周涛:如何高效地进入大数据领域?
点击上方蓝色字体“数据科学和人工智能”,关注公众号,后台回复"高效进入大数据领域"就可以获取《周涛:如何高效进入大数据领域?》下载链接,更多资料下载地址在文末。
大数据正颠覆着商业、产业模式,改写着城市、乃至地球的未来。想要利用大数据,除了编程、统计学等基本功外,还需要依靠新思维,人类必须颠覆千百年来的思维惯例,这将对人类的认知和与世界交流的方式提出全新的挑战。
前几日,电子科技大学大数据研究中心主任、DataCastle数据城堡创始人周涛老师,携手知乎·读书会,带来知乎Live:如何高效地进入大数据领域。周涛老师深度剖析三个大数据创新实践的典型案例,分享进入大数据领域需要的核心素质与技能,深入浅出的讲解,揭开了「大数据」及相关工作的神秘面纱。

以下是Live内容整理
大家好,欢迎参加我的Live,本次Live主要分为两部分内容。首先用三个典型的例子,来介绍发生在我们身边的大数据典型案例,其中哪些是大数据的精髓。接下来,我会用学科技能、科普书等,来介绍如何高效进入大数据领域。
洞见与价值
首先,用三个例子来讲解什么是大数据创新的理念、思想和方法。

第一个例子,用行为数据来预测学生的学习成绩。
这件事出发点有两个。第一个,我当老师之后,发现导致很多本科生成绩不好,很大的原因是因为沉迷游戏。当这些学生沉迷游戏半年到一年,考试成绩出现明显的下降时,再去进行纠正管理,乃至家长陪读,都很难取得很好的效果,因为他们已经养成了习惯。如果我们从他们日常生活中,就能发现沉迷游戏的趋势,就可以及时予以纠正。
第二个出发点,2015年我们曾经用电子科大学校数据做过一个很有趣的试验,观察了党员和非党员之间成绩的差异。发现以百分制计算的话,党员的平均成绩要比非党员高4分,或许有成绩较好的同学更容易入党的因素,但会不会有别的原因呢?
我们分析了这些同学的生活行为,找到了成都除节假日外最冷的20天,我们发现在这些日子里,党员平均能吃15次早餐,非党员吃早餐的平均次数只有8次。这说明党员比非党员对自我的要求更加严谨,这可能对成绩也造成了影响。这只是个很简单的分析工作,当时也得到了很多媒体的报道,因为这是个很典型的生活模式与学习成绩间关联的案例。
刚好也在2015年,BBC有个纪录片,有点讽刺中国教育的意味。一个强调纪律的中国高中老师到英国去上课,教育方式却并不被欧洲人买单。虽然纪录片最后以和解结束,但确实对中国的大班教育模式进行了批评。我一直在想,学生的行为,与学习成绩之间确实有关联吗?
基于这个想法,我们做了一套系统,专门预测学生本学期的成绩,它主要包括三种数据。
第一种是学生的历史成绩,以前考得好,本学期多半也不会差。
