听同事讲 Bayesian statistics: Part 2 - Bayesian inference
有一次M早上来得比较晚,进办公室以后就开始抱怨地铁又晚点了,而且同一周不只发生了一次。我说,作为 statistician,你就不能 predict 一下地铁会不会晚点吗?她说,"This is a very tricky problem. There are so many unknown factors." “好吧,那算一下地铁晚点的概率总可以吧?” "Great! Let's do it now!” 说完M就拿起笔开始在白板上写起公式来,当然用的是 Bayesian 的方法。
通常拿到一个问题后,第一步要做的,就是要简化这个问题。M做的简化是:假设每天地铁迟到的概率是一样的,记为 t。当然,这个假设有不合理的地方,比如周一、周二早上乘地铁的人比较多,而周五不少人 work from home 所以乘地铁的人相对较少,这样导致地铁在每周不同的天里迟到的概率可能不同。但任何假设都有不完善的地方,如果乘客人数不是主导因素的话,那么我们就可以做这样的近似。问题简化后,每天地铁是否迟到就是一个 Bernoulli 分布,N 天中地铁迟到的次数 n 则为一个 binomial 分布。
以M过去两周的经验来说,总共10天里,地铁迟到了3次。那么地铁迟到的概率 t 是多少呢?
上一期中我们提到了 frequentist 和 Bayesian 之间的区别。其中最主要的一点是,frequentist 认为参数是固定的,而 Bayesian 认为参数和其它随机变量没有区别,它们也是随机变量,它们的 distribution 就是我们对其值 belief 的 distribution。在我们这个问题里,t 就是参数。
首先大致地讲一下 frequentist 的做法。Frequentist 求解参数,一般用 maximum likelihood 方法。参数的 likelihood 也就是 data 的 probability。假设 N 天里,地铁迟到了 n 次,那么 likelihood 为,
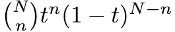
这个公式不是很讨好,我们来把它变换一下。我们知道,log 函数不会改变原函数的大小关系 (monotonic),所以,maximum likelihood 等价于 maximum log-likelihood。公式变成了,
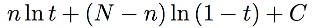
C为常数,不取决于 t 的值。我们可以很容易地求得当 t = n / N 时,上面地 log-likelihood 取得最大值。好的,frequentist 的结果为 n / N = 3 / 10 = 0.3,即地铁迟到的概率为30%。
Bayesian 方法怎么去做呢?还记得上一期我们提到的 Bayesian 理念吧。我们需要给 t 一个 prior distribution。我们知道,t 作为概率是介于0到1之间的,它最常用的 prior 是 beta distribution。可能很多学友不是特别熟悉 beta distribution,但对于 statistician 尤其是 Bayesian statistician 来说,它是最基本的一种 distribution。我们在这儿不讨论 beta distribution 的细节。需要大体了解一下,它有两个参数,pdf 的图形如下,
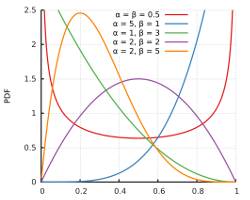
它的表达式为,
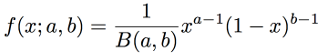
如果我们认为 t 是从0到1均匀分布的,我们可以用 uniform 作为它的 prior,也就是 t ~ Beta(1, 1) = uniform。这个 prior 没有融入任何主观的猜测,所以这样的 prior 也叫做 uninformative prior。其实,即便是这样的 prior,它也提供了一定的信息,比如 t 的值不会小于0或者大于1 。所以,uninformative prior 名字有些歧义,它实际上是 less informative prior。
知道了参数的 prior distribution 和 likelihood,那么 posterior distribution 是不是很容易求得呢?答案是否定的。只有一些特定的 distribution (比如 Gaussian distribution) 才可以写出它的解析式。即便写出它的解析式,很多情况下 posterior 的一些 statistics 是很难求得的。这是就需要请出强大的 MCMC (Markov chain Monte Carlo),这个后面一定会讲到。
好的,我们计算一下,给了数据 D 后,参数 t 的 posterior distribution 为,
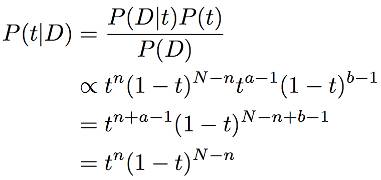
对于很多其他形式的 posterior 来说,位于分母的积分 P(D) 并不容易计算。幸运的是,这个积分的值并不取决于参数的值,而分子才是决定参数的重要因素。从这个角度来说,分母的作用只是 normalization 而已,对决定参数分布作用不大 。
还有一个有趣的现象是,算得的 posterior 和 prior 形式上是一样的。这也是当 likelihood 为 binomial 时,我们选择 beta distribution 作为 prior 的好处。对于不同的 likelihood,选择一些特定的 prior 可以使得 posterior 与 prior 形式一致,给计算带来方便。这样的 prior,称之为 conjugate prior。
我们最后求得 t 的 posterior 为 Beta(n+1, N-n+1),即 Beta(4, 8),它的 mode 是 0.3,而 mean 是 1 / 3。
假如说我们只想用一个值而不是 distribution 来表示参数,很多情况下我们会选择 mode,也就是让 posterior 最大的那个参数值。这个方法也叫做 maximum a posteriori (MAP)。如果 prior 是 uniform 的话,它跟 frequentist 的 maximum likelihood 得到的结果一样。当然,maximum a posteriori 是一个过于简单的方法,用一个值来代替整个 distribution 显然是不准确或不完备的。我们后面会讲到 Bayesian 是怎样利用 posterior 来做 prediction 的。
DeepLearning中文论坛公众号的原创文章,欢迎转发;如需转载,请注明出处。谢谢!
长按以下二维码,关注该公众号