Facebook 推出多模态通用模型 FLAVA,吊打 CLIP 平均十个点!

文 | 子龙
编 | 智商掉了一地
厉害了!作者将单一模型运用于三个不同领域的不同任务,结构简单且训练直观,还能有着出色的表现。
自Transformer横空出世,从NLP到CV,再到今天的多模态,无数基于Transformer的模型被应用于各类任务,似乎真的印证了当年文章的标题“Transformer is ALL you need”。然而,纯粹的NLP任务有BERT、RoBERTa,CV任务有ViT,多模态任务又有VLBERT、OSCAR,虽然都是基于Transformer的结构,但是仍然是针对不同任务设计不同模型,那么“万能”的Transformer能否构建出一个统合各类任务的模型,实现真的的一个模型解决所有问题呢?
今天文章的作者就关注到了当前各个模型的局限,提出了一个适用于NLP+CV+多模态的模型FLAVA,可运用于三种领域共计35个任务,且都有着出色的表现。
论文题目:
FLAVA: A Foundational Language And Vision Alignment Model
论文链接:
https://arxiv.org/abs/2112.04482
![]() 介绍
介绍![]()
 介绍
介绍文章标题中,作者称模型为“Foundational”,他们不希望借助各种奇技淫巧的Tricks,而是通过尽可能简单的结构,配合直观的的训练手段,达到涵盖NLP、CV、多模态的目的。
FLAVA基于三种不同的输入:
-
匹配的图片-文本 -
单独文本 -
单独图片
解决三个领域的问题:
-
NLP:语言理解(如GLUE) -
CV:视觉识别(如ImageNet) -
多模态:多模态解释(如VQA)
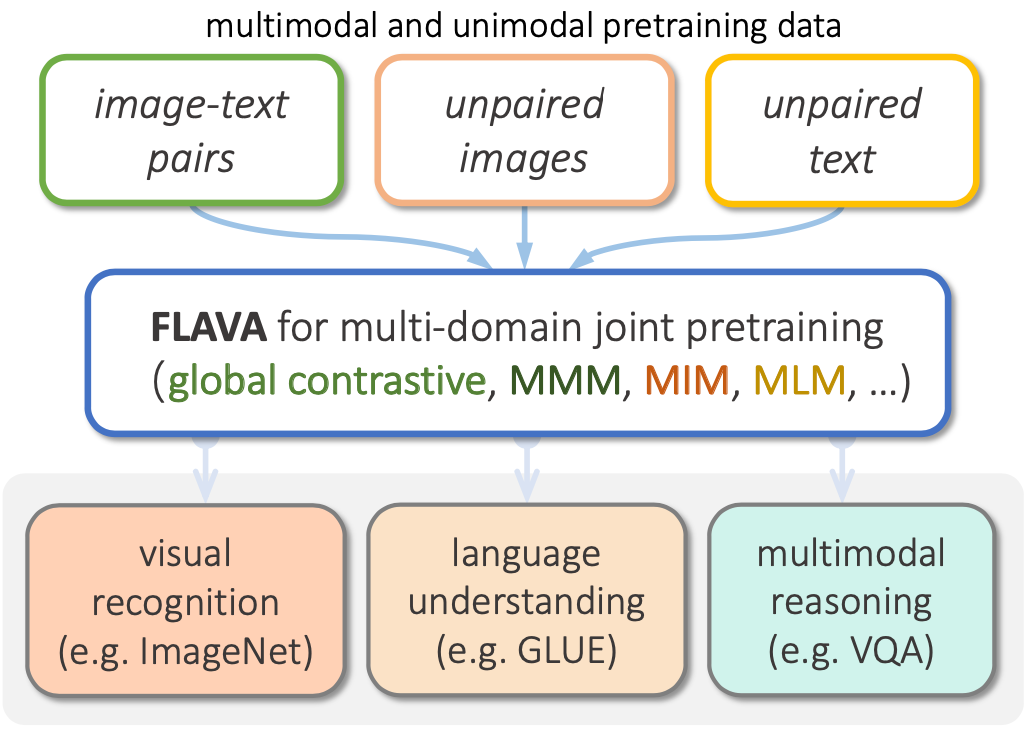

