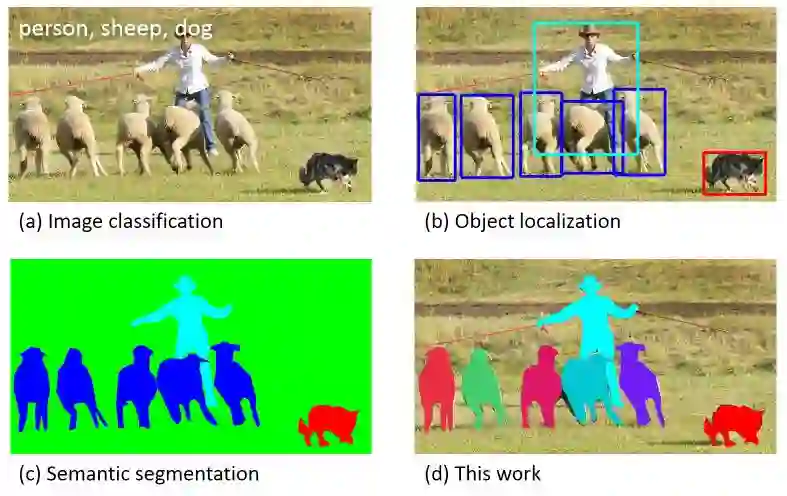
Generic object detection, aiming at locating object instances from a large number of predefined categories in natural images, is one of the most fundamental and challenging problems in computer vision. Deep learning techniques have emerged in recent years as powerful methods for learning feature representations directly from data, and have led to remarkable breakthroughs in the field of generic object detection. Given this time of rapid evolution, the goal of this paper is to provide a comprehensive survey of the recent achievements in this field brought by deep learning techniques. More than 250 key contributions are included in this survey, covering many aspects of generic object detection research: leading detection frameworks and fundamental subproblems including object feature representation, object proposal generation, context information modeling and training strategies; evaluation issues, specifically benchmark datasets, evaluation metrics, and state of the art performance. We finish by identifying promising directions for future research.
翻译:近些年来,深思熟虑技术已成为直接从数据中学习特征表现的有力方法,并导致在一般物体探测领域取得显著突破。鉴于这一迅速演变的时期,本文件的目标是全面调查深思熟虑技术在这一领域带来的近期成就。本调查包括250多项关键贡献,涉及通用物体探测研究的许多方面:主要探测框架和基本次问题,包括物体特征说明、目标建议生成、背景信息建模和培训战略;评价问题,特别是基准数据集、评价指标和最新业绩。我们最后为今后研究确定有希望的方向。