备战AI求职季 | 100道机器学习面试题(下)

导读:备战AI求职季,小编给大家了准备了100道关于机器学习方面的面试题,上周给大家整理了前50道「备战AI求职季 | 100道机器学习面试题(上)」。今天,继续更新后面50题,希望能助大家一臂之力,都能斩获高薪offer。(PS:有些题目解析较长,简单写了几行,解析未完的题目后面有注明在官网题库对应的机器学习类目下第几题)
51、请问怎么处理特征向量的缺失值
解析:
一方面,缺失值较多.直接将该特征舍弃掉,否则可能反倒会带入较大的noise,对结果造成不良影响。
另一方面缺失值较少,其余的特征缺失值都在10%以内,我们可以采取很多的方式来处理:
1) 把NaN直接作为一个特征,假设用0表示;
2) 用均值填充;
3) 用随机森林等算法预测填充。
52、SVM、LR、决策树的对比。
解析:
模型复杂度:SVM支持核函数,可处理线性非线性问题;LR模型简单,训练速度快,适合处理线性问题;决策树容易过拟合,需要进行剪枝
损失函数:SVM hinge loss; LR L2正则化; adaboost 指数损失
数据敏感度:SVM添加容忍度对outlier不敏感,只关心支持向量,且需要先做归一化; LR对远点敏感
数据量:数据量大就用LR,数据量小且特征少就用SVM非线性核
53、什么是ill-condition病态问题?
解析:
训练完的模型,测试样本稍作修改就会得到差别很大的结果,就是病态问题,模型对未知数据的预测能力很差,即泛化误差大。
54、简述KNN最近邻分类算法的过程?
解析:
1. 计算测试样本和训练样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);
2. 对上面所有的距离值进行排序;
3. 选前 k 个最小距离的样本;
4. 根据这 k 个样本的标签进行投票,得到最后的分类类别;
55、常用的聚类划分方式有哪些?列举代表算法。
解析:
1. 基于划分的聚类:K-means,k-medoids,CLARANS。
2. 基于层次的聚类:AGNES(自底向上),DIANA(自上向下)。
3. 基于密度的聚类:DBSACN,OPTICS,BIRCH(CF-Tree),CURE。
4. 基于网格的方法:STING,WaveCluster。
5. 基于模型的聚类:EM,SOM,COBWEB。
56、什么是偏差与方差?
解析:
泛化误差可以分解成偏差的平方加上方差加上噪声。偏差度量了学习算法的期望预测和真实结果的偏离程度,刻画了学习算法本身的拟合能力,方差度量了同样大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动所造成的影响,噪声表达了当前任务上任何学习算法所能达到的期望泛化误差下界,刻画了问题本身的难度。偏差和方差一般称为bias和variance,一般训练程度越强,偏差越小,方差越大,泛化误差一般在中间有一个最小值,如果偏差较大,方差较小,此时一般称为欠拟合,而偏差较小,方差较大称为过拟合。
偏差:

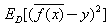
方差:
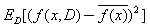
57、采用 EM 算法求解的模型有哪些,为什么不用牛顿法或梯度下降法?
解析:
用EM算法求解的模型一般有GMM或者协同过滤,k-means其实也属于EM。EM算法一定会收敛,但是可能收敛到局部最优。由于求和的项数将随着隐变量的数目指数上升,会给梯度计算带来麻烦。
58、xgboost怎么给特征评分?
解析:
在训练的过程中,通过Gini指数选择分离点的特征,一个特征被选中的次数越多,那么该特征评分越高。
[python] # feature importance
print(model.feature_importances_)
# plot pyplot.bar(range(len(model.feature_importances_)), model.feature_importances_)
pyplot.show() ==========
# plot feature importance
plot_importance(model)
pyplot.show()
59、什么是OOB?随机森林中OOB是如何计算的,它有什么优缺点?
