复旦大学邱锡鹏教授:词法、句法分析研究进展综述

本文为第十六届自然语言处理青年学者研讨会 YSSNLP2019 报告《词法、句法分析研究进展综述》的简要文字整理,本报告主要回顾词法、句法领域的最新研究进展。
关于报告人:
邱锡鹏,复旦大学计算机科学技术学院副教授,博士生导师。于复旦大学获得理学学士和博士学位。主要从事自然语言处理、深度学习等方向的研究,在 ACL、EMNLP、IJCAI 等计算机学会 A/B 类期刊、会议上发表 50 余篇学术论文,引用 1600 余次。开源中文自然语言处理工具 FudanNLP 作者。2015 年入选首届中国科协人才托举工程,2017 年 ACL 杰出论文奖,2018 年获中国中文信息学会“钱伟长中文信息处理科学技术奖—汉王青年创新奖”。

大家好,我是邱锡鹏。今天非常荣幸给大家简要分享一下 NLP 中词法和句法分析领域的最新研究进展。
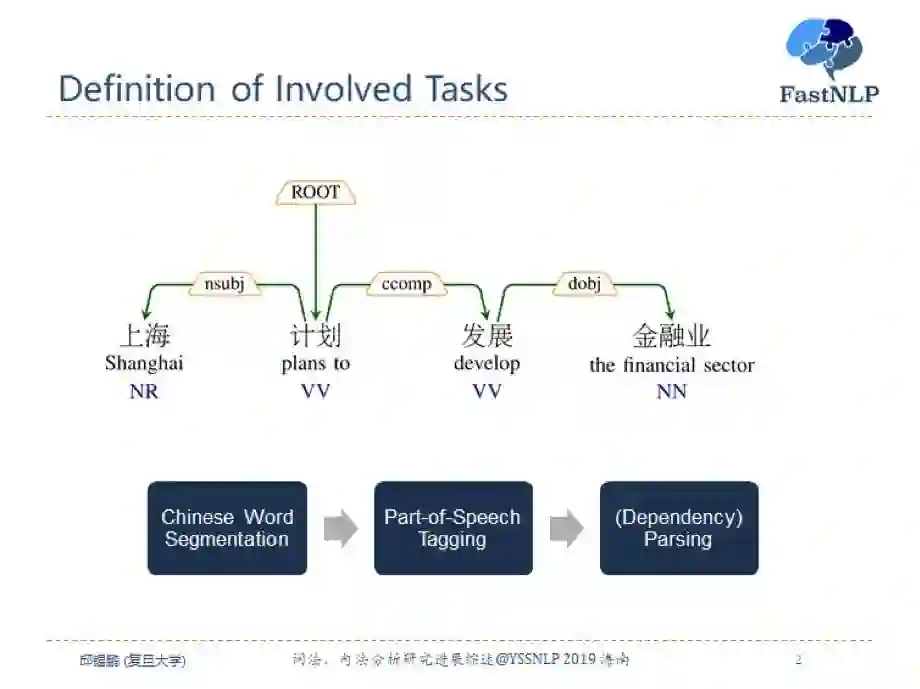
首先,我们来看一下词法和句法分析中的任务定义。我们一般认为词是语言中的最小语义单位,所以在进行后续的很多 NLP 任务的时候,需要先进行(中文)分词,标注它的词性,并分析句子的句法结构。像这里给的一个句子“上海计划发展金融业”,首先需要将其进行分词,然后进行词性标注和句法分析。这里我们的句法分析主要以依存句法分析为主进行介绍,建立词与词之间的依赖关系。因此我们这里主要涉及三个任务:中文分词,词性标注和依存句法分析。
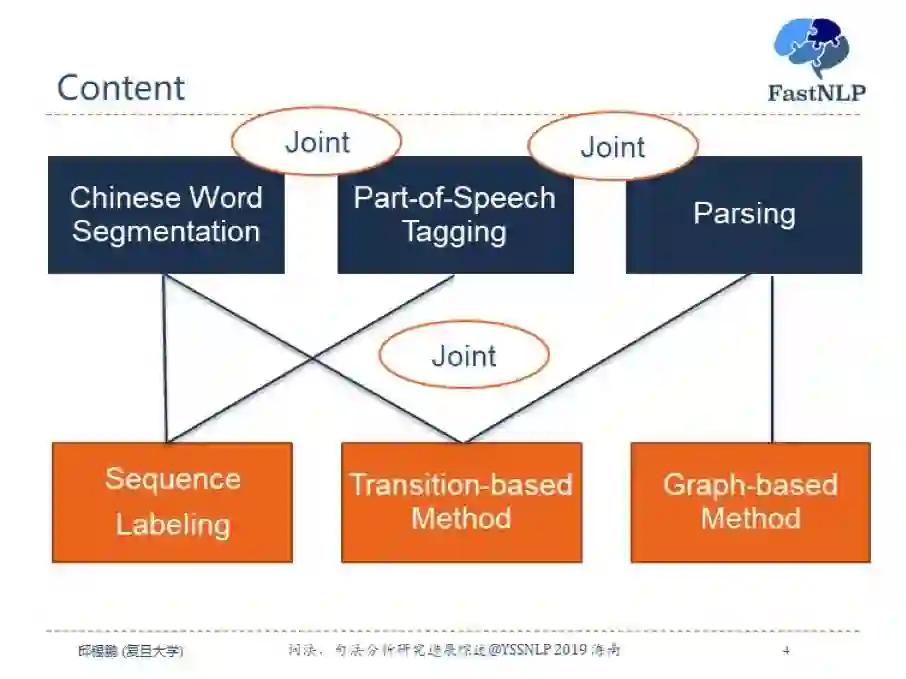
目前用来解决这三个任务的基本方法可以分为序列标注方法,基于转移的方法和基于图的方法三种。为了解决错误传播问题,一般来说,我们可以将这三个任务进行联合建模,比如中文分词和词性标注的联合模型、词性标注和句法分析的联合模型、以及三个任务的全联合模型。

