在强化学习(
RL)智能体模拟训练中,环境高速并行执行引擎至关重要。最近,新加坡 Sea AI Lab 颜水成团队提出一个全新的环境模拟并行部件 EnvPool,该部件在不同的硬件评测上都达到了优异的性能。
我们知道,强化学习(RL)的模型训练部分通常在 GPU 上进行,区别于监督学习,RL 所需的数据是实时和环境交互得到的。由于环境部分通常只有 CPU 实现,模型训练的瓶颈在于数据的生产速度远小于 GPU 能够消费数据的速度。为了能够提高训练的通量,环境的执行通常会在 CPU 集群上并行,主要有以下两种方案:
随着 Agent 网络变得复杂,在 CPU 上 inference 的第一个方案的运行代价远高于把多个环境输出组成一个 batch 然后依赖 GPU/TPU 的高度并行计算特性来进行 batched inference 的第二个方案。因此,近年的训练系统已经逐渐收敛到以第二个模式为基本共识。
由于近年来 AI 芯片的高速发展,在 RL 场景下要消耗掉加速器(GPU/TPU 等)的算力,就需要大量的 CPU 来进行环境模拟。GPU 在监督学习,即数据供应非常快的情景下迭代模型,已经有非常成熟的方案。相比之下,RL 的数据生产,即环境模拟,则一直处于关注度很少的状态。环境的模拟速度是整个 RL 训练系统的上限,因为它是整个流水线的上游,决定了接下来了 Inference 阶段跟 Learning 阶段的整体效率。
![]()
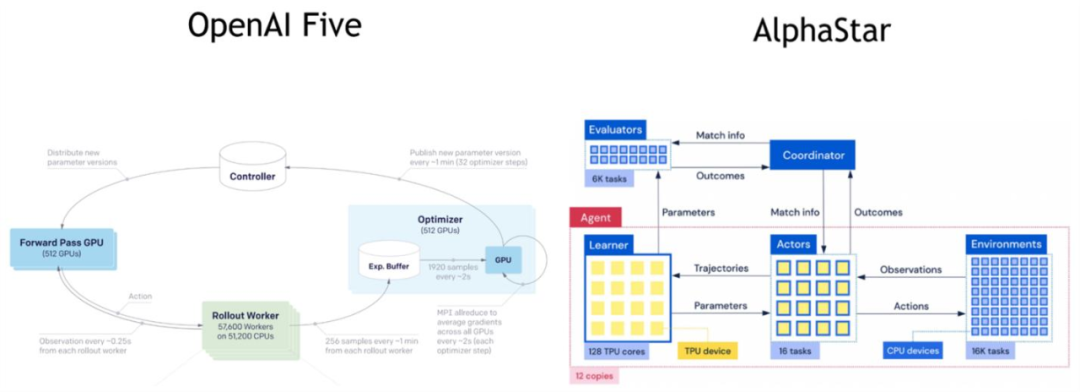
OpenAI Five(左)和 DeepMind AlphaStar 的 RL 系统。
在最近的一项研究中,新加坡 Sea AI Lab 负责人颜水成(Shuicheng Yan)团队意识到环境高速并行执行引擎的极其重要性,并观察到目前最流行的环境并行执行的方案,即 gym.vector_env 使用 Python 的多进程模式同时执行多个环境来进行加速,实际使用的效率是非常低的。尽管 gym.vector_env 能保持一样的 Gym API 下,实现同时执行多个环境的加速效果,但由于 Python 的局限性,同一进程内由于全局锁无法有效并行,多进程并行则会增加进程间数据传送和的打包的开销,因此并行度有限。并且,RL 环境特别是 Atari 环境,常有层层的 Python wrappers,更加增加了环境模拟的额外开销。