解析:
bagging方法中Bootstrap每次约有1/3的样本不会出现在Bootstrap所采集的样本集合中,当然也就没有参加决策树的建立,把这1/3的数据称为袋外数据oob(out of bag),它可以用于取代测试集误差估计方法。
袋外数据(oob)误差的计算方法如下:
对于已经生成的随机森林,用袋外数据测试其性能,假设袋外数据总数为O,用这O个袋外数据作为输入,带进之前已经生成的随机森林分类器,分类器会给出O个数据相应的分类,因为这O条数据的类型是已知的,则用正确的分类与随机森林分类器的结果进行比较,统计随机森林分类器分类错误的数目,设为X,则袋外数据误差大小=X/O;这已经经过证明是无偏估计的,所以在随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计。
60、推导朴素贝叶斯分类 P(c|d),文档 d(由若干 word 组成),求该文档属于类别 c 的概率, 并说明公式中哪些概率可以利用训练集计算得到
解析:
根据贝叶斯公式P(c|d)=(P(c)P(d|c)/P(d))
这里,分母P(d)不必计算,因为对于每个类都是相等的。 分子中,P(c)是每个类别的先验概率,可以从训练集直接统计,P(d|c)根据独立性假设,可以写成如下 P(d|c)=¥P(wi|c)(¥符号表示对d中每个词i在c类下概率的连乘),P(wi|c)也可以从训练集直接统计得到。 至此,对未知类别的d进行分类时,类别为c=argmaxP(c)¥P(wi|c)。
61、请写出你对VC维的理解和认识
解析:
VC维是模型的复杂程度,模型假设空间越大,VC维越高。某种程度上说,VC维给机器学习可学性提供了理论支撑。
1.测试集合的loss是否和训练集合的loss接近?VC维越小,理论越接近,越不容易overfitting。
2.训练集合的loss是否足够小?VC维越大,loss理论越小,越不容易underfitting。
我们对模型添加的正则项可以对模型复杂度(VC维)进行控制,平衡这两个部分。
62、kmeans聚类中,如何确定k的大小
解析:
这是一个老生常谈的经典问题,面试中也经常问。
K-均值聚类算法首先会随机确定k个中心位置,然后将各个数据项分配给最临近的中心点。待分配完成之后,聚类中心就会移到分配给该聚类的所有节点的平均位置处,然后整个分配过程重新开始。这一过程会一直重复下去,直到分配过程不再产出变化为止。
本题完整解析:七月在线官网 → 面试题库 → 面试大题 → 机器学习(92题),或七月在线APP → 题库 → 面试大题 → 机器学习(92题)
63、请用Python实现下线性回归,并思考下更高效的实现方式
解析:
在数学中,线性规划 (Linear Programming,简称LP) 问题是目标函数和约束条件都是线性的最优化问题。
线性规划是最优化问题中的重要领域之一。很多运筹学中的实际问题都可以用线性规划来表述。线性规划的某些特殊情况,例如网络流、多商品流量等问题,都被认为非常重要,并有大量对其算法的专门研究。很多其他种类的最优化问题算法都可以分拆成线性规划子问题,然后求得解。
在历史上,由线性规划引申出的很多概念,启发了最优化理论的核心概念,诸如“对偶”、“分解”、“凸性”的重要性及其一般化等。同样的,在微观经济学和商业管理领域,线性规划被大量应用于解决收入极大化或生产过程的成本极小化之类的问题。
本题完整解析:七月在线官网 → 面试题库 → 面试大题 → 机器学习(93题),或七月在线APP → 题库 → 面试大题 → 机器学习(93题)
64、给你一个有1000列和1百万行的训练数据集。这个数据集是基于分类问题的。 经理要求你来降低该数据集的维度以减少模型计算时间。你的机器内存有限。你会怎么做?(你可以自由做各种实际操作假设)
解析:
答:你的面试官应该非常了解很难在有限的内存上处理高维的数据。以下是你可以使用的处理方法:
1.由于我们的RAM很小,首先要关闭机器上正在运行的其他程序,包括网页浏览器,以确保大部分内存可以使用。
2.我们可以随机采样数据集。这意味着,我们可以创建一个较小的数据集,比如有1000个变量和30万行,然后做计算。
3.为了降低维度,我们可以把数值变量和分类变量分开,同时删掉相关联的变量。对于数值变量,我们将使用相关性分析。对于分类变量,我们可以用卡方检验。
4.另外,我们还可以使用PCA(主成分分析),并挑选可以解释在数据集中有最大偏差的成分。
5.利用在线学习算法,如VowpalWabbit(在Python中可用)是一个可能的选择。
6.利用Stochastic GradientDescent(随机梯度下降)法建立线性模型也很有帮助。
7.我们也可以用我们对业务的理解来估计各预测变量对响应变量的影响大小。但是,这是一个主观的方法,如果没有找出有用的预测变量可能会导致信息的显著丢失。
注意:对于第4和第5点,请务必阅读有关在线学习算法和随机梯度下降法的内容。这些是高阶方法。
65、问2:在PCA中有必要做旋转变换吗? 如果有必要,为什么?如果你没有旋转变换那些成分,会发生什么情况?