这三个任务的最新研究进展和 SOTA 模型都可以从 NLP-Progress 这个网站进行查询。
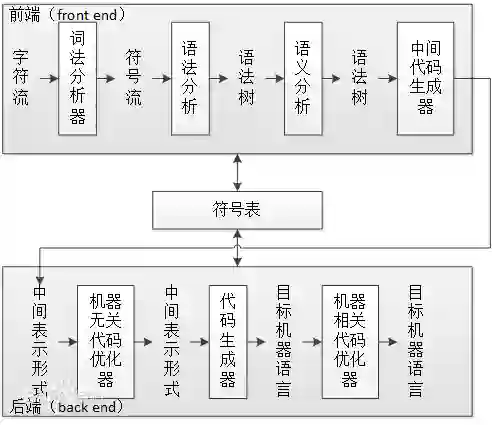
中文分词

首先我们来看一下中文分词。
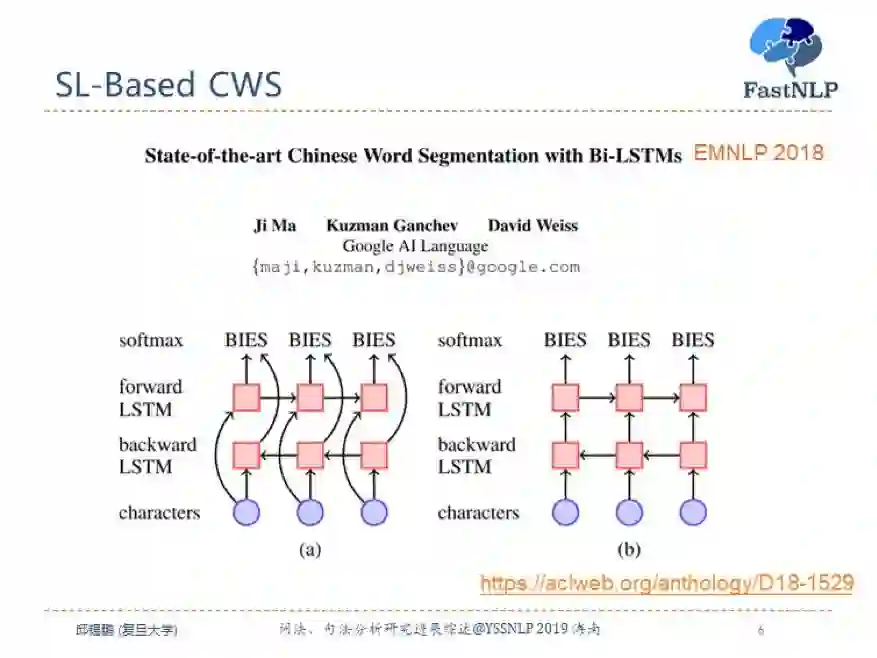
目前中文分词最好的模型是来自 EMNLP 2018 的一篇论文,采用了基于堆叠双向长短期记忆网络的序列标注模型。
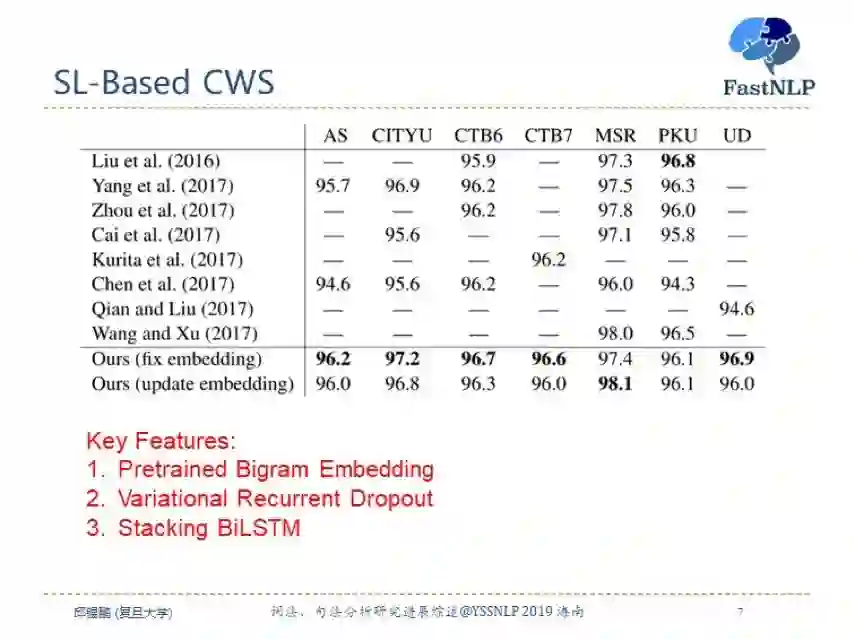
该方法虽然在模型上并没有太多的创新,但是其采用了预训练 bigram embedding 和变分 droupout 方法以及堆叠双向长短期记忆网络的微创新,训练了一个相对较深的网络,在解码时直接使用一个 softmax 分类器,而不用 CRF。在多个数据集上达到了最好的效果。

