夺魁NeurIPS 2020电网调度大赛,百度PARL实现NeurIPS强化学习竞赛三连冠
深度强化学习实验室
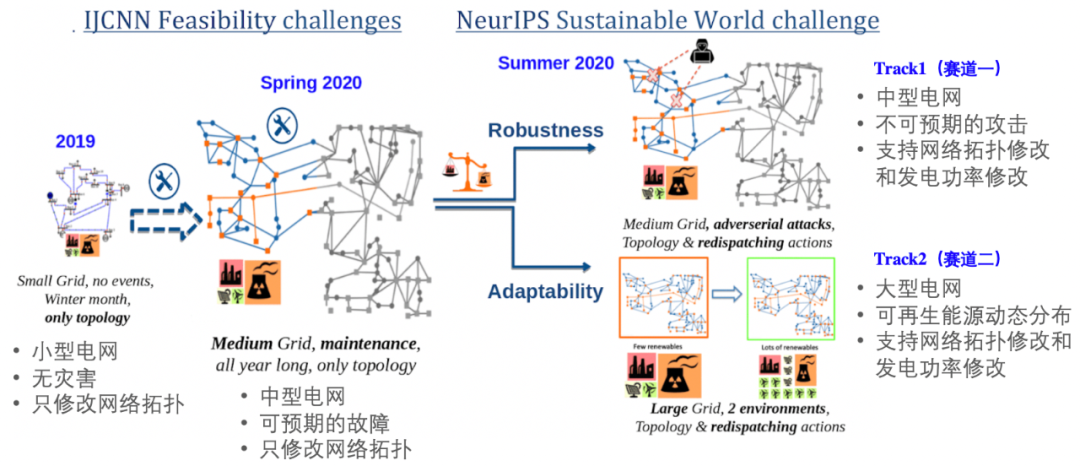
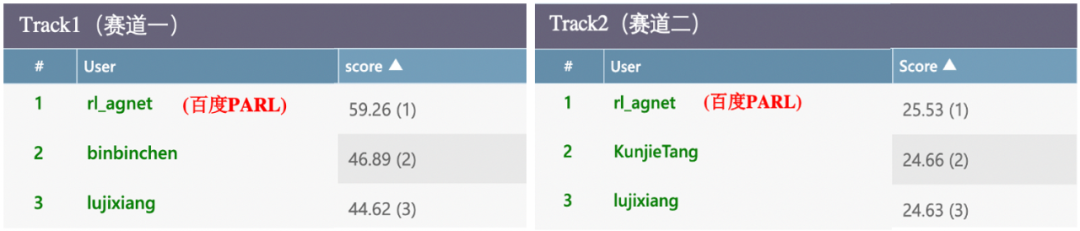
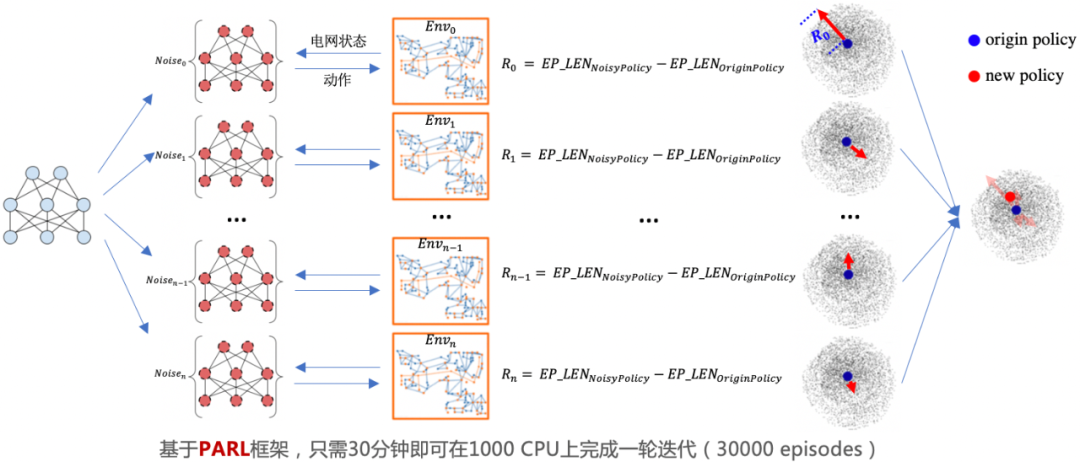
受疫情影响,人工智能顶级学术会议 NeurIPS 2020 将通过线上的形式进行。随着会议召开时间临近,该会议承办的竞赛也陆续揭晓结果。今年新增的电网调度竞赛(Learning To Run a Power Network Challenge)共包含两个赛道:鲁棒能力赛道和泛化能力赛道,经过三个月的激烈比拼,最终来自百度的 PARL 团队拿下全部两个赛道的冠军。同时,这也是该团队在 NeurIPS 上拿下的第三个强化学习赛事冠军,实现三连冠的里程碑。

Track 1(赛道一):采用中型电网(相当于三分之一的美国中西部电网),离散动作空间数量有 6 万多个。该赛道中,每天电网的不同线路会因随机的攻击而断开,以此模拟现实生活中电网系统受到不可预期的事故(例如被闪电击中),对决策系统在各种突发事件下的鲁棒性而言,是个很大的挑战。
Track 2(赛道二):采用大型电网(相当于整个美国中西部电网),离散动作空间数量高达 7 万多个。该赛道中,发电厂的可再生能源比例是动态变化的(比如风能在夏季发电效率高,冬季则下降),为了保持整个电网的供需平衡,这个赛道对决策系统在不同能源比例下的自动适应能力有很高的要求。
开源链接:https://github.com/PaddlePaddle/PARL
竞赛地址:https://l2rpn.chalearn.org/competitions
完
总结3: 《强化学习导论》代码/习题答案大全
总结6: 万字总结 || 强化学习之路
完
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第77篇:深度强化学习工程师/研究员面试指南
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)