解析:
答:是的,旋转(正交)是必要的,因为它把由主成分捕获的方差之间的差异最大化。这使得主成分更容易解释。但是不要忘记我们做PCA的目的是选择更少的主成分(与特征变量个数相较而言),那些选上的主成分能够解释数据集中最大方差。
通过做旋转,各主成分的相对位置不发生变化,它只能改变点的实际坐标。如果我们没有旋转主成分,PCA的效果会减弱,那样我们会不得不选择更多个主成分来解释数据集里的方差。
注意:对PCA(主成分分析)需要了解更多。
66、给你一个数据集,这个数据集有缺失值,且这些缺失值分布在离中值有1个标准偏差的范围内。百分之多少的数据不会受到影响?为什么?
解析:
答:这个问题给了你足够的提示来开始思考!由于数据分布在中位数附近,让我们先假设这是一个正态分布。
我们知道,在一个正态分布中,约有68%的数据位于跟平均数(或众数、中位数)1个标准差范围内的,那样剩下的约32%的数据是不受影响的。
因此,约有32%的数据将不受到缺失值的影响。
67、给你一个癌症检测的数据集。你已经建好了分类模型,取得了96%的精度。为什么你还是不满意你的模型性能?你可以做些什么呢?
解析:
答:如果你分析过足够多的数据集,你应该可以判断出来癌症检测结果是不平衡数据。在不平衡数据集中,精度不应该被用来作为衡量模型的标准,因为96%(按给定的)可能只有正确预测多数分类,但我们感兴趣是那些少数分类(4%),是那些被诊断出癌症的人。
因此,为了评价模型的性能,应该用灵敏度(真阳性率),特异性(真阴性率),F值用来确定这个分类器的“聪明”程度。如果在那4%的数据上表现不好,我们可以采取以下步骤:
1.我们可以使用欠采样、过采样或SMOTE让数据平衡。
2.我们可以通过概率验证和利用AUC-ROC曲线找到最佳阀值来调整预测阀值。
3.我们可以给分类分配权重,那样较少的分类获得较大的权重。
4.我们还可以使用异常检测。
注意:要更多地了解不平衡分类
68、解释朴素贝叶斯算法里面的先验概率、似然估计和边际似然估计?
解析:
先验概率就是因变量(二分法)在数据集中的比例。这是在你没有任何进一步的信息的时候,是对分类能做出的最接近的猜测。
例如,在一个数据集中,因变量是二进制的(1和0)。例如,1(垃圾邮件)的比例为70%和0(非垃圾邮件)的为30%。因此,我们可以估算出任何新的电子邮件有70%的概率被归类为垃圾邮件。
似然估计是在其他一些变量的给定的情况下,一个观测值被分类为1的概率。例如,“FREE”这个词在以前的垃圾邮件使用的概率就是似然估计。边际似然估计就是,“FREE”这个词在任何消息中使用的概率
69、你正在一个时间序列数据集上工作。经理要求你建立一个高精度的模型。你开始用决策树算法,因为你知道它在所有类型数据上的表现都不错。 后来,你尝试了时间序列回归模型,并得到了比决策树模型更高的精度。 这种情况会发生吗?为什么?