基于序列标注的方法是给字进行打标签,很难利用到词级别的信息。为了引入词级别的信息可以采用以下三种方法:基于转移的方法、Semi-CRF 和 DAG-LSTM/Lattice-LSTM。下面我分别简要介绍一下这三种方法。

基于转移的方法是通过转移动作序列来进行分词,即从左往右判断一个每两个相邻的字是分还是不分。这是一种贪婪的方法。在中间某一步时,我们已经有之前分好词的信息,所以可以利用词级别的信息来进行建模。
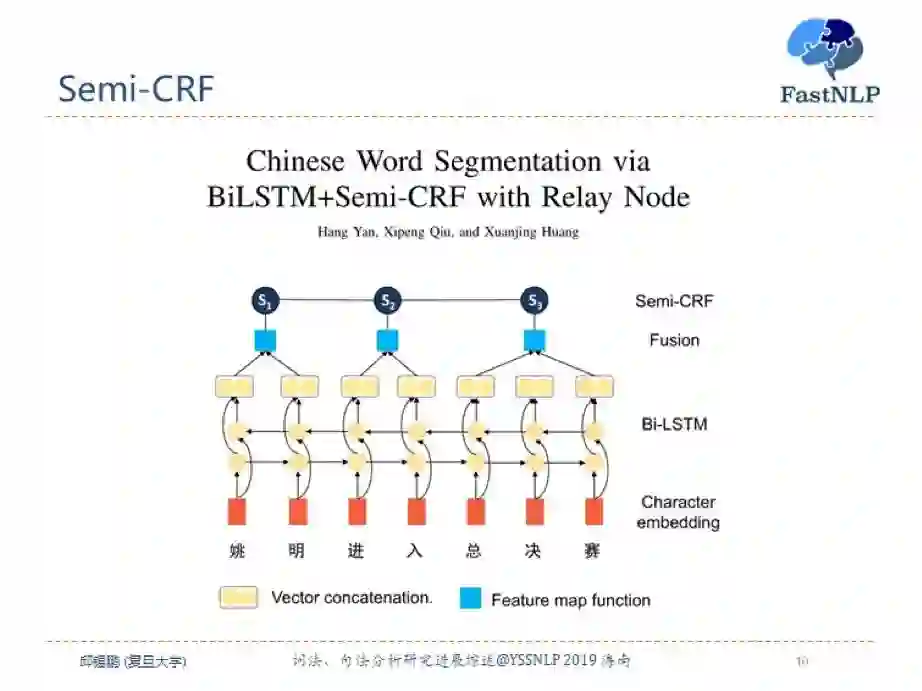
第二种利用词级别信息的方法是利用 Semi-CRF 模型,直接建模不同词之间的依赖关系。一般来讲,可以先统一通过一个双向的循环神经网络来提取字别的信息,然后使用一个融合方法来生成词级别的信息,最后输入 Semi-CRF 层来进行分词。Semi-CRF 的缺点是候选词有一个最大长度限制,我们提出了一种改进方法,目前正在投稿中。

