DeepMind:用PopArt进行多任务深度强化学习
多任务学习——即允许单个智能体学习如何完成多种不同的的任务——一直是人工智能研究的长期目标。近年来,这一领域出现了不少优秀进展,比如DQN只用同一种算法就能玩包含《打砖块》和《乓》在内的多种游戏。但事实上,这些算法的本质还是对于每个任务,训练单独的智能体。

随着人工智能研究开始向更复杂的现实任务靠拢,构建一个“多才多艺”的智能体——而不是多个“专家级”智能体——对学习执行多个任务将是至关重要的。很可惜,到目前为止,这已经被证明仍是一项重大挑战。
其中的一个原因是在不同任务中,强化学习智能体用来判断自己成功与否的奖励标准存在差异,这导致它们会陷入“唯奖励论”,专注于执行所有奖励更高的任务。举个例子,在雅达利游戏《乓》中,智能体每执行一个“动作”就可能获得如下奖励:-1、0或+1。相比之下,如果是同为街机游戏的《吃豆人小姐》,智能体可能走一步就能获得成百上千个积分。
即便我们把单个奖励设置成基本一致,随着智能体被训练地越来越好,由于奖励频率不同的存在,不同游戏间的奖励差异还是会变得越来越明显。
为了解决这些问题,DeepMind开发了PopArt,它可以调整每个游戏中的积分等级,因此无论不同游戏间的奖励差异有多大,智能体都会对它们“一视同仁”,判断它们带给自己的奖励相同。在他们最新的论文Multi-task Deep Reinforcement Learning with PopArt中,DeepMind把PopArt归一化用在当前最先进的强化学习智能体上,训练了一个只用一套权重的单一智能体。在一整套57种不同的Atari游戏上,这个智能体的表现可以达到人类中等水平以上。

从广义上讲,深度学习极度依赖神经网络权重的更新,使输出更接近需要的目标输出。这一点放在深度强化学习上也一样。
PopArt的工作机制基于估计这些目标的平均值和分布(例如游戏中的得分),在利用这些统计信息更新网络权重前,它会先对它们做归一化,目的是形成对奖励的规模和频率更稳健的学习经验。之后,为了获得更准确的估计——如预期的得分——它再继续把网络的输出重新转成原始范围。
如果单纯地这么做,那么每次更新统计数据都会改变非归一化的输出,包括非常理想的输出。这不是我们想要的。为了避免这一点,DeepMind提出的解决方案是,每次更新统计数据时,网络就会进行一次反向更新,这意味着我们既能实现网络的大规模更新,又能保持先前学习的输出不变。
出于这种原因,他们把这种方法命名为PopArt:Preserving Outputs Precisely while Adaptively Rescaling Targets(在自适应重新缩放目标的同时精确保留原有输出)。
用PopArt代替奖励剪枝
按照以往的做法,如果研究人员要用强化学习算法对奖励进行剪枝,以此克服奖励范围各不相同的问题,他们首先会把大的奖励设为+1,小的奖励为-1,然后对预期奖励做归一化处理。虽然这种做法易于学习,但它也改变了智能体的目标。
例如,《吃豆人小姐》的目标是吃豆子,每个豆子10分,吃鬼200-1600分。在训练强化学习智能体时,通过剪枝,智能体会认为自己吃豆子或吃鬼没有任何区别,再加上吃豆子更容易,研究人员会很容易训练出一个只会吃豆子、从不追逐鬼的智能体。
而如下面这个视频所示,用PopArt取代奖励剪枝后,这个智能体更“聪明”了,它会把追鬼纳入自己的吃豆路径,得分也更高:
用PopArt进行多任务深度强化学习
今年2月,DeepMind曾发布一个多任务集合DMLab-30,为了解决其中的问题,他们还开发了一个高度可扩展的、基于分布式架构的智能体IMPALA。这是目前世界上最先进的强化学习智能体之一,也是DeepMind最常用的深度强化学习智能体之一。
在实验中,他们把PopArt用于IMPALA,并和基线智能体做对比。结果如下图所示,PopArt大幅提高了智能体的性能。实验还对比了奖励剪枝和未剪枝的情况,可以发现,使用PopArt的智能体在游戏中的得分中位数高于人类玩家的中位数,这比基线表现好很多。而其中未剪枝的基线得分几乎为0,因为它无法从游戏中学习有意义的表征,所以也无法处理游戏奖励范围的巨大变化。
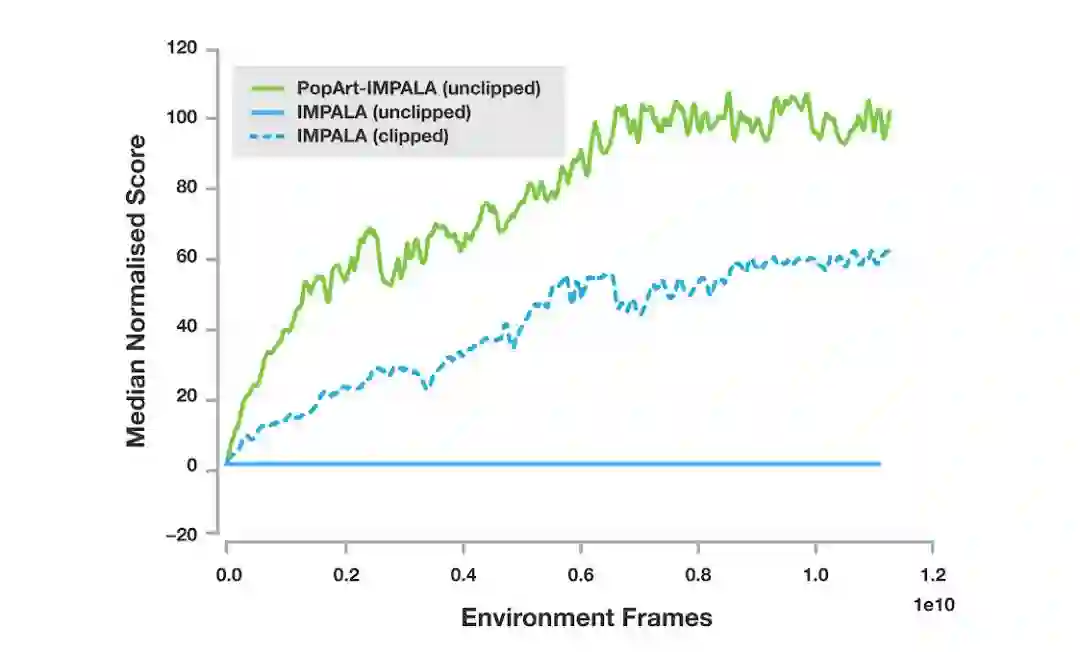
57个Atari上的表现中位数,每一行对应单个智能体的中值性能;实现为经过剪枝,虚线未剪枝
这也是DeepMind第一次在多任务环境中看到智能体有超人表现,这表明PopArt确实在奖励不平衡上有一定的协调作用。而当未来我们把AI系统用于更复杂的多模态环境时,像这种自适应规范化方法会变得越来越重要,因为智能体必须要学会在面对多个不同目标时,利用它们各自的奖励做总体权衡。
论文地址:arxiv.org/abs/1809.04474