解析:
众所周知,时间序列数据有线性关系。另一方面,决策树算法是已知的检测非线性交互最好的算法。
为什么决策树没能提供好的预测的原因是它不能像回归模型一样做到对线性关系的那么好的映射。
因此,我们知道了如果我们有一个满足线性假设的数据集,一个线性回归模型能提供强大的预测。
70、给你分配了一个新的项目,是关于帮助食品配送公司节省更多的钱。问题是,公司的送餐队伍没办法准时送餐。结果就是他们的客户很不高兴。 最后为了使客户高兴,他们只好以免餐费了事。哪个机器学习算法能拯救他们?
解析:
你的大脑里可能已经开始闪现各种机器学习的算法。但是等等!这样的提问方式只是来测试你的机器学习基础。这不是一个机器学习的问题,而是一个路径优化问题。
机器学习问题由三样东西组成:
1.模式已经存在。
2.不能用数学方法解决(指数方程都不行)。
3.有相关的数据。
71、你意识到你的模型受到低偏差和高方差问题的困扰。应该使用哪种算法来解决问题呢?为什么?
解析:
低偏差意味着模型的预测值接近实际值。换句话说,该模型有足够的灵活性,以模仿训练数据的分布。貌似很好,但是别忘了,一个灵活的模型没有泛化能力。这意味着,当这个模型用在对一个未曾见过的数据集进行测试的时候,它会令人很失望。
在这种情况下,我们可以使用bagging算法(如随机森林),以解决高方差问题。bagging算法把数据集分成重复随机取样形成的子集。然后,这些样本利用单个学习算法生成一组模型。接着,利用投票(分类)或平均(回归)把模型预测结合在一起。
另外,为了应对大方差,我们可以:
1.使用正则化技术,惩罚更高的模型系数,从而降低了模型的复杂性。
2.使用可变重要性图表中的前n个特征。可以用于当一个算法在数据集中的所有变量里很难寻找到有意义信号的时候。
72、给你一个数据集。该数据集包含很多变量,你知道其中一些是高度相关的。 经理要求你用PCA。你会先去掉相关的变量吗?为什么?
解析:
答:你可能会说不,但是这有可能是不对的。丢弃相关变量会对PCA有实质性的影响,因为有相关变量的存在,由特定成分解释的方差被放大。
例如:在一个数据集有3个变量,其中有2个是相关的。如果在该数据集上用PCA,第一主成分的方差会是与其不相关变量的差异的两倍。此外,加入相关的变量使PCA错误地提高那些变量的重要性,这是有误导性的。
73、花了几个小时后,现在你急于建一个高精度的模型。结果,你建了5 个GBM (Gradient Boosted Models),想着boosting算法会显示魔力。 不幸的是,没有一个模型比基准模型表现得更好。最后,你决定将这些模型结合到一起。 尽管众所周知,结合模型通常精度高,但你就很不幸运。你到底错在哪里?
解析:
答:据我们所知,组合的学习模型是基于合并弱的学习模型来创造一个强大的学习模型的想法。但是,只有当各模型之间没有相关性的时候组合起来后才比较强大。由于我们已经试了5个 GBM,但没有提高精度,表明这些模型是相关的。
具有相关性的模型的问题是,所有的模型提供相同的信息。例如:如果模型1把User1122归类为 1,模型2和模型3很有可能会做有同样分类,即使它的实际值应该是0,因此,只有弱相关的模型结合起来才会表现更好。
74、KNN和KMEANS聚类(kmeans clustering)有什么不同?