图片编码器(Image Encoder)
FLAVA直接借用既有模型ViT的结构,同时仿照ViT的处理方法,分割图片进行编码。在ViT输出的隐状态上,FLAVA利用单一模态数据集中的图片进行Masked Image Modeling。首先,利用dVAE将图片转化为类似词向量的token;再参照BEiT,对masked隐状态进行分类,即利用周围图片分块,预测masked的图片属于dVAE划分的哪一类,这样在图片上也可以像BERT那样做mask modeling。
文本编码器(Text Encoder)
FLAVA在文本部分多处理就相对简单,作者采取常见的Masked Language Modeling,对一部分masked token进行预测,和其他方法对区别在于,FLAVA没有采用BERT之类纯文本语言模型的结构,而是和图片编码器一样,使用了ViT的结构,不过因为是不同的模态,自然采用了不同的模型参数。
多模态编码器(Multimodal Encoder)
在图片编码器和文本编码器之上,FLAVA添加了一层多模态编码器做模态融合,多模态编码器将前两者输出的隐藏状态作为输入,同样利用ViT的模型结构进行融合。
多模态预训练
在文本编码器和图片编码器中,FLAVA在单一模态上进行了预训练,在多模态预训练方面,FLAVA使用了三种多模态预训练任务:
-
对比学习:FLAVA利用图片编码器和文本编码器的隐藏状态,增大相匹配的图片-文本对之间的余弦相似度,减小非匹配的图片-文本对之间的余弦相似度。 -
Masked Multimodal Modeling:与图片编码器上的MIM类似,只不过改为利用多模态编码器的隐状态进行预测。 -
图片-文本匹配:与许多现有模型一样,FLAVA利用多模态编码器的[CLS]的隐状态,识别当前图片与文本是否匹配。
