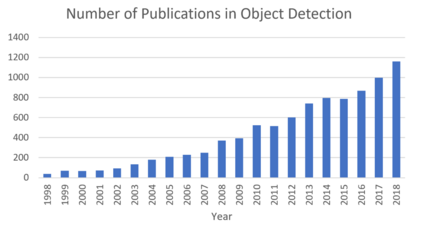
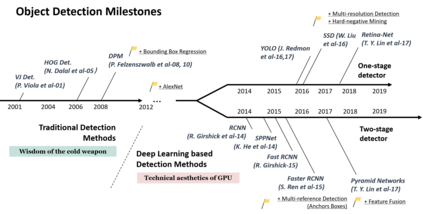
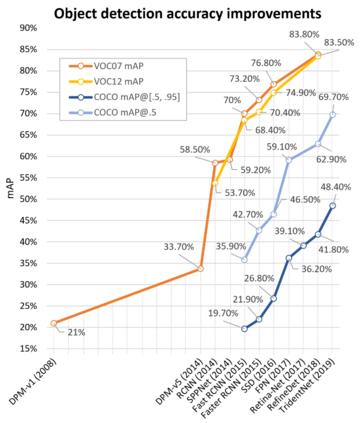
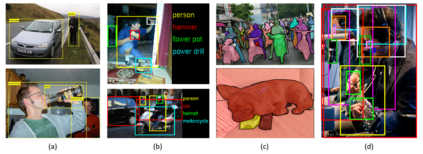
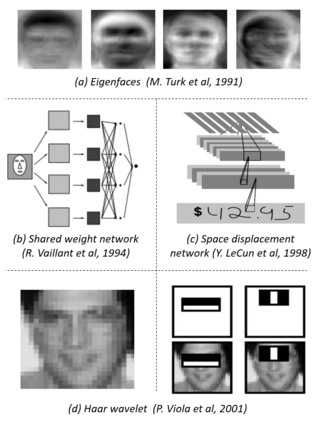
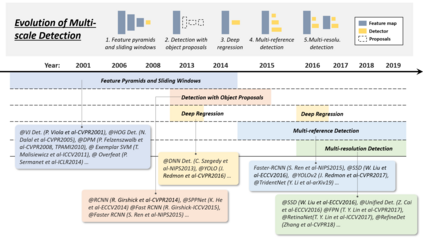
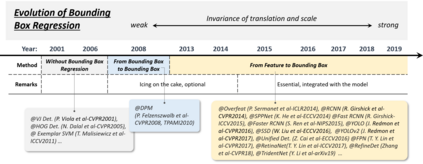
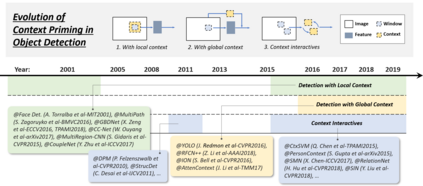
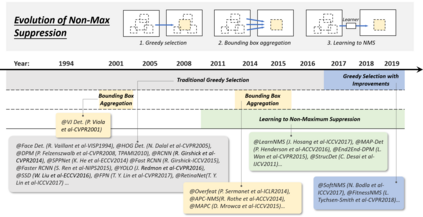
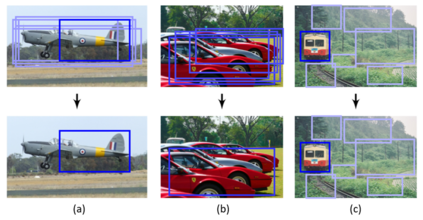
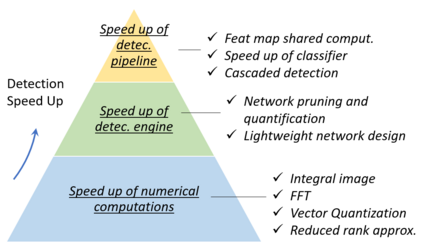
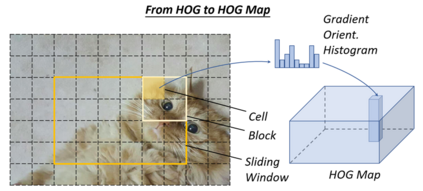
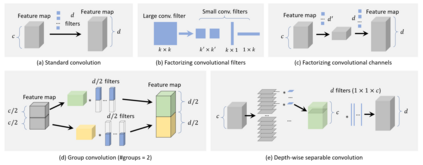
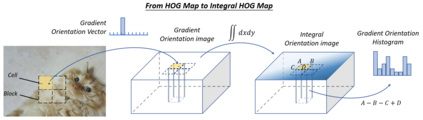
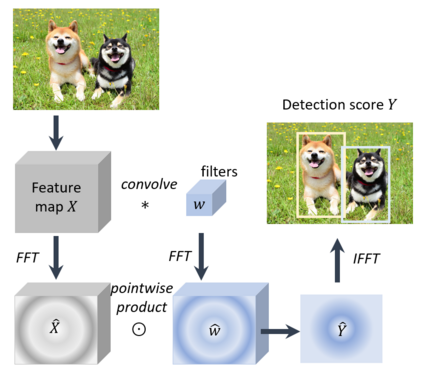
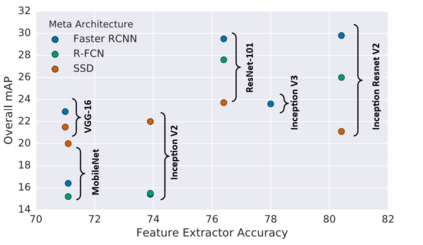
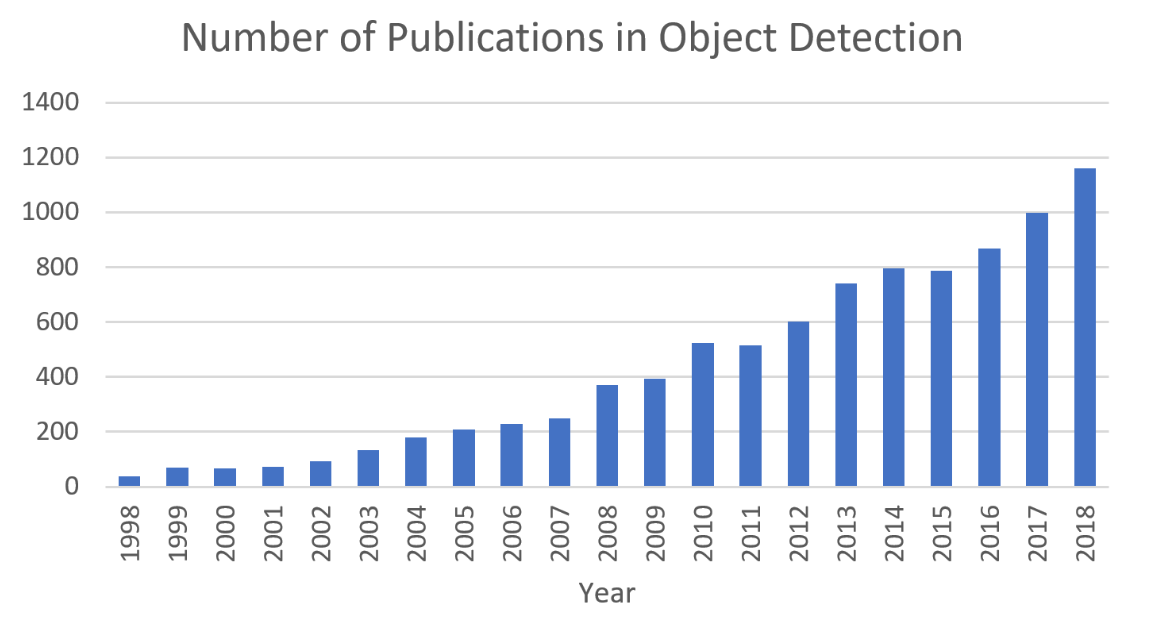
Object detection, as of one the most fundamental and challenging problems in computer vision, has received great attention in recent years. Its development in the past two decades can be regarded as an epitome of computer vision history. If we think of today's object detection as a technical aesthetics under the power of deep learning, then turning back the clock 20 years we would witness the wisdom of cold weapon era. This paper extensively reviews 400+ papers of object detection in the light of its technical evolution, spanning over a quarter-century's time (from the 1990s to 2019). A number of topics have been covered in this paper, including the milestone detectors in history, detection datasets, metrics, fundamental building blocks of the detection system, speed up techniques, and the recent state of the art detection methods. This paper also reviews some important detection applications, such as pedestrian detection, face detection, text detection, etc, and makes an in-deep analysis of their challenges as well as technical improvements in recent years.
翻译:近些年来,作为计算机视觉中最根本和最具挑战性的问题之一,物体探测近年来受到极大关注,其近二十年的发展可被视为计算机视觉史的缩影。如果我们把今天的物体探测视为深层学习能力之下的技术美学,然后将时钟倒转20年,我们将目睹冷战时代的智慧。本文根据其技术演变(从1990年代到2019年)对400+物体探测文件进行了广泛的审查。本文涉及了若干专题,包括历史中的里程碑探测器、探测数据集、测量标准、探测系统的基本构件、加速技术以及最新艺术探测方法。本文还回顾了一些重要的探测应用,如行人探测、面部探测、文本探测等,并深入分析了近年来的挑战和技术改进。