解析:
答:不要被它们的名字里的“K”误导。
你应该知道,这两种算法之间的根本区别是,KMEANS本质上是无监督学习而KNN是监督学习。KMEANS是聚类算法。KNN是分类(或回归)算法。
KMEAN算法把一个数据集分割成簇,使得形成的簇是同构的,每个簇里的点相互靠近。该算法试图维持这些簇之间有足够的可分离性。由于无监督的性质,这些簇没有任何标签。NN算法尝试基于其k(可以是任何数目)个周围邻居来对未标记的观察进行分类。它也被称为懒惰学习法,因为它涉及最小的模型训练。因此,它不用训练数据对未看见的数据集进行泛化。
75、真阳性率和召回有什么关系?写出方程式。
解析:
答:真阳性率=召回。是的,它们有相同的公式(TP / TP + FN)。 注意:要了解更多关于估值矩阵的知识。
76、你建了一个多元回归模型。你的模型R2为并不如你设想的好。为了改进,你去掉截距项,模型R的平方从0.3变为0.8。 这是否可能?怎样才能达到这个结果?
解析:
答:是的,这有可能。我们需要了解截距项在回归模型里的意义。截距项显示模型预测没有任何自变量,比如平均预测。公式R² = 1 – ∑(y – y´)²/∑(y – ymean)²中的y´是预测值。
当有截距项时,R²值评估的是你的模型基于均值模型的表现。在没有截距项(ymean)时,当分母很大时,该模型就没有这样的估值效果了,∑(y – y´)²/∑(y – ymean)²式的值会变得比实际的小,而R2会比实际值大。
77、在分析了你的模型后,经理告诉你,你的模型有多重共线性。 你会如何验证他说的是真的?在不丢失任何信息的情况下,你还能建立一个更好的模型吗?
解析:
答:要检查多重共线性,我们可以创建一个相关矩阵,用以识别和除去那些具有75%以上相关性(决定阈值是主观的)的变量。此外,我们可以计算VIF(方差膨胀因子)来检查多重共线性的存在。
VIF值<= 4表明没有多重共线性,而值> = 10意味着严重的多重共线性。
此外,我们还可以用容差作为多重共线性的指标。但是,删除相关的变量可能会导致信息的丢失。为了留住这些变量,我们可以使用惩罚回归模型,如Ridge和Lasso回归。
我们还可以在相关变量里添加一些随机噪声,使得变量变得彼此不同。但是,增加噪音可能会影响预测的准确度,因此应谨慎使用这种方法。
78、什么时候Ridge回归优于Lasso回归?
解析:
答:你可以引用ISLR的作者Hastie和Tibshirani的话,他们断言在对少量变量有中等或大尺度的影响的时候用lasso回归。在对多个变量只有小或中等尺度影响的时候,使用Ridge回归。
从概念上讲,我们可以说,Lasso回归(L1)同时做变量选择和参数收缩,而ridge回归只做参数收缩,并最终在模型中包含所有的系数。在有相关变量时,ridge回归可能是首选。此外,ridge回归在用最小二乘估计有更高的偏差的情况下效果最好。因此,选择合适的模型取决于我们的模型的目标。
79、全球平均温度的上升导致世界各地的海盗数量减少。这是否意味着海盗的数量减少引起气候变化?
解析:
答:看完这个问题后,你应该知道这是一个“因果关系和相关性”的经典案例。我们不能断定海盗的数量减少是引起气候变化的原因,因为可能有其他因素(潜伏或混杂因素)影响了这一现象。全球平均温度和海盗数量之间有可能有相关性,但基于这些信息,我们不能说因为全球平均气温的上升而导致了海盗的消失。
注意:多了解关于因果关系和相关性的知识。
80、如何在一个数据集上选择重要的变量?给出解释。
解析:
答:以下是你可以使用的选择变量的方法:
1.选择重要的变量之前除去相关变量
2.用线性回归然后基于P值选择变量
3.使用前向选择,后向选择,逐步选择
4.使用随机森林和Xgboost,然后画出变量重要性图
5.使用lasso回归
6.测量可用的特征集的的信息增益,并相应地选择前n个特征量。
81、是否有可能捕获连续变量和分类变量之间的相关性?如果可以的话,怎样做?
