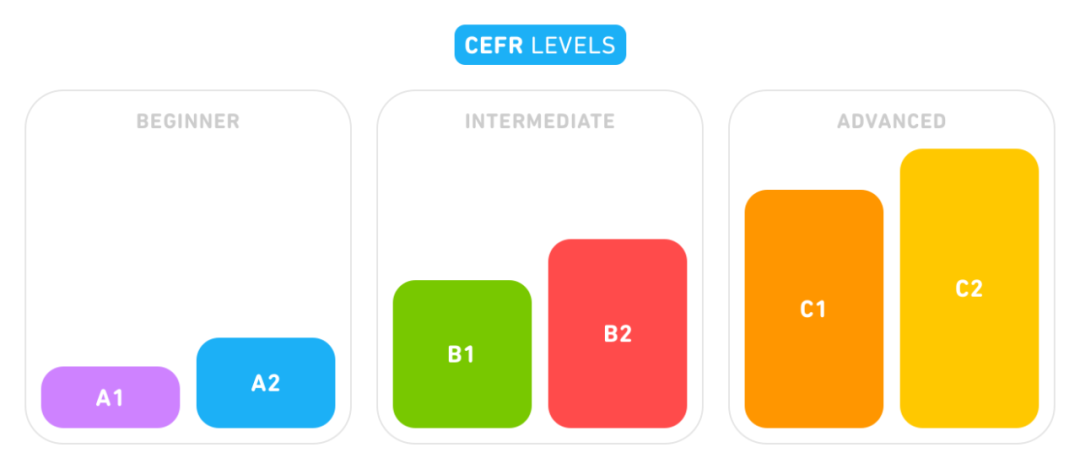
随着人工智能发展逐渐进入「深水区」,越来越多的研究者把目光投向了使用人工智能增强人类智能的研究领域。 近日,语言学习平台 Duolingo 针对欧洲语言共同参考框架(CEFR)推出了 CEFR 检测器,能够自动为不同层次的语言学习者提供同级学习文本改写服务。

结语
https://making.duolingo.com/the-duolingo-cefr-checker-an-ai-tool-for-adapting-learning-content
登录查看更多
相关内容
Arxiv
4+阅读 · 2018年1月26日



相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月26日