第二种,我们称之为diligence,就是学生的努力程度。这个数据包含了学生进出图书馆的次数和呆的时间,借了多少书,这些书以什么题材为主,乃至你在教学楼里打过多少次水。这些数据可以很容易的通过教务系统或者一卡通收集到,通过数据,能够很清楚的发现一个学生花了多少时间在学习上。
我今天重点讲的是第三组数据,我称之为orderness,即一个学生生活规律性与学习成绩之间的关系。
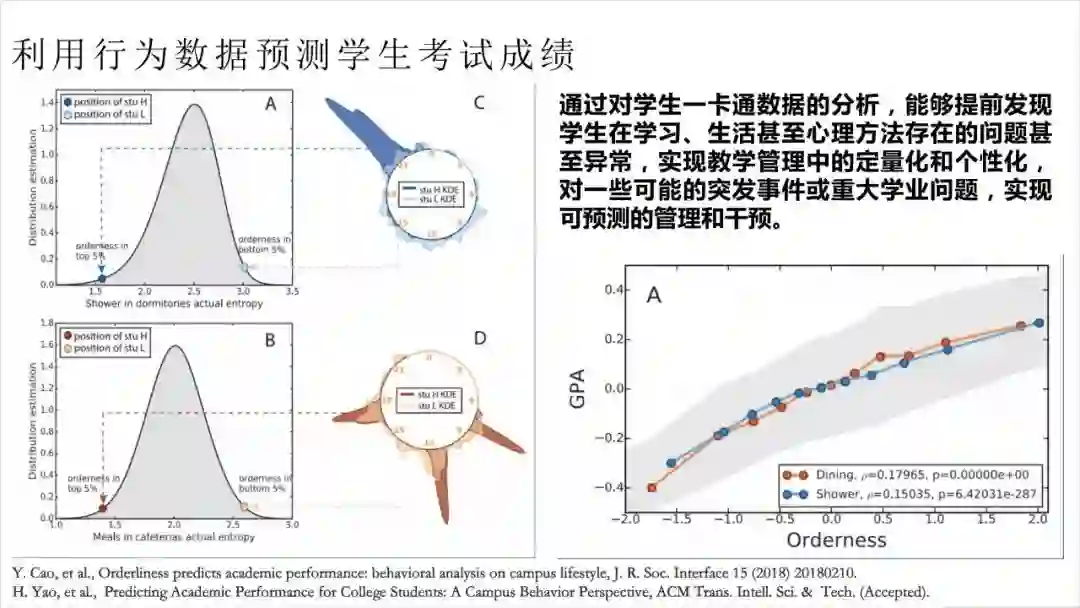
各位可以看PPT中A、C这两张图,这是学生洗澡频率的数据。通过收集学生洗澡时刷一卡通的数据,得出水龙头出第一滴热水的时间,在一天24小时内的分布。我们根据这个分布计算出真实熵,来推断学生的生活是否是有规律的。至于为什么用真实熵而不用香农熵,香农熵只能看到分布的集中程度,而真实熵不仅能看到分布的集中程度,还能看到时间序列的有序性。
为什么要检测时间序列的有序性呢?我们以一日三餐为例,两个学生都集中在8、12、18点吃饭,有一个学生吃饭没有规律,可能今天吃完早饭不吃午饭,明天不吃早饭只吃午饭和晚饭。而另一个学生有序的进行三餐,不会出现中间差一两顿的情况。后者生活肯定比前者更有规律。光用香农熵看集中程度是不够的,所以我们才用真实熵。
有了这些东西后,我们可以看A图,这是电子科技大学18960个本科生所有熵的分布。在分布的左边,熵比较小,生活有规律;分布的右边,熵比较大,生活没规律。我们在图的左边前5%中,选择任意一个生活有规律的人,C图中深蓝色就是他洗澡的时间分布,他主要在晚上9点洗澡。而在A图右边选一个生活没有规律的同学,洗澡时间反映在C图就是浅蓝色的部分。他一天24小时大部分时间都可能出现在澡堂里,他就是典型生活没有规律的人。通过这样一个简单的指标,我们就能区分一个学生的生活规律性。
类似的,我们来看B和D,其实就是学生在食堂用餐的时间分布。深红色代表的学生集中在8、12、17点左右在食堂刷卡用餐,这与学校日常学习时间高度相关。而浅红色代表的学生随时都可能在食堂刷卡进餐,很明显,他的生活没有规律。
大家可以在右边的图中看到,生活的规律性,和四年的GPA成绩是高度相关的。我们把历史考试成绩、努力程度、生活规律性这三组数据放在一起,便能很精确的预测学生本学期考试专业排名。根据结果给出的挂科预警的学生中,至少有80%一科不及格。
这个事情价值在哪里?以往只能在学生出现学业生活问题后,进行事后补救,往往为时已晚。而现在我们能从日常生活中发现趋势,运用这个系统提前去挽救学生。当然,与此同时我们也很注重隐私,开发团队拿到的都是匿名信息,只有在学生的行为触及到算法预警时,才会由后台自动发给学生的辅导员。这样我们能够在保护学生隐私的同时,提前给可能出现问题的学生正面的引导与干预。