基于此,
Sea AI Lab团队提出一个全新的环境模拟并行执行部件 EnvPool,使用 C++ 的线程池来异步执行 RL 环境,把 Python wrappers 整合到高速的 C++ 实现中
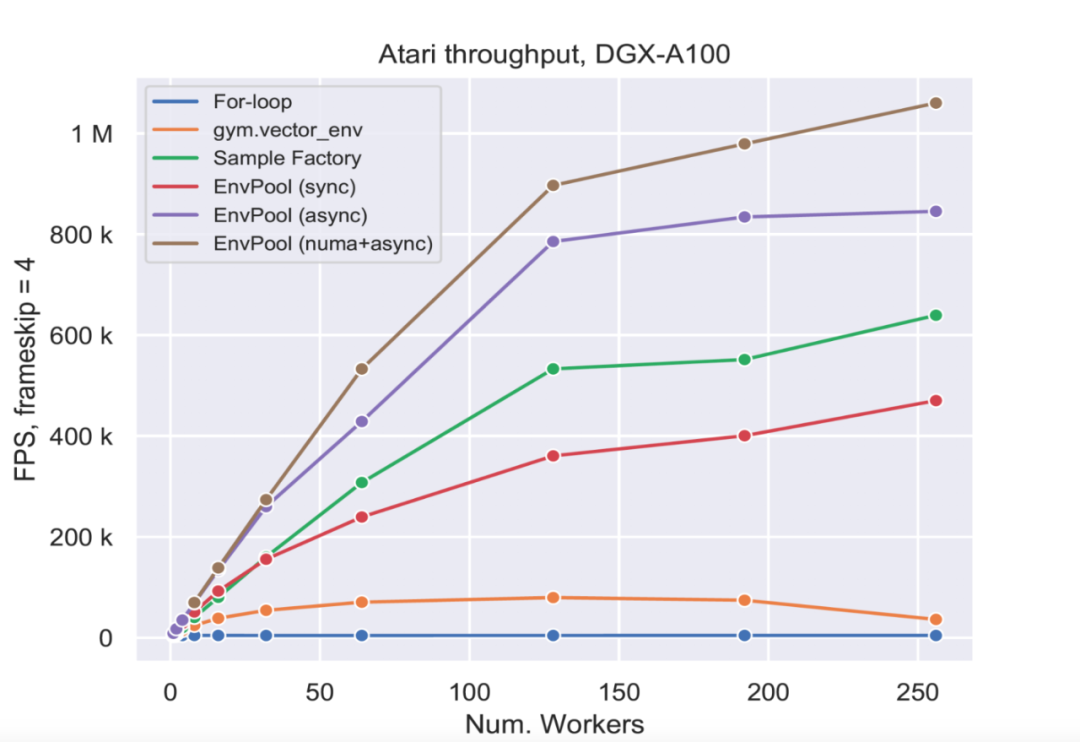
。加之一系列对 RL 环境定制的优化,包括 ActionBufferQueue, StateBufferQueue 等,EnvPool 在不同的硬件评测上都达到了优异的性能,比如在 NVIDIA DGX A100 的 256 核 CPU 上,达到了一百万帧每秒的速度,是 gym.vector_env 的 13倍;在普通个人电脑上比如 12 核 CPU 的配置,通量也能达到 gym.vector_env 的约 3 倍。换个角度,也就是使用了 EnvPool 的并行加速之后,能大大节省所需要的 CPU 计算资源。EnvPool 已经在 GitHub 上开源。
![]()
EnvPool 支持的 RL 环境包括 Atari、VizDoom 和 Classic RL envs:
![]()
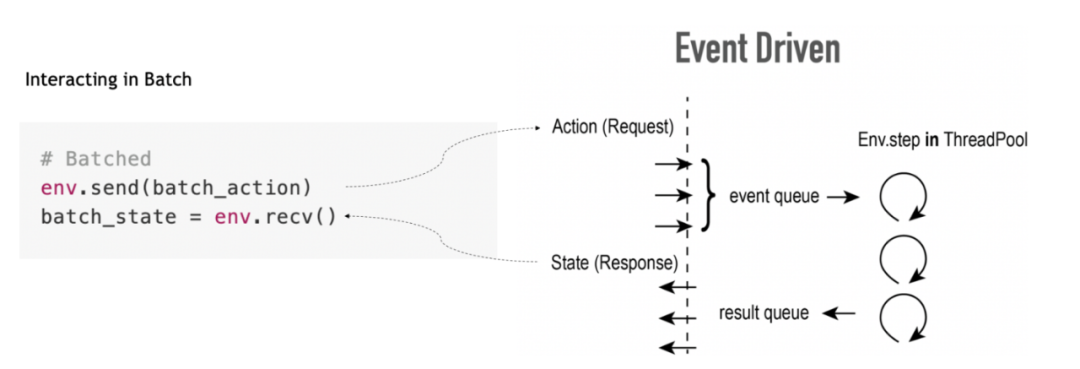
使用 C++ 定制实现的 EnvPool 对研究人员非常友好,在用户端的 Python 接口与 Gym API 接口保持一致,唯一的区别就是每一步的操作都是对一个 batch 的环境一起操作
。如下图所示,EnvPool 并行地跑 100 个环境,每一步 env.step 也是发送 100 个 action 对 100 个环境一起操作。在这样的 API 下,算法端的用户能很容易地利用 GPU/TPU 直接进行 batched inference,而不需要在算法端再做 batching 的操作。
![]()
在更快的异步执行 API,env.step() 函数被拆分成两步
,分别是 env.recv() 负责接收异步执行的环境里已经执行完成的 batch_size 个环境的输出,而 agent 执行完后得到的一个 batch 的 action 则通过 env.send() 函数送回 EnvPool 对应的 env_id 中。
![]()
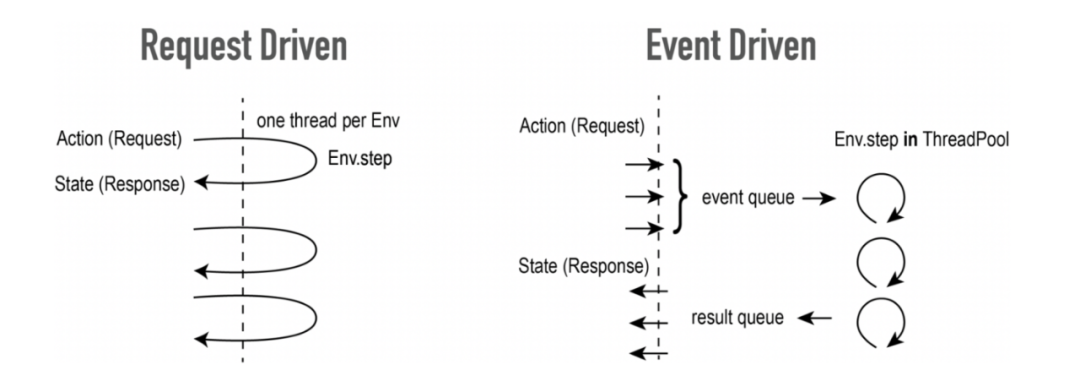
