半监督学习入门基础(二):最基础的3个概念
作者:Neeraj varshney
编译:ronghuaiyang
来自:AI公园
今天给大家介绍半监督学习中的3个最基础的概念:一致性正则化,熵最小化和伪标签,并介绍了两个经典的半监督学习方法。
半监督学习 (SSL) 是一种非常有趣的方法,用来解决机器学习中缺少标签数据的问题。SSL利用未标记的数据和标记的数据集来学习任务。SSL的目标是得到比单独使用标记数据训练的监督学习模型更好的结果。这是关于半监督学习的系列文章的第2部分,详细介绍了一些基本的SSL技术。
一致性正则化,熵最小化,伪标签
SSL的流行方法是在训练期间往典型的监督学习中添加一个新的损失项。通常使用三个概念来实现半监督学习,即一致性正则化、熵最小化和伪标签。在进一步讨论之前,让我们先理解这些概念。
一致性正则化 强制数据点的实际扰动不应显著改变预测器的输出。简单地说,模型应该为输入及其实际扰动变量给出一致的输出。我们人类对于小的干扰是相当鲁棒的。例如,给图像添加小的噪声(例如改变一些像素值)对我们来说是察觉不到的。机器学习模型也应该对这种扰动具有鲁棒性。这通常通过最小化对原始输入的预测与对该输入的扰动版本的预测之间的差异来实现。
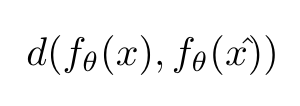
d(.,.) 可以是均方误差或KL散度或任何其他距离度量。
一致性正则化是利用未标记数据找到数据集所在的平滑流形的一种方法。这种方法的例子包括π模型、Temporal Ensembling,Mean Teacher,Virtual Adversarial Training等。
熵最小化 鼓励对未标记数据进行更有信心的预测,即预测应该具有低熵,而与ground truth无关(因为ground truth对于未标记数据是未知的)。让我们从数学上理解下这个。
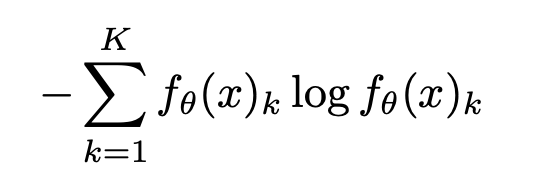
这里,K是类别的数量,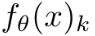
此外,输入示例中所有类的置信度之和应该为1。这意味着,当某个类的预测值接近1,而其他所有类的预测值接近0时,熵将最小化。因此,这个目标鼓励模型给出高可信度的预测。
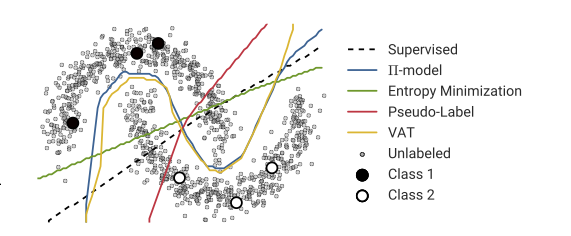
理想情况下,熵的最小化将阻止决策边界通过附近的数据点,否则它将被迫产生一个低可信的预测。请参阅下图以更好地理解此概念。
伪标签 是实现半监督学习最简单的方法。一个模型一开始在有标记的数据集上进行训练,然后用来对没有标记的数据进行预测。它从未标记的数据集中选择那些具有高置信度(高于预定义的阈值)的样本,并将其预测视为伪标签。然后将这个伪标签数据集添加到标记数据集,然后在扩展的标记数据集上再次训练模型。这些步骤可以执行多次。这和自训练很相关。
在现实中视觉和语言上扰动的例子
视觉:
翻转,旋转,裁剪,镜像等是图像常用的扰动。

语言
反向翻译是语言中最常见的扰动方式。在这里,输入被翻译成不同的语言,然后再翻译成相同的语言。这样就获得了具有相同语义属性的新输入。
半监督学习方法
π model:
这里的目标是一致性正则化。
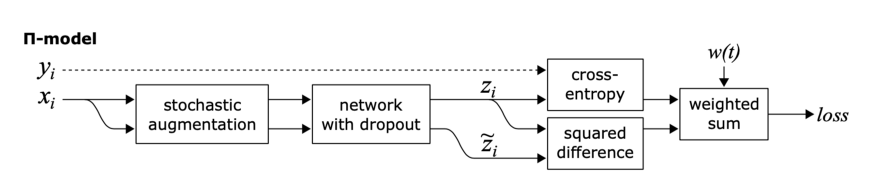
π模型鼓励模型对两个相同的输入(即同一个输入的两个扰动变量)输出之间的一致性。
π模型有几个缺点,首先,训练计算量大,因为每个epoch中单个输入需要送到网络中两次。第二,训练目标zĩ是有噪声的。
Temporal Ensembling:
这个方法的目标也是一致性正则化,但是实现方法有点不一样。
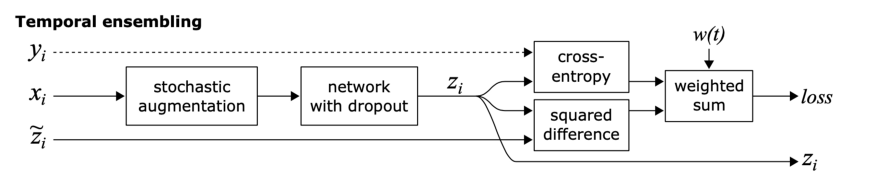
众所周知,与单一模型相比,模型集成通常能提供更好的预测。通过在训练期间使用单个模型在不同训练时期的输出来形成集成预测,这一思想得到了扩展。
简单来说,不是比较模型的相同输入的两个扰动的预测(如π模型),模型的预测与之前的epoch中模型对该输入的预测的加权平均进行比较。
这种方法克服了π模型的两个缺点。它在每个epoch中,单个输入只进入一次,而且训练目标zĩ 的噪声更小,因为会进行滑动平均。
这种方法的缺点是需要存储数据集中所有的zĩ 。

英文原文:https://medium.com/analytics-vidhya/a-primer-on-semi-supervised-learning-part-2-803f45edac2
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! ![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT ![]()
后台回复【南大模式识别】
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
推荐两个专辑给大家: 专辑 | 李宏毅人类语言处理2020笔记 专辑 | NLP论文解读 专辑 | 情感分析
整理不易,还望给个在看!