第二个例子,自动驾驶的故事。
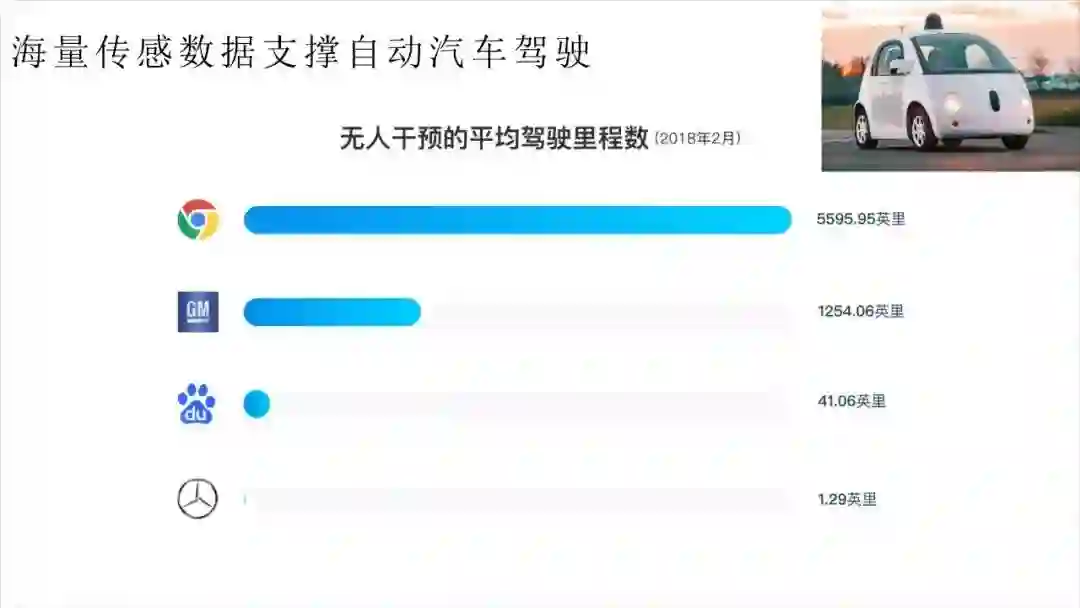
大家可以看PPT,这个讲的是从2018年2月往前一年内,各大研究无人驾驶的公司,无人驾驶实验平均进行多久才需要真人进行干预,里程越长,说明无人驾驶更成功。
从图中可以看出,不同公司间的差异非常大,第一的谷歌能够成功无人驾驶5595英里,而奔驰只能做到1.29英里,整整差了四千多倍。通用能达到1254英里,百度则为41英里。为什么会有这么大的差距呢?通用奔驰这样的传统汽车巨头,表现居然远远不如谷歌这样的互联网企业?
传统汽车制造企业,考虑无人驾驶时有两个出发点,一个是预算值,即一辆车要花费多少钱去配备传感器,在这个预算上去配置试验车。另一个是专家的知识,通过这些专家的经验,判断哪些数据值得收集,哪些是没有价值的,比如天气、湿度等数据的收集。
那谷歌怎么进行判断呢?也是两点,其一,由于预算非常充沛,可以在试验车上大量安装各种传感器。第二,由于他们在汽车专业领域并不太擅长,也不管什么数据有用什么数据没用,但凡能够安装上去的传感器统统装上。这就是谷歌的策略,无知但经费充沛。
由此,传统厂商可能有50辆试验车,每辆试验车配置都相同。而谷歌可能有上百辆试验车,而且不同试验车上配置的传感器是不同的。大家可以看到,两种不同策略之下,谷歌无人驾驶取得的成果远远超越了传统汽车企业,通用超越奔驰,也是因为后来学习了谷歌的策略。
最后一个例子,社会共治。
19大的时候,中央提出要建立智慧型社会,推动广泛意义下的社会共治。今天给大家讲一个用街景图片实现共治的例子。先用一个简单的例子来说明:我们能否实现在线选美。
假设有两千个女生,很难实现同时给两千个女生长相排序,甚至同时给十几个排序都做不到。有个很简单的办法,一次给你看随机两个人的照片,在其中选择好看的。一个人可以很快的做出上百次比较,而当更多人同时做这种比较时,数据就能快的收集起来。有了这个数据,就能完成两千人的相貌排序,这是个很简单的算法。
有了这个思路,我们做了个很好玩的事情。首先通过高德百度等渠道,拿到了上百万张成都的街景照片,从中选出了几千张,征集志愿者,每次随机出现两张街景图片,让志愿者从一个维度进行比较,维度分为卫生、绿化、基建、安全感等几个层面。我们现在以安全为例,一次两张随机图片进行对比,当达到一定数量时,我们就能在安全维度上进行排序,再映射到0~1空间中,就能给不同街景安全性进行打分。这时候就变成了一个非常典型的深度学习的问题,计算机可以通过卷积神经网络的某种变体,来学习为这些街景图片进行打分。