RL 环境可以类比于 web 服务。Web 服务接收用户的请求,在处理之后返回结果。而 RL 环境接收用户的 action,在处理之后返回 state。在 web 开发中,两种模式经常被提及,即事件驱动和请求驱动。
请求驱动如下图左,服务器在收到请求之后用同一个线程接收、处理并返回给用户。图右的事件驱动则使用一个或几个线程先将所有的请求接收进事件队列,并使用固定数量的线程从事件队列中取出请求进行处理,完成处理之后将结果放入返回队列返回给用户。
总的来说,事件驱动往往比请求驱动更加高效,因为前者在收到大量请求的时候会启动大量线程来处理,线程间的上下文切换成为系统的负担。而后者根据 CPU 核心数量预设了线程池的大小,因此避免了上下文切换。请求驱动往往被称为同步模式,因为从请求到返回由同一个线程顺序执行。而事件驱动常被称为异步模式,因为每一步都是在不同的线程进行。
EnvPool 的整体设计便是遵循事件驱动的原则,因此引入异步的 API
。
![]()
在常用的环境实现中,最重要的 API 是 step 函数,调用 step 是个同步的过程,输入一个 action,等待执行完毕,然后返回一个 state。整个过程是同一个线程完成。
EnvPool 将 step 函数拆开成 send 和 recv 两个函数来进行异步的收发
。send 函数负责将 action 放入事件队列,不等待结果便直接返回。线程池取 action 之后 step 相应的环境,结束后将 state 放入返回队列。recv 函数则从返回队列中取结果。send 和 recv 甚至可以在不同的线程中执行。
同时,因为 GPU/TPU 一次能够处理一整个 batch 的 state,所以 EnvPool 将 API 扩展成支持批量交互。send 一次将一批对应不同环境的 action 放入事件队列,recv 一次从返回队列中取出一整个 batch 的 state。
![]()
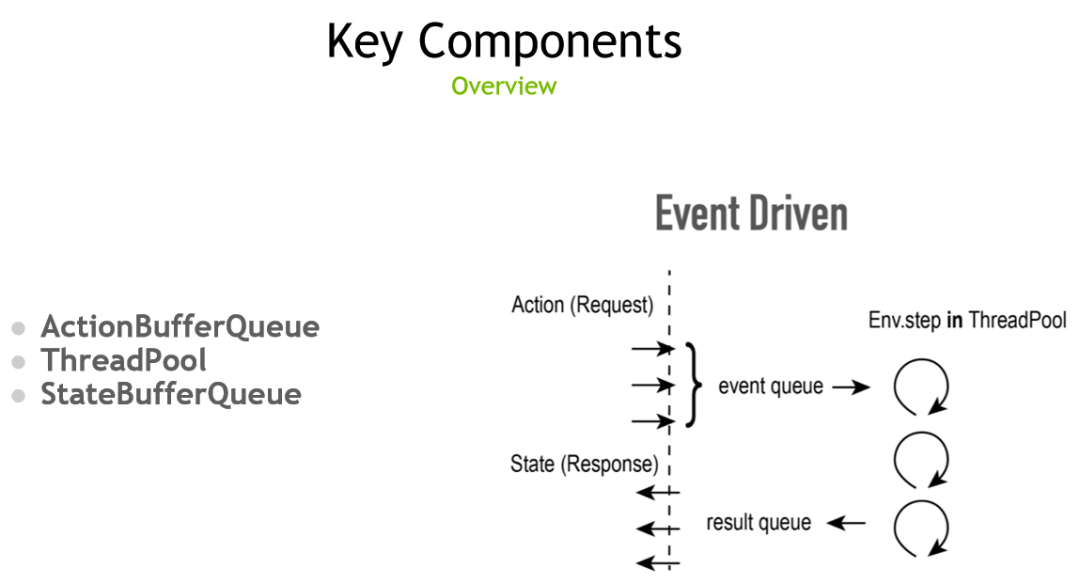
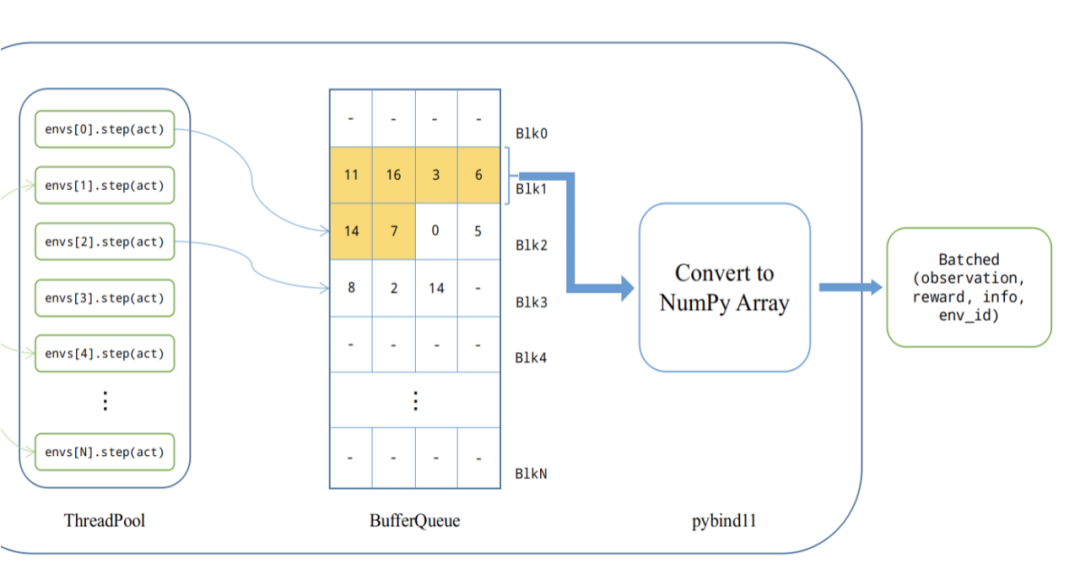
为了优化整体的性能,Sea AI Lab 团队精心设计并优化 Action 输入的事件队列、线程池以及返回 state 的返回队列,分别称为