解析:
是的,我们可以用ANCOVA(协方差分析)技术来捕获连续型变量和分类变量之间的相关性。
82、Gradient boosting算法(GBM)和随机森林都是基于树的算法,它们有什么区别?
解析:
答:最根本的区别是,随机森林算法使用bagging技术做出预测。 GBM采用boosting技术做预测。在bagging技术中,数据集用随机采样的方法被划分成使n个样本。然后,使用单一的学习算法,在所有样本上建模。接着利用投票或者求平均来组合所得到的预测。
Bagging是平行进行的。而boosting是在第一轮的预测之后,算法将分类出错的预测加高权重,使得它们可以在后续一轮中得到校正。这种给予分类出错的预测高权重的顺序过程持续进行,一直到达到停止标准为止。随机森林通过减少方差(主要方式)提高模型的精度。生成树之间是不相关的,以把方差的减少最大化。在另一方面,GBM提高了精度,同时减少了模型的偏差和方差。
注意:多了解关于基于树的建模知识。
83、运行二元分类树算法很容易,但是你知道一个树是如何做分割的吗,即树如何决定把哪些变量分到哪个根节点和后续节点上?
解析:
答:分类树利用基尼系数与节点熵来做决定。简而言之,树算法找到最好的可能特征,它可以将数据集分成最纯的可能子节点。树算法找到可以把数据集分成最纯净的可能的子节点的特征量。基尼系数是,如果总体是完全纯的,那么我们从总体中随机选择2个样本,而这2个样本肯定是同一类的而且它们是同类的概率也是1。我们可以用以下方法计算基尼系数:
1.利用成功和失败的概率的平方和(p^2+q^2)计算子节点的基尼系数
2.利用该分割的节点的加权基尼分数计算基尼系数以分割
熵是衡量信息不纯的一个标准(二分类):

这里的p和q是分别在该节点成功和失败的概率。当一个节点是均匀时熵为零。当2个类同时以50%对50%的概率出现在同一个节点上的时候,它是最大值。熵越低越好。
84、你已经建了一个有10000棵树的随机森林模型。在得到0.00的训练误差后,你非常高兴。但是,验证错误是34.23。到底是怎么回事?你还没有训练好你的模型吗?
解析:
答:该模型过度拟合。训练误差为0.00意味着分类器已在一定程度上模拟了训练数据,这样的分类器是不能用在未看见的数据上的。
因此,当该分类器用于未看见的样本上时,由于找不到已有的模式,就会返回的预测有很高的错误率。在随机森林算法中,用了多于需求个数的树时,这种情况会发生。因此,为了避免这些情况,我们要用交叉验证来调整树的数量。
85、你有一个数据集,变量个数p大于观察值个数n。为什么用OLS是一个不好的选择?用什么技术最好?为什么?
解析:
答:在这样的高维数据集中,我们不能用传统的回归技术,因为它们的假设往往不成立。当p>nN,我们不能计算唯一的最小二乘法系数估计,方差变成无穷大,因此OLS无法在此使用的。
为了应对这种情况,我们可以使用惩罚回归方法,如lasso、LARS、ridge,这些可以缩小系数以减少方差。准确地说,当最小二乘估计具有较高方差的时候,ridge回归最有效。
其他方法还包括子集回归、前向逐步回归。
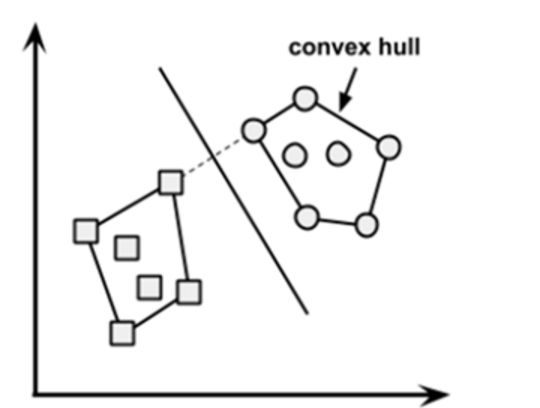
86、什么是凸包?(提示:想一想SVM) 其他方法还包括子集回归、前向逐步回归。
解析:
答:当数据是线性可分的,凸包就表示两个组数据点的外边界。
一旦凸包建立,我们得到的最大间隔超平面(MMH)作为两个凸包之间的垂直平分线。 MMH是能够最大限度地分开两个组的线。
87、我们知道,一位有效编码会增加数据集的维度。但是,标签编码不会。为什么?