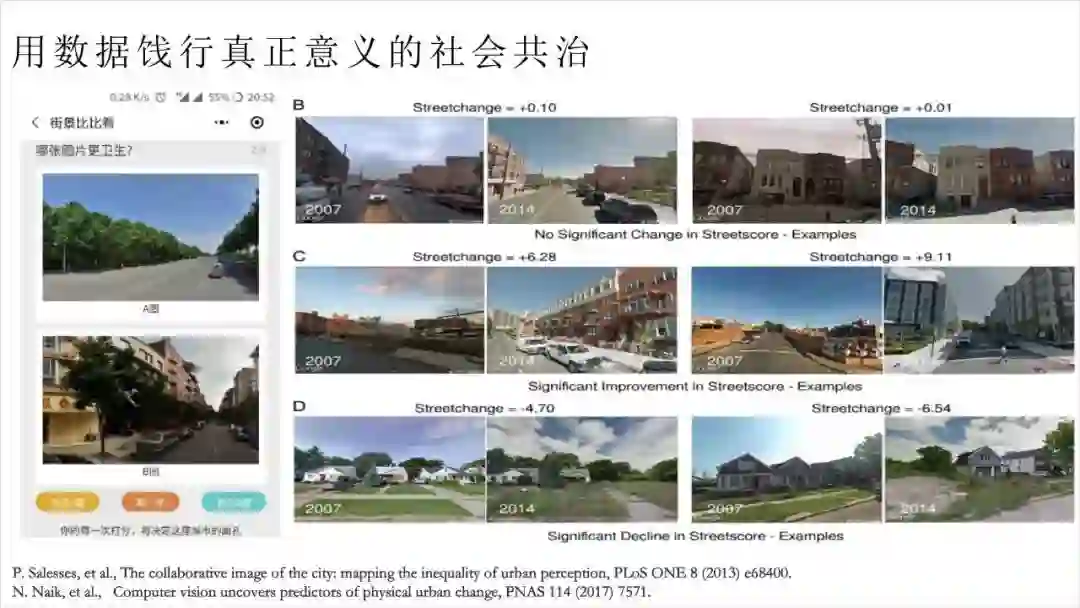
这些图片,最开始是人类来进行选择,通过将这些选择进行排序,计算机就学会给街景图片打分,从而给上百万的图片打分。只需要采访很小一部分人,就能得到一座城市街景各个维度的分数,这是件非常了不起的事情,这就是计算机,或者机器学习的魅力。
有了这个工具,政府能够做到两件事。首先可以直观的看到成都哪个地方最脏乱差,基建最不完善,有利于安排城市治理工作。第二得知之前做的治理工作是否有成效。PPT里是相同几个地方,07年与14年谷歌街景地图的对比。第一行差异不大,第二行前后有明显的改善,第三行则发生了明显的退步。通过这种方式观察城市治理是否有成效,比传统一层层上报要直观且有效率。
大数据理念的精髓
以上例子都是很前沿的一些进展,我个人觉得非常漂亮。接下来我通过这些例子,给大家总结一下我所认为的大数据里的精髓,当然不能全部总结完毕,但其中有许多值得学习的东西。

大概分为四个方面:
第一,让数据说话。在搞大数据、人工智能时,没必要让传统的专家知识来告诉我们哪些有用哪些没用,而是通过算法,让数据自己得出哪些有价值。现在很多大规模的数据计算,比如淘宝推荐,都是几亿甚至上百亿的数据得出的结论,而不是通过一两个所谓专家的推荐。
第二,数据外部化。像刚才举的学校规律化的例子,原始数据来自一卡通。这一开始只是后勤部门为了方便挣钱而搞出的系统,我们却能用这个系统里的数据来解决学生的学业问题,最近还在做预测学生心理问题的工作,有没有交际障碍。将看上去风马牛不相及的数据放在一起,反而能得到意想不到的成果。基于此,我们要推动数据的外部化,打破边界。
第三,群集智能。很多东西你分析一个点、一个事件可能看不出什么,当分析很多个类似事件时候,就能发现其中规律。大数据能发挥群集智能,是集体智慧最大的武器,大数据做社会共治就是很典型的例子。各位如果对推荐系统比较熟悉,我们讲协同过滤,电商猜你要买什么东西,不仅看你买过什么,还要看和你买过相同东西的人,他们买过什么,你没有买,就将这些东西推荐给你,这也是很典型的群集智能。
最后一点,算法。大数据不是放在那里就能产生价值的,要采用人工智能中的算法,譬如机器学习、数据挖掘等等,获得简单数据分析中不能得到的洞见,再来指导进行高效的决策。
知识与技能
接下来我从四方面给大家讲知识与技能,先讲核心的学科知识,然后是主流技术,再讲典型的职业发展路径,最后介绍几本我觉得还不错的书。

核心学科知识可以看下图,基本已经完全概括了和计算机思维有关的核心学科知识,主要是三门:离散数学、数据结构和算法设计,另外概率论和数理统计同样相关,统计需要学得很深入,多元统计分析、因果分析等都要掌握,这对于后期来讲非常重要。