第三种利用词级别信息的方法是是改进 LSTM 模型,将链式结构扩展到 DAG 结构。我们可以用一个事先准备好的词典,对句子进行预分割,把所有的分割可能性都组合出来。这样我们模型的输入是有多个字和词构成的混合序列,构成一个 DAG 结构。针对这种结构,我们提出一种 DAG-LSTM 来进行序列标注。

在中文分词中,有一个问题是很多不同的分词标准。之前的方法都是在单个标准上进行训练模型。我们知道,不同的分词标准之间有很多共通的特性。如这个表中所示,三个不同标准存在部分重叠,因此我们可以同时利用多个不同标准的数据进行联合训练,通过多任务学习来辅助提高每个单独标准的分词能力。

这里介绍一个我们在多标准分词上面的最新工作,所有不同的标准都共享一个模型,由于 Transformer 的强大能力,我们用一个共享的 Transformer 来进行编码,解码用一个共享的 MLP 或 CRF。然后增加一个额外的 Criterion ID,用来指示模型输出哪个标准的结果。目前这个模型在所有的分词任务上都达到了最好的效果。
词性标注

词性标注一般来讲比较简单,所以很少有单独工作来专门的词性标注任务。一般都是词性标注和其他任务相结合。首先我们来看一下联合的中文分词和词性标注任务。
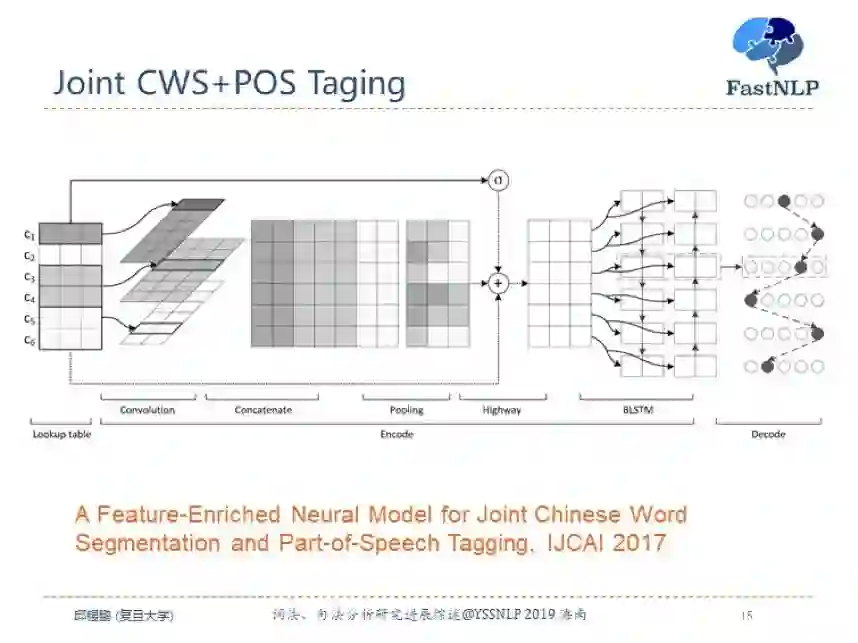
第一种方法是基于字的序列标注方法,使用“BMES”和词性的交叉标签来给每个字打标签。比如“B-NN”、“S-NR”等。相比于中文分词,分词和词性的联合任务需要更多的特征,因此我们可以用更复杂的网络来进行抽取特征。
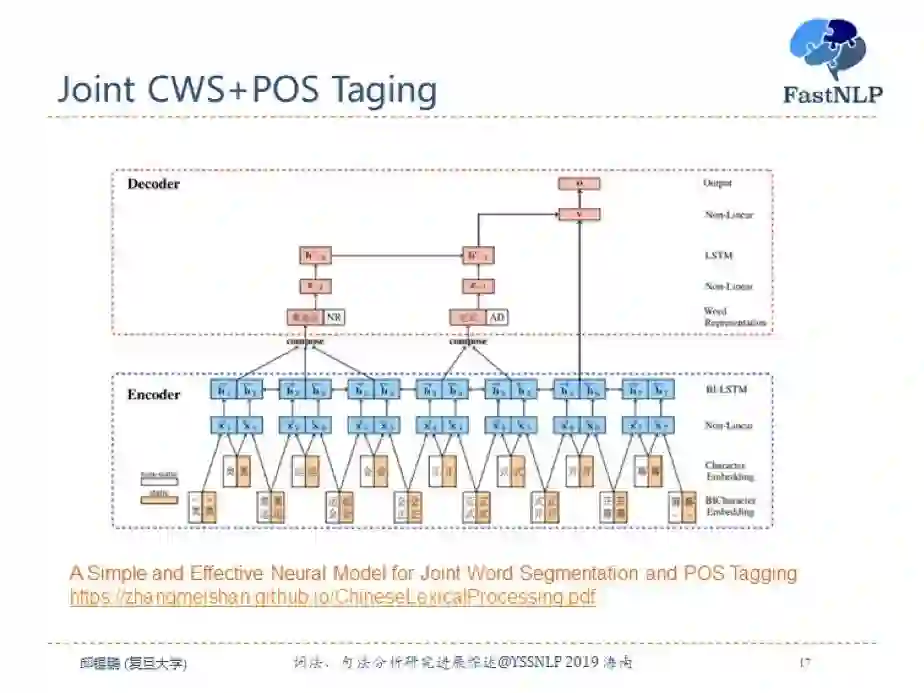
第二种方法是基于转移的方法,首先利用一个 BiLSTM 编码器来提取上下文特征,在解码时每一步都预测一个动作。动作的候选集合为是否分词以及词性。
依存句法分析