ActionBufferQueue、ThreadPool 和 StateBufferQueue
。
![]()
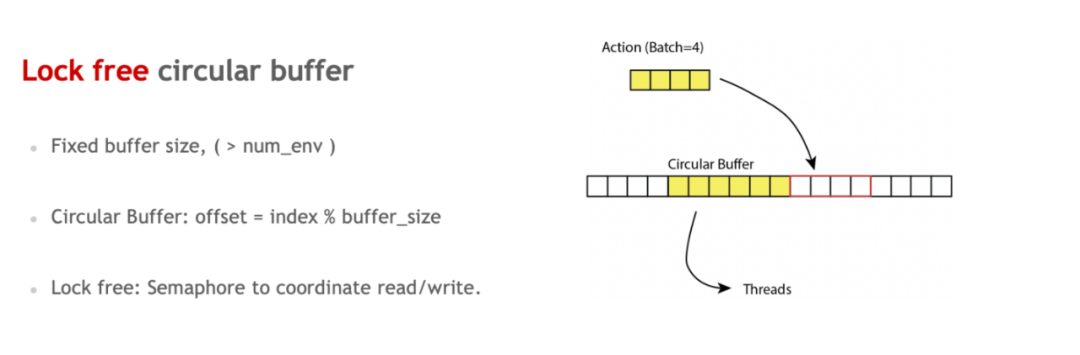
由于 EnvPool 假定同时并行的环境的总数是提前定好的,同时交互的 batch 大小也是提前预定的,因此在这个场景下可以使用比通用队列更定制化且更高效的队列的实现。ActionBufferQueue 是用于存储 Action 的队列,使用固定大小的循环内存,并用 semaphore 和原子操作来实现无锁的多线程读写。
![]()
在输出端,因为下游 GPU 在消费 State 的时候倾向于一次计算一整个 batch,所以 StateBufferQueue 里存放着预先分配好的整块内存。线程池中的环境在执行完计算之后直接写入预分配好的内存中。预分配好的内存在写满之后将 ownership 直接转移给 python。因此在这个过程中,除了正常的环境输出 State 之外,没有任何额外的内存拷贝。
![]()
EnvPool 中所使用的队列和线程池都是通用的组件,和具体的环境无关
。EnvPool 提供面向开发者的接口,对于新的环境,只需按照 env.h 中定义的接口进行封装便可直接使用 EnvPool 的高效异步实现来进行环境的并行执行以及批量交互。
EnvPool 的核心实现都是基于 C++ 模板或者完全定义在 C++ 头文件里。因此,在接入一个新的环境的时候,代码可以独立编译,无需额外动态链接。由于核心代码基于 C++ 模板,EnvPool 可以自动将 C++ 的环境封装并通过 pybind 暴露给 python。大多数场景下,开发者只需要按核心接口实现好 C++ 环境即可,无需写任何额外代码便可直接接入 python。
示例代码:https://github.com/sail-sg/envpool/blob/master/envpool/core/dummy_async_envpool.h
Sea AI Lab 团队在不同的硬件机器上对比了 EnvPool 与经典的环境并行执行引擎,比如前文提到的 gym.vector_env,及发表于 2020 年据团队所知是目前最快的 RL 环境执行引擎 Sample Factory。以下为实验设置:
![]()