想做数据科学的话,我给大家两个建议。
第一,扎扎实实学好数学、物理和计算机。在本科阶段,能谈得到“思维方式”的就这三个,它们是地基,打得越扎实,才能走得越远。数据结构和算法都学好了,学习计算机语言是非常轻松的。
第二,要有多学科的视野。做一个数据科学家,要对社会学、心理学、金融学乃至生命科学都有了解,形成交叉学科的视野。
总结一下,夯实数理计的理论和思维基础,通过大量阅读形成多学科视野,这两方面的基础扎实了,你的核心学科知识也能够前进。
接下来是职场主流技术。
这是DataCasle数据城堡收集了求职者与企业方的职业需求后,生成的云图,里面越突出的就是最主流的技术。大体上大数据发展有四个方向。

一、往基础走,元数据的治理。海量的、来自不同系统的数据,怎样给出给具体的标准,在不影响这些信息化系统运作的同时,自动的快速清洗这些数据,使之标准化。
二、往上走,人工智能的算法。如何处理这些标准化后的数据,涉及机器学习、数据挖掘等算法发展。
三、软硬件的结合。高端点人工智能的芯片,基础点传感器采集端的的处理。
四、数据的高效处理。基于内存的计算和数据库,如何高效处理这些非标准化的语音、视频等信息,形成新的数据结构和储存方式。
然后是职业发展方向。
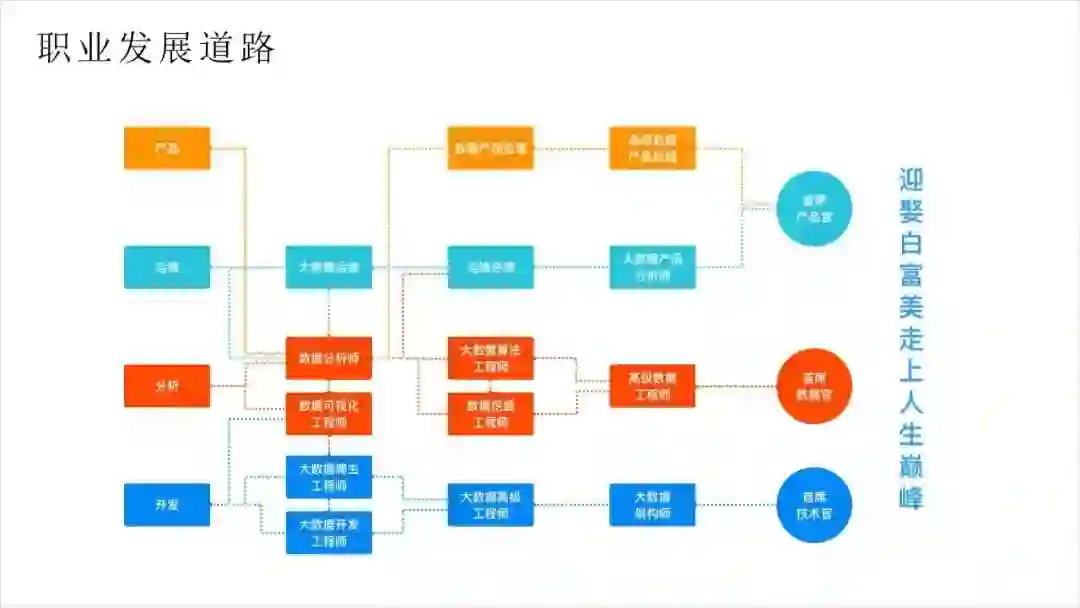
其实这个并没有大家想象的那么重要,只要学得足够好,选择空间其实很大。我大体上将之分为产品、运维、分析和开发四条线,之间互有交叉。最终目的当然是迎娶白富美走上人生巅峰了,根本还是要看你是否能真正掌握技术。
最后给大家介绍五本不错的入门读物。

第一本是现象级的《大数据时代》。实体书加上电子书,销售量达到了两百万册,在经管类图书里数一数二。作者维克托先后在哈佛和牛津任教,很聪明的一个人,这本书也是大数据领域的开先河之作,影响很大。这本书的特点是观点非常清楚,比如他指出大数据的核心就是预测,是全量而非抽样等等。整本书风格从不拖泥带水,尽管很多我并不同意。我是这本书的译者,在中国这本书的销量也远远超过了其他国家。
前不久作者和我同时参加电子科大的成电讲坛,讲了个关于他自己的段子。当他十四五岁时学习计算机语言,觉得非常容易,但到了二十七八岁学习c++时,觉得思维有点跟不上了,很难。于是他在去年四十七岁的时候做了个决定,逼自己用半年时间再去学一门新的计算机语言,让自己不要变得太笨。一个在全世界都享有盛誉的学者,依然在不断警惕自身是否落伍,这种精神很值得学习。