接下来介绍下句法分析的最新进展,这里主要以依存句法分析为主。在深度学习之前,依存句法分析就分为基于转移的方法和基于图的方法。近几年,分别出现了针对这两种不同方法的神经网络模型。

首先来看下基于转移的方法,通过 shift-reduce 两个基本的动作来将序列转换为树结构。首先用一个 buffer 来存储所有未处理的输入句子,并用一个栈来存储当前的分析状态。
动作可以分为:1)shift,即将 buffer 中的一个词移到栈中;2)left_arc(x),即栈顶两个词 a,b 为 a<-b 的依赖关系,关系种类为 x;3)right_arc(x),即栈顶两个词 a,b 为 a->b 的依赖关系,关系种类为 x。后两种动作为 reduce 动作。
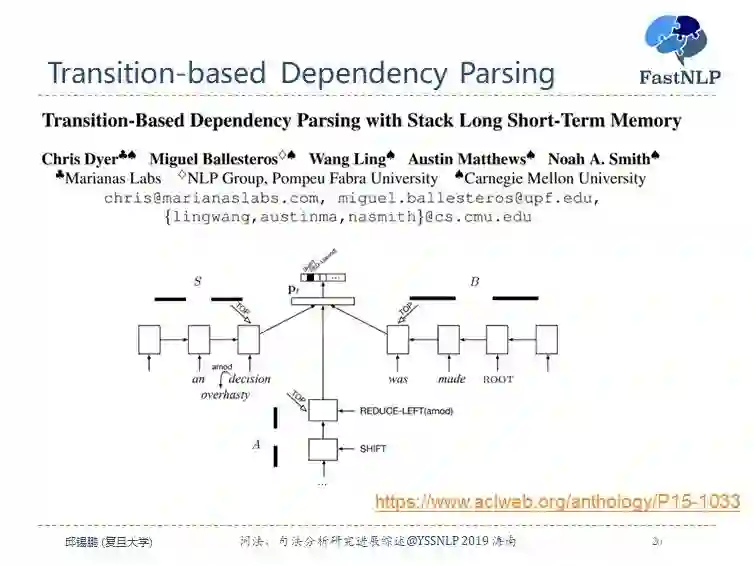
目前基于转移的方法的最好模型是 Stack LSTM,通过三个 LSTM 来分别建模栈状态、待输入序列和动作序列。 其中因为栈需要入栈和出栈,因此作者提出了一个 Stack LSTM 来建模栈状态。
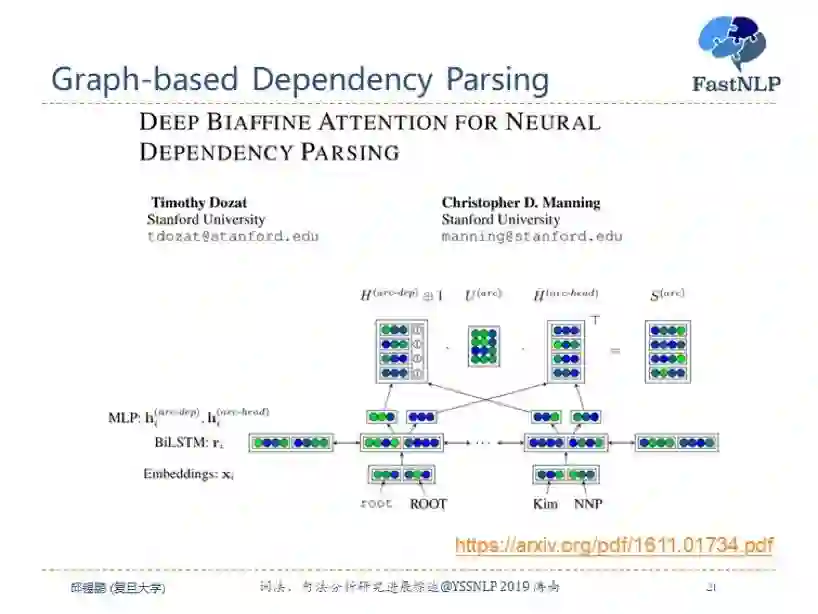
虽然基于 Stack LSTM 取得了非常好的效果,但是在目前的依存句法分析中,最流行的方法是基于图的方法经典的方法是 Biaffine 模型。直接用神经网络来预测每两个词之间存在依存关系的概率,这样我们就得到一个全连接图,图上每个边代表了节点 a 指向节点 b 的概率。然后使用MST等方法来来将图转换为一棵树。
Biaffine 模型其实和我们目前全连接自注意力模型非常类似。Biaffine 模型十分简单,并且容易理解,并且在很多数据集上都取得了目前最好的结果。
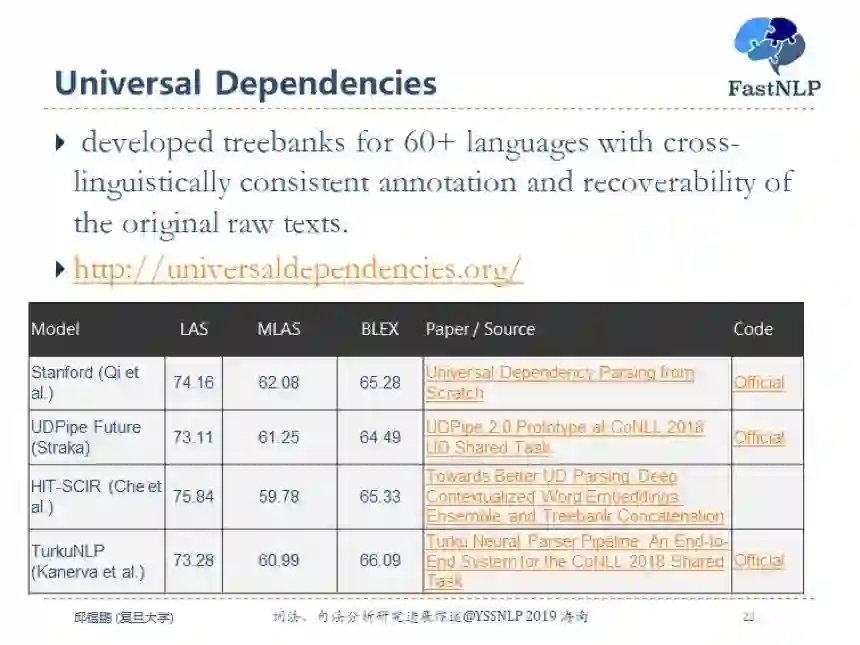
除模型外,目前依存句法分析主要关注于多语言的依存通用依存分析。目前一个数据集是 universal dependenies,其中有很多问题值得研究,比如多任务学习、迁移学习、通用语言表示等。
词性标注 & 句法分析

