论文浅尝 | 用增强学习进行推理:问答与知识库完善(KBC)
本文转载自公众号:程序媛的日常。
利用知识库、知识图谱来完善问答系统,有非常广阔的实际应用场景。当用户提出一个问题时,有时候仅用知识库中的某一个三元组事实(fact triple)即可回答。但当问题比较复杂时,而知识库中又经常是不完备的(incomplete),这时就需要结合多个事实、进行知识图谱上的推理,才能找到正确实体答案(entity)。举个例子来说,用户提出一个问题后,可以转换成如下的结构化查询:

进行这样一个查询并找到答案可能就需要访问知识图谱中的许多结点和边:

这样一个寻找答案的过程可以建模为一个序列化决策问题,也就自然可以用增强学习来解决。今天要分享的工作包括:
[1] Xiong et al., "DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning". EMNLP 2017.
[2] Das et al., "Go for a Walk and Arrive at the Answer: Reasoning Over Paths in Knowledge Bases using Reinforcement Learning". ICLR 2018.
[1] 提出的 DeepPath,是第一篇比较完整的用增强学习做知识库推理的工作,其将问题建模成一个马尔科夫决策过程 <S, A, P, R>。与以往工作不同的是,其状态空间 S 是连续的:[1] 利用 TransE 等模型预训练了整个知识图谱的表达,并将知识图谱两个实体之间的差表示为状态:
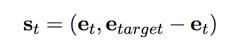
可以看到,这样建模就需要提前知道目标实体(也就是实体答案)。[1] 中的动作空间 A 就自然而然地定义为知识图谱中的所有关系。最后,奖励 R 的定义上他们采用了三种奖励函数:
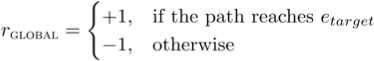

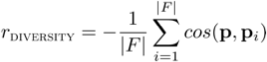
这三种函数主要是为了让训练过程更加高效,让学习到的策略更快捷。有了这样的建模后,整个问题的解决过程就如下图所示:
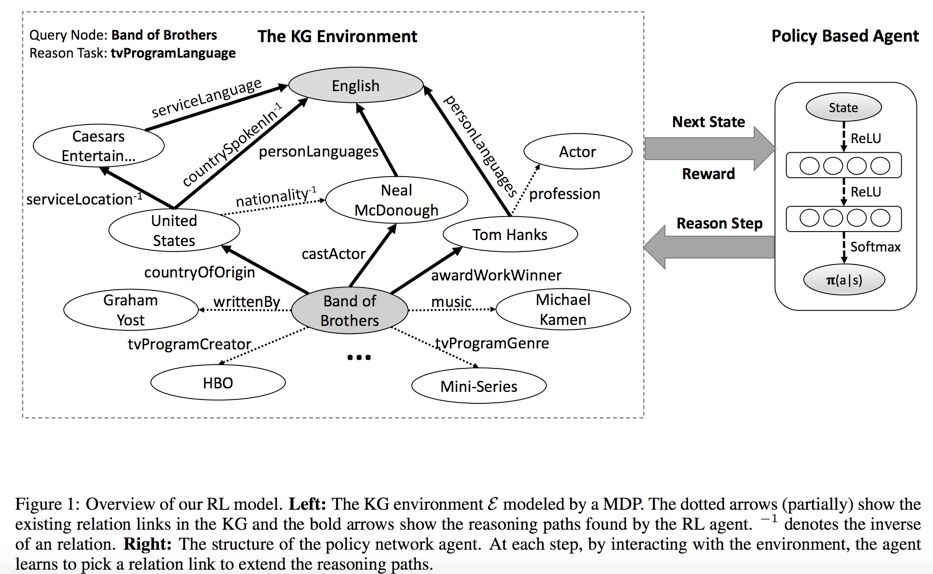
虽然这个过程比较直观,但是用增强学习做知识图谱推理存在着一个很大的难点就是其动作空间比较大。在我们比较熟悉的其它使用增强学习的任务中, 比如 Atari games (Mnih et al., 2015),一般只有 4~18 valid actions;而前两年名声大噪的 AlphaGo (Silver et al. 2016),也“只有” 250 valid actions。但对于常见的知识图谱推理来说,有 >= 400 actions。[1] 给出的解决办法除了刚才特殊设计的奖励函数,还有像 AlphaGo 一样先用有监督学习进行预训练,这里的细节请参阅原论文。
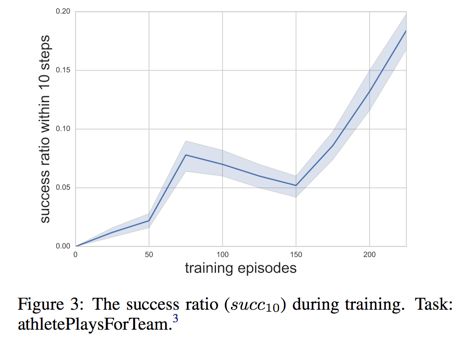
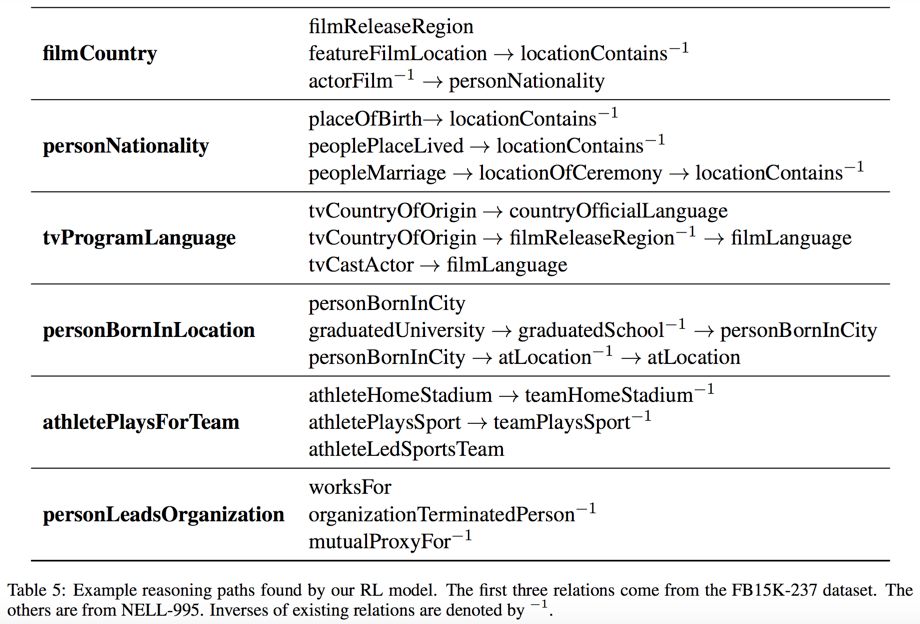
可以看到这篇工作的效果还是不错的,这是一些学到的推理路径(horn-clauses):
刚才提到,[1] 的工作中使用的建模方法必须要求提前知道推理的目标实体,也就是实体答案,并用这个目标实体去指导寻找推理路径的过程。这个“局限性”不仅存在于 [1] 这个基于增强学习做知识推理的工作中,也存在于过去几个非增强学习的基于路径(path-based)的工作里(如 Neelakantan et al., 2015; Toutanova et al., 2016)。而同样是基于增强学习,[2] 中提出的 MINERVA 模型就避免了这样的建模要求。换句话说,DeepPath [1] 做的是事实判断(fact prediction),也就是去判断某个三元组是否是正确的;而 MINERVA [2] 是做问答(query answering),是在知识图谱中的全部实体中找正确答案。尽管前者的算法可以应用到后者,但是这就需要去把所有可能的实体组合到三元组中,遍历一遍,很耗计算;而后者则希望尽量避免遍历,直接找出最合适的答案。直观上来讲,后者的问题就更难一些。
MINERVA [2] 的建模方法也就自然和 DeepPath [1] 不太一样。其“理想的”状态空间 S 包含了当前“走”到的实体结点 e_t,还有已知查询中的 e_{1q} 和 r_q,以及答案 e_{2q}。可是如前所说,[2] 中不需要提前知道答案结点。所以 [2] 将整个过程建模为一个 partially observed MDP(POMDP)。MINERVA [2] 的动作空间也做了精简,其每一时刻的可能动作是当前 e_t 的外出边(outgoing edge)。这点带来的效率上的优势在后续的实验中得到了印证。
为了解决这样一个 POMDP 过程,[2] 将观测序列和历史决策序列用 LSTM 建模表示,并让策略网络的学习基于这样的历史信息:


可以看到,MINERVA [2] 的方法还是比较简单的,不需要提前知道答案,不需要任何预训练,奖励函数不需要特殊设计,仅仅是用 LSTM 来做历史状态的表达。其优点也比较明显,这个工作对路径没有太多的限制,也没有对路径长度的限制,实验结果也表示其在路径比较长的情况下依然表现得很好。

从主要实验结果上来看,首先,MINERVA [2] 因为不断地利用了问题中的关系(query relation)和过去的历史状态信息,使得其的表现远远超过了非增强学习的基于随机游走的模型:

而其和 DeepPath [1] 也进行了比照:
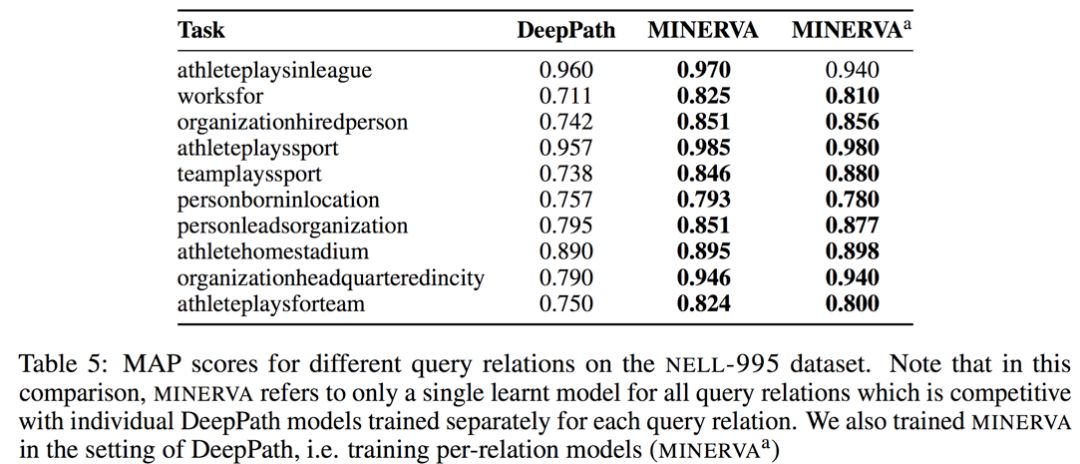
尽管 MINERVA [2] 有很多优点,其也存在一个比较明显的弊端:MINERVA [2] 假设了一定存在一个推理路径,当推理路径不存在(问题不对)时,并不能做出特殊处理。
其实在这个知识图谱推理上还有很多工作,未来有时间会继续跟大家分享。

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。