![]() 效果
效果![]()
从上述模型细节可以看出,无论是模型结构,还是预训练任务,文本与图片之间高度对称,同时也设计也十分直观。接下来看看在35个任务上的表现。
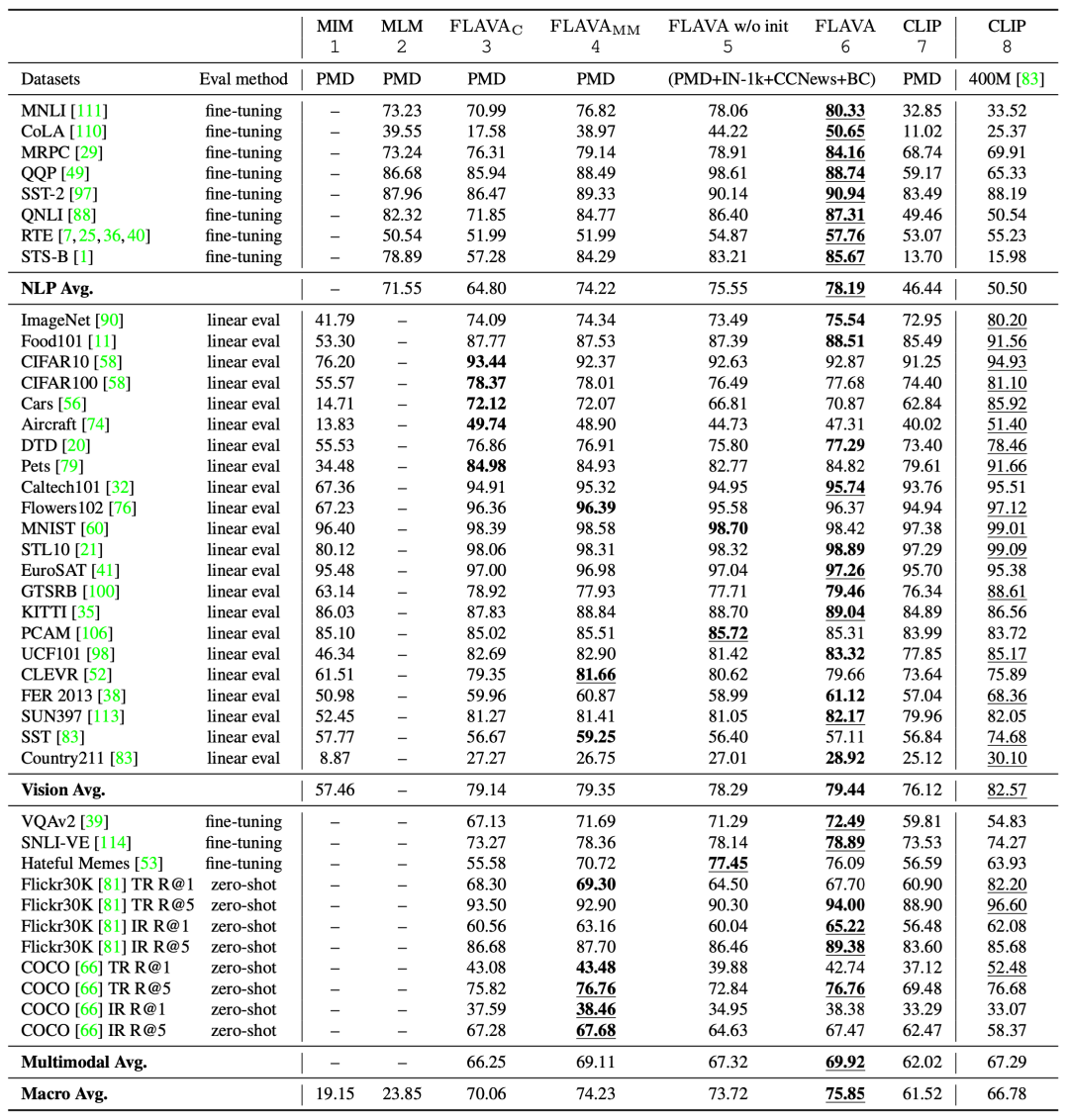
图中下划线表示最优结果,加粗表示在公开数据集上训练的最优结果。
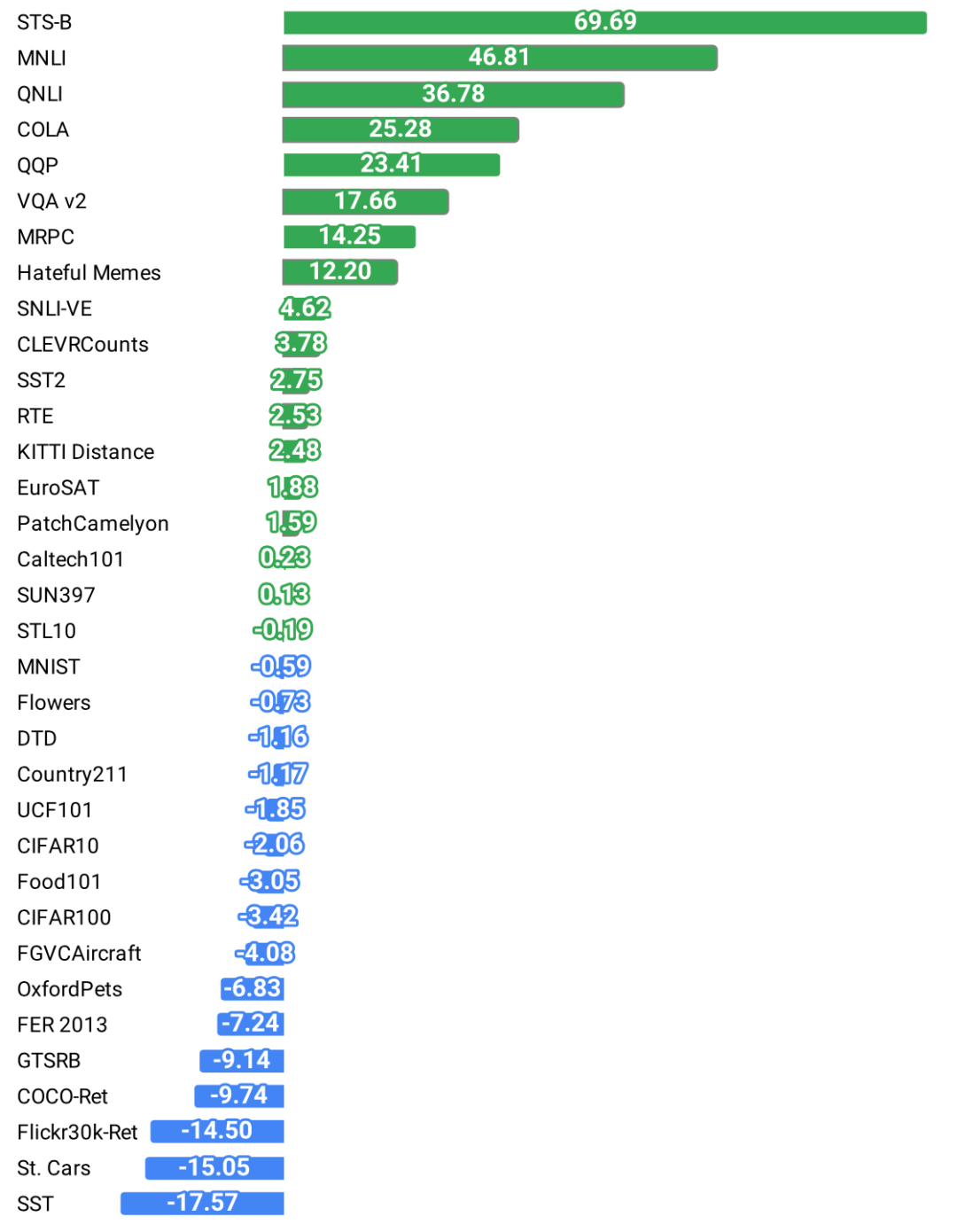
从各个任务平均上看,FLAVA能够取得整体上的最优结果,多模态任务平均比CLIP高出2个百分点左右,整体平均比CLIP高出10个百分点左右。从具体任务上看,在不少任务上都取得了十分显著的提高,如STS-B数据集提高了69.69,MNLI数据集提高了46.81。
![]() 小结
小结![]()
不同于现有模型,FLAVA最大的特点,也可以说是创新点,在于作者实现了将单一模型运用于三个不同领域的不同任务,而且都有着不错的效果,虽然FLAVA并没有奇迹般在所有任务上都达到SOTA,但是整体性能上并不弱于现有模型,同时有着更广阔的运用场景,模型设计也没有各种奇技淫巧,这对未来研究通用模型有着很大的启发。
萌屋作者:子龙(Ryan)
本科毕业于北大计算机系,曾混迹于商汤和MSRA,现在是宅在UCSD(Social Dead)的在读PhD,主要关注多模态中的NLP和data mining,也在探索更多有意思的Topic,原本只是贵公众号的吃瓜群众,被各种有意思的推送吸引就上了贼船,希望借此沾沾小屋的灵气,paper++,早日成为有猫的程序员!
作品推荐:
 萌屋作者:子龙(Ryan)
萌屋作者:子龙(Ryan)
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【