很自然地我们可以将词性标注和句法分析作为联合任务来进行建模。
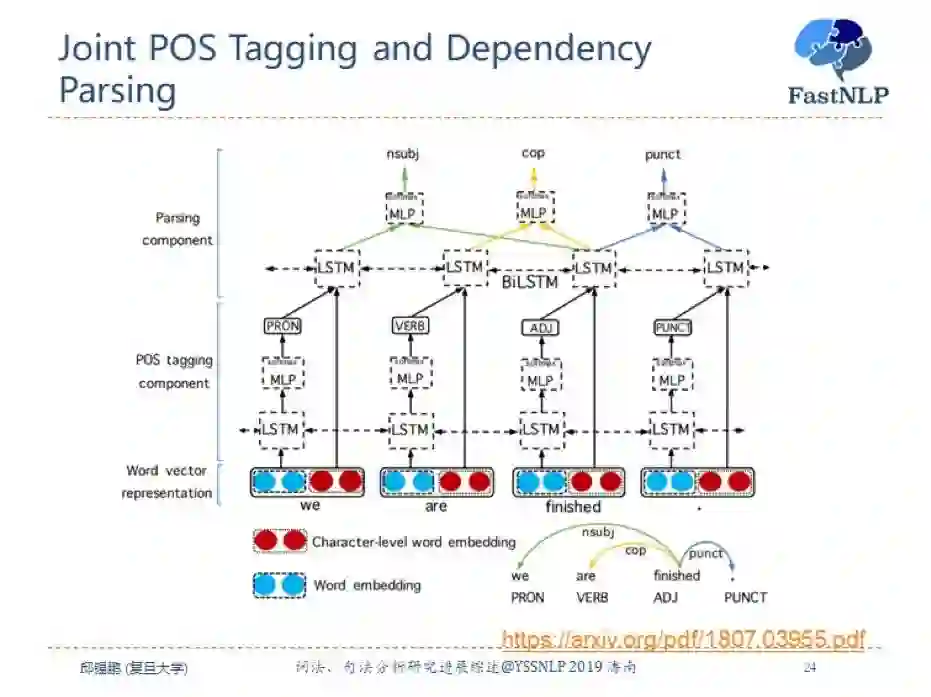
联合的词性标注和句法分析方法有很多,可以是基于转移的方法也可以是基于图的方法。这里介绍一种比较简单的方法,首先利用 LSTM 来预测词性,然后用词性信息和词信息一起用另外一个 LSTM 进行建模,并用 Biaffine 模型进行句法分析。
中文分词 & 句法分析

在中文方面,句法分析是基于词级别的,所以在做句法分析之前要先进行分词。那么我们是不是可以将中文分词和句法分析也作为一个联合任务来同时进行呢?