解析:
答:对于这个问题不要太纠结。这只是在问这两者之间的区别。
用一位有效编码编码,数据集的维度(也即特征)增加是因为它为分类变量中存在的的每一级都创建了一个变量。例如:假设我们有一个变量“颜色”。这变量有3个层级,即红色、蓝色和绿色。
对“颜色”变量进行一位有效编码会生成含0和1值的Color.Red,Color.Blue和Color.Green 三个新变量。在标签编码中,分类变量的层级编码为0和1,因此不生成新变量。标签编码主要是用于二进制变量。
88、你会在时间序列数据集上使用什么交叉验证技术?是用k倍或LOOCV?
解析:
答:都不是。对于时间序列问题,k倍可能会很麻烦,因为第4年或第5年的一些模式有可能跟第3年的不同,而对数据集的重复采样会将分离这些趋势,我们可能最终是对过去几年的验证,这就不对了。
相反,我们可以采用如下所示的5倍正向链接策略:
fold 1 : training [1], test [2]
fold 2 : training [1 2], test [3]
fold 3 : training [1 2 3], test [4]
fold 4 : training [1 2 3 4], test [5]
fold 5 : training [1 2 3 4 5], test [6]
1,2,3,4,5,6代表的是年份。
89、给你一个缺失值多于30%的数据集?比方说,在50个变量中,有8个变量的缺失值都多于30%。你对此如何处理?
解析:
答:我们可以用下面的方法来处理:
1.把缺失值分成单独的一类,这些缺失值说不定会包含一些趋势信息。
2.我们可以毫无顾忌地删除它们。
3.或者,我们可以用目标变量来检查它们的分布,如果发现任何模式,我们将保留那些缺失值并给它们一个新的分类,同时删除其他缺失值。
90、买了这个的客户,也买了......”亚马逊的建议是哪种算法的结果?
解析:
答:这种推荐引擎的基本想法来自于协同过滤。
协同过滤算法考虑用于推荐项目的“用户行为”。它们利用的是其他用户的购买行为和针对商品的交易历史记录、评分、选择和购买信息。针对商品的其他用户的行为和偏好用来推荐项目(商品)给新用户。在这种情况下,项目(商品)的特征是未知的。
注意:了解更多关于推荐系统的知识。
91、你怎么理解第一类和第二类错误?
解析:
答:第一类错误是当原假设为真时,我们却拒绝了它,也被称为“假阳性”。第二类错误是当原假设为是假时,我们接受了它,也被称为“假阴性”。
在混淆矩阵里,我们可以说,当我们把一个值归为阳性(1)但其实它是阴性(0)时,发生第一类错误。而当我们把一个值归为阴性(0)但其实它是阳性(1)时,发生了第二类错误。
92、当你在解决一个分类问题时,出于验证的目的,你已经将训练集随机抽样地分成训练集和验证集。你对你的模型能在未看见的数据上有好的表现非常有信心,因为你的验证精度高。但是,在得到很差的精度后,你大失所望。什么地方出了错?
解析:
答:在做分类问题时,我们应该使用分层抽样而不是随机抽样。随机抽样不考虑目标类别的比例。相反,分层抽样有助于保持目标变量在所得分布样本中的分布。
93、请简单阐述下决策树、回归、SVM、神经网络等算法各自的优缺点?