使用不同的 worker 数目,该团队画出了详细的对比图。由下图可见,在不同的线程数(或者 CPU 核数)下,EnvPool 始终保持了数倍的优势。
![]()
Sea AI Lab (SAIL)成立于 2020 年末,由 AI 大牛颜水成挂帅,专注于前沿突破性基础研究。
![]()
从左至右依次为 Sea AI Lab 的 Jiayi Weng、Min Lin、Zhongwen Xu 和 Shuicheng Yan。
Sea AI Lab 团队将继续改进和完善 RL 环境并行核心执行引擎,加入更多的 RL 经典环境,包括 Mujoco 等,同时也将开源一些实例来展示如何把一些现有的 RL 训练框架,如 Tianshou(出自同一位一作)及 DeepMind Acme,接入 EnvPool 使得 RL 训练速度大大提升。同时团队也十分欢迎开源社区的讨论与贡献。EnvPool 的愿景是为 RL 提供强劲的数据管线,让 RL 和监督学习一样容易扩展。
线上分享
11
月17日,机器之心最新一期分享邀请到
翁家翌(
卡内基梅陇大学
计算机学院硕士二年级在读
)带来分享
,详解EnvPool:
分享主题:EnvPool – 高性能环境并行模拟器
嘉宾简介:
翁家翌,卡内基梅陇大学(CMU)计算机学院硕士二年级在读。目前的研究兴趣主要是对机器学习与强化学习系统(MLSys)进行加速。在加入 CMU 之前,翁家翌在清华大学计算机科学与技术系取得了本科学位。翁家翌还是目前广受欢迎的基于 PyTorch 的强化学习算法库天授(tianshou)的作者,从开源至今已经有近四千的 GitHub star。
分享时间:
北京时间11月17日20:00-21:00
交流群:
本次直播设有 QA 环节,欢迎加入本次直播交流群探讨交流。
如群已超出人数限制,请添加机器之心小助手:syncedai2、syncedai3、syncedai4 或 syncedai5,备注「强化学习」即可加入。
机动组是机器之心发起的人工智能技术社区,聚焦于学术研究与技术实践主题内容,为社区用户带来技术线上公开课、学术分享、技术实践、走近顶尖实验室等系列内容。机动组也将不定期举办线下学术交流会与组织人才服务、产业技术对接等活动,欢迎所有 AI 领域技术从业者加入。
点击阅读原文,访问机动组官网,观看往期回顾:
关注机动组服务号,获取每周直播预告。