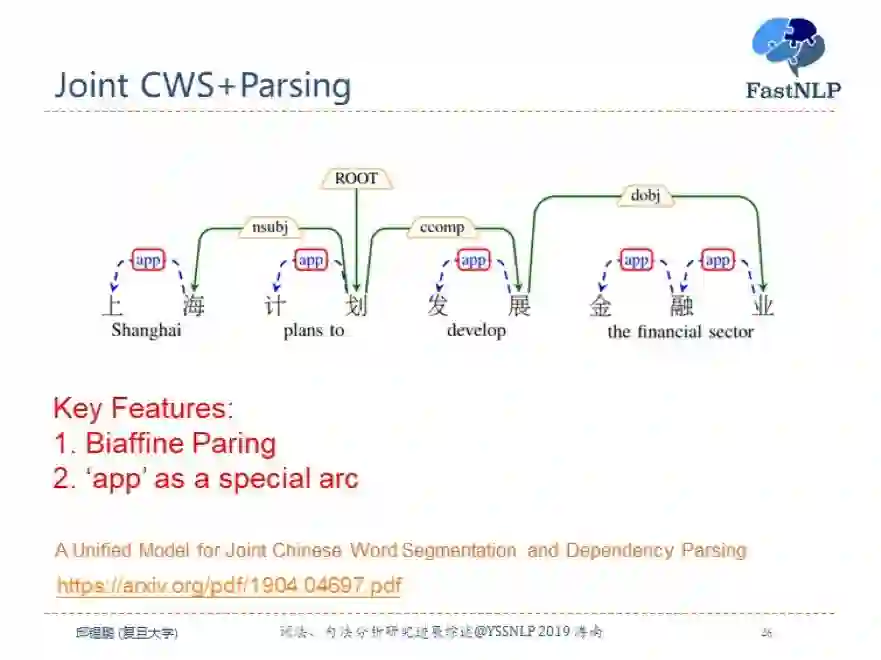
我们提出了一个基于图方法的统一模型来同时解决中文分词和句法分析问题。其实方法很简单,只需要将词内部的字之间加上一个特殊的依赖关系“app”,然后将词级别的依存关系转换为字级别的依存关系。并且用 biaffine 模型来进行同时预测。
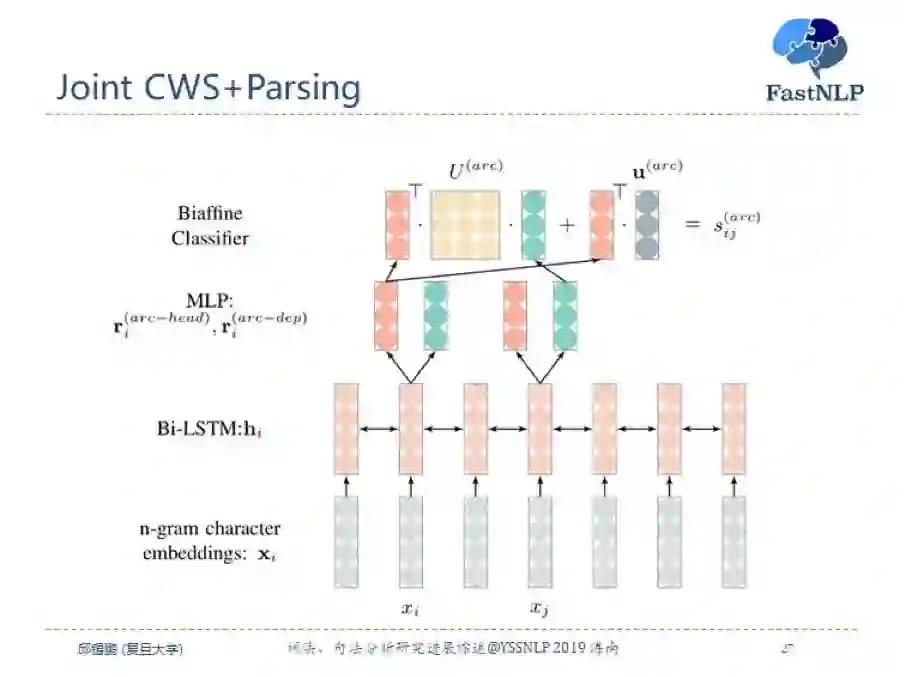
这就是具体的模型结构,和 biaffine 模型类似。
fastNLP

