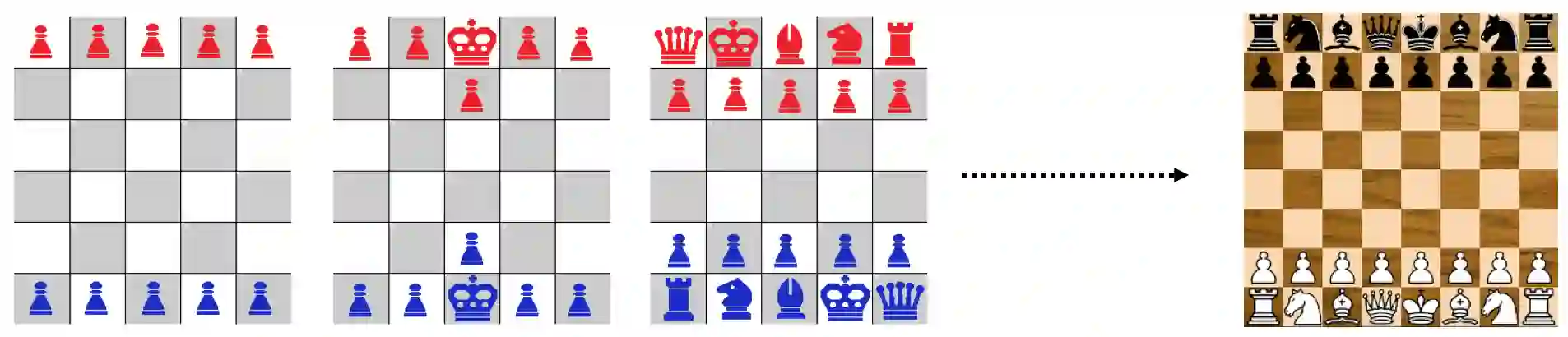
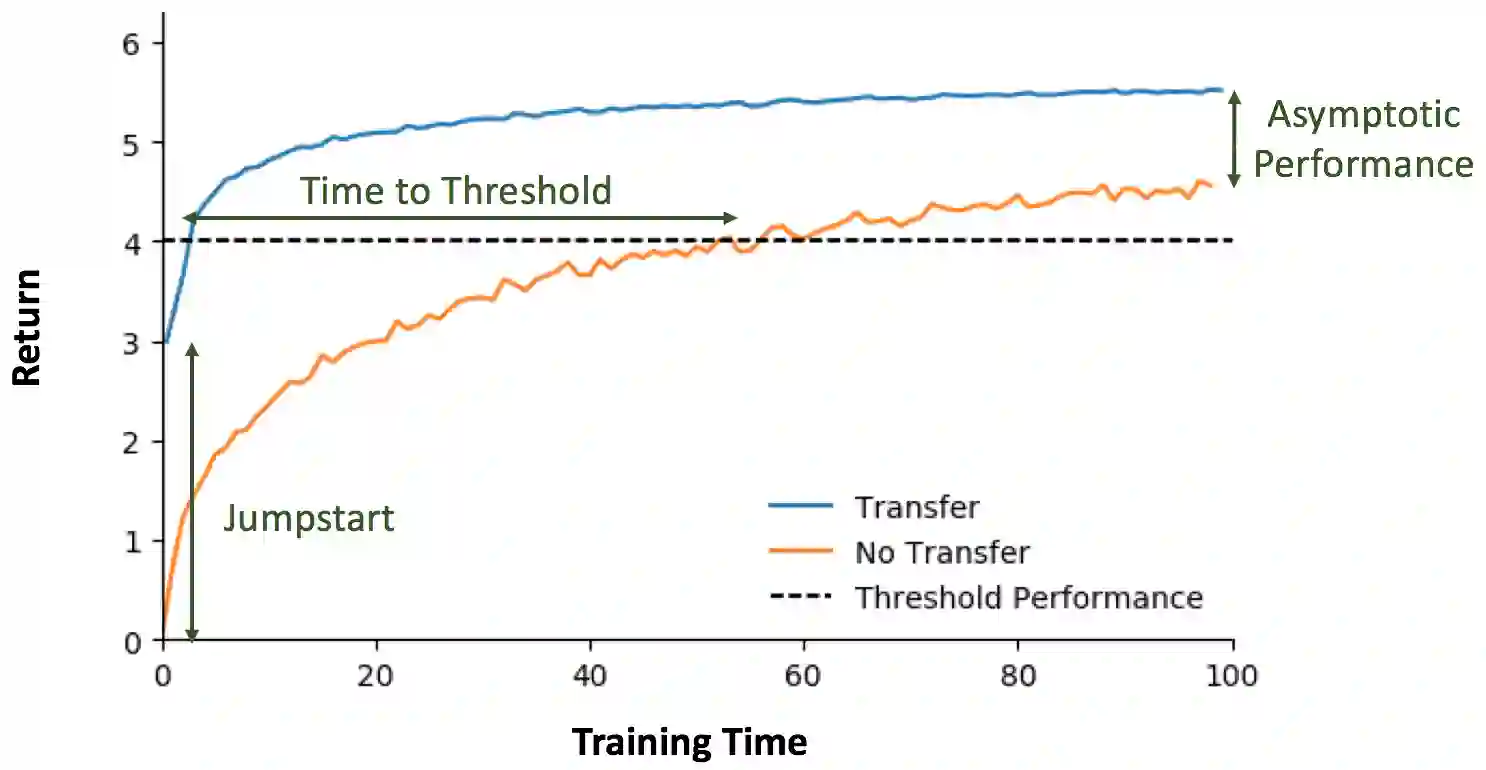
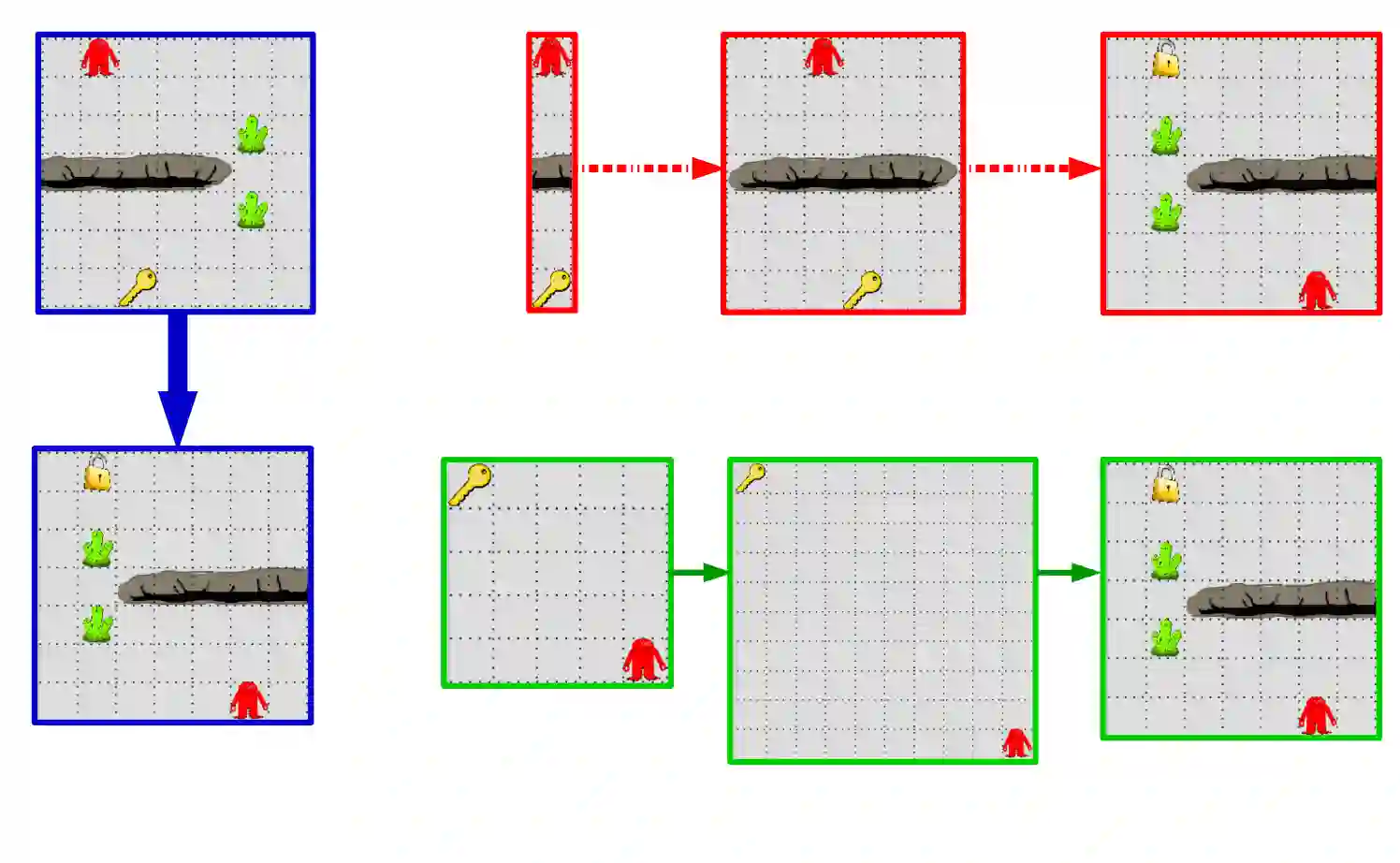
Reinforcement learning (RL) is a popular paradigm for addressing sequential decision tasks in which the agent has only limited environmental feedback. Despite many advances over the past three decades, learning in many domains still requires a large amount of interaction with the environment, which can be prohibitively expensive in realistic scenarios. To address this problem, transfer learning has been applied to reinforcement learning such that experience gained in one task can be leveraged when starting to learn the next, harder task. More recently, several lines of research have explored how tasks, or data samples themselves, can be sequenced into a curriculum for the purpose of learning a problem that may otherwise be too difficult to learn from scratch. In this article, we present a framework for curriculum learning (CL) in reinforcement learning, and use it to survey and classify existing CL methods in terms of their assumptions, capabilities, and goals. Finally, we use our framework to find open problems and suggest directions for future RL curriculum learning research.
翻译:强化学习(RL)是处理连续决策任务的流行范例,代理机构只有有限的环境反馈。尽管在过去三十年中取得了许多进展,但在许多领域的学习仍需要与环境进行大量互动,在现实的情景下,这种互动费用可能高得令人望而却步。为解决这一问题,转移学习被用于加强学习,这样,在开始学习下一个更艰巨的任务时,可以利用一项任务获得的经验。最近,一些研究线探讨了如何将任务或数据样本本身排列成课程,以便学习一个否则可能难以从零学的问题。在本条中,我们提出了一个课程学习框架,用于加强学习,并用它从假设、能力和目标的角度对现有的学习分类方法进行调查和分类。最后,我们利用我们的框架来找出公开的问题,并为未来的学习学习课程提出方向。