第二本是国内学者在大数据领域最早的著作《证析》。这本书非常的扎实,作者郑毅是我很好的朋友,读书无穷,我到他家做客时看见满屋子全是书。这本书讲了很多数据应用的误区,值得一看。
第三本推荐我自己的《为数据而生》。这本书将大数据分析的分析、外化、集成等阶段分得很清楚,我也仔细的分析了各种理念,深度剖析了许多行业创新案例,直接采访了这些创新团队,应该是最接地气的一本书。
第四本是徐子沛的《数据之巅》。作者之前写过一本主要讲数据开放方面的《大数据》,这本书集中了前书的精髓,以美国为主,阐述了整个数据时代发展的历史,格局很高,历史纵深感很强,试图把数据科学从一个科学符号,转变为文化符号。
最后推荐给大家的是车品觉的《决战大数据》。作者之前在阿里巴巴担任数据委员会主席、副总裁、首席商务智能官。国内很少有人像他那样在数据运营方面踩过那么多的坑,吃过那么多的苦头,这本书可以说是他多年实战的泣血经验。想了解什么是数据化运营,怎么在大中型企业做数据管理的话,这本书值得一读。
今天的Live主体就到这里,数据科学家应该说是未来最性感的职业之一,非常好玩。路要一步步走,大家在学生阶段,真的要花苦力去学习。如果已经工作了的话,可能没办法再去学算法,那么一定要多去读科普书,了解理念和精髓。谢谢大家。
关于作者
周涛,电子科技大学教授,主要从事统计物理与复杂性方面的研究。在 Physics Reports、PNAS、Nature Communications 等国际 SCI 期刊发表 300 余篇学术论文,引用 20000 余次,H 指数为68。2009 年获教育部自然科学一等奖,2011 年获第十二届中国青年科技奖,2014 年后持续入选 Elesvier 最具国际影响力中国科学家名单(物理天文类)。2015 年当选第十二届中华全国青联常务委员,并担任科学技术界别工作委员会副主任。2015 年当选全国十大科技创新人物。2017 年获全国创新争先奖。
转自:DataCastle数据城堡

文末福利 · 长按识别下方二维码关注公众号,关注公众号,后台回复对应的关键字下载资料:
1.《中国人工智能发展报告2018》,关键字“人工智能2018”
2.《人工智能标准化白皮书(2018版)》,关键字“AI2018”
3.《中国信通院:物联网白皮书2018》,关键字“物联网2018”
4.《大数据标准化白皮书(2018版)》,关键字“大数据标准化白皮书2018”
5.《2018年中国机器人产业发展报告》,关键字“机器人产业报告2018”
6.《2018顶级数据团队全景报告-简版》,关键字“2018顶级数据团队全景报告”
更多内容下载,可关注公众号后,选择“更多内容” >> 选择“资料下载”
更多精彩内容请识别二维码关注微信号