最后,上面的模型都将在 fastNLP 中进行实现,这里简单介绍下我们最近的一个工作,基于深度学习的自然语言处理平台 FastNLP。
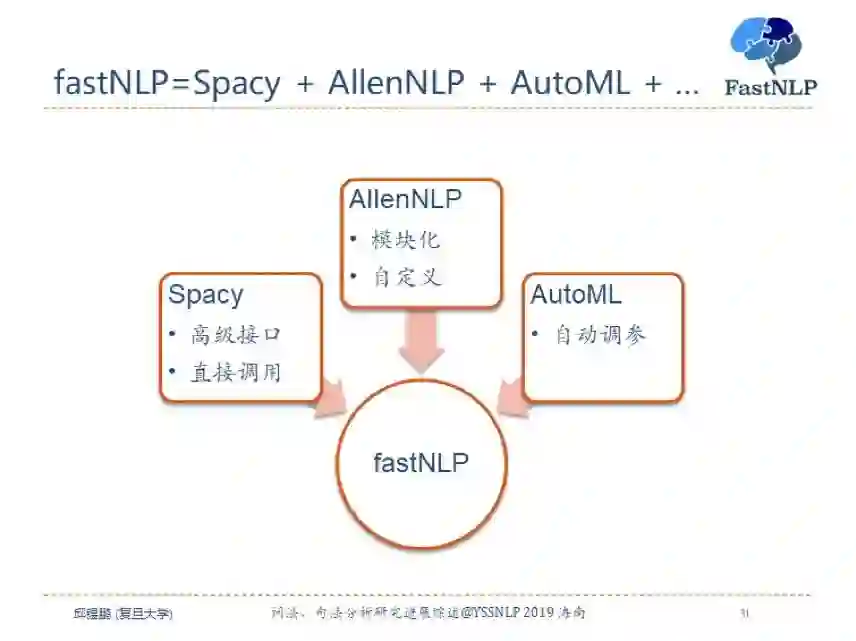
我们希望做到具有 Spacy 的易用性,AllenNLP 模块化以及 AutoML 自动模型选择。

FastNLP 是一个模块化可扩展的 NLP 框架,提供大量的预训练模型,可以使大家在五分钟内实现 SOTA 模型。另外 NLP 中大量的时间都花在数据的预处理和数据转换上面,FastNLP 提供了一种非常简单高效的数据预处理方法。面向我们科研工作者,FastNLP 也提供了非常方便的参数记录以及实验过程可视化工具。
最后希望有兴趣的老师、同学一起来参与开发,谢谢。

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