正则化算法(Regularization Algorithms)
集成算法(Ensemble Algorithms)
决策树算法(Decision Tree Algorithm)
回归(Regression)
人工神经网络(Artificial Neural Network)
深度学习(Deep Learning)
支持向量机(Support Vector Machine)
降维算法(Dimensionality Reduction Algorithms)
聚类算法(Clustering Algorithms)
基于实例的算法(Instance-based Algorithms)
贝叶斯算法(Bayesian Algorithms)
关联规则学习算法(Association Rule Learning Algorithms)
图模型(Graphical Models)
解析:
一、正则化算法(Regularization Algorithms)
它是另一种方法(通常是回归方法)的拓展,这种方法会基于模型复杂性对其进行惩罚,它喜欢相对简单能够更好的泛化的模型。
例子: 岭回归(Ridge Regression) 最小绝对收缩与选择算子(LASSO) GLASSO 弹性网络(Elastic Net)
最小角回归(Least-Angle Regression)
优点: 其惩罚会减少过拟合 总会有解决方法
缺点: 惩罚会造成欠拟合 很难校准
本题完整解析:七月在线官网 → 面试题库 → 面试大题 → 机器学习(124题),或七月在线APP → 题库 → 面试大题 → 机器学习(124题)
94、在应用机器学习算法之前纠正和清理数据的步骤是什么?
解析:
1.将数据导入
2.看数据:重点看元数据,即对字段解释、数据来源等信息;导入数据后,提取部分数据进行查看
3.缺失值清洗
- 根据需要对缺失值进行处理,可以删除数据或填充数据
- 重新取数:如果某些非常重要的字段缺失,需要和负责采集数据的人沟通,是否可以再获得
4.数据格式清洗:统一数据的时间、日期、全半角等显示格式
5.逻辑错误的数据
- 重复的数据
- 不合理的值
6.不一致错误的处理:指对矛盾内容的修正,最常见的如身份证号和出生年月日不对应 不同业务中数据清洗的任务略有不同,比如数据有不同来源的话,数据格式清洗和不一致错误的处理就尤为突出。数据预处理是数据类岗位工作内容中重要的部分。
95、什么是K-means聚类算法?
解析:
本题解析作者:JerryLead
来源:https://www.cnblogs.com/jerrylead/
K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般。最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中,那本书比较注重应用。看了Andrew Ng的这个讲义后才有些明白K-means后面包含的EM思想。
聚类属于无监督学习,以往的回归、朴素贝叶斯、SVM等都是有类别标签y的,也就是说样例中已经给出了样例的分类。而聚类的样本中却没有给定y,只有特征x,比如假设宇宙中的星星可以表示成三维空间中的点集。聚类的目的是找到每个样本x潜在的类别y,并将同类别y的样本x放在一起。比如上面的星星,聚类后结果是一个个星团,星团里面的点相互距离比较近,星团间的星星距离就比较远了。
本题完整解析:七月在线官网 → 面试题库 → 面试大题 → 机器学习(126题),或七月在线APP → 题库 → 面试大题 → 机器学习(126题)
96、请详细说说文字特征提取
解析:
很多机器学习问题涉及自然语言处理(NLP),必然要处理文字信息。文字必须转换成可以量化的特征向量。下面我们就来介绍最常用的文字表示方法:词库模型(Bag-of-words model)。
词库表示法
词库模型是文字模型化的最常用方法。对于一个文档(document),忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文档中每个词的出现都是独立的,不依赖于其他词是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。词库模型可以看成是独热编码的一种扩展,它为每个单词设值一个特征值。词库模型依据是用类似单词的文章意思也差不多。词库模型可以通过有限的编码信息实现有效的文档分类和检索。
本题完整解析:七月在线官网 → 面试题库 → 面试大题 → 机器学习(128题),或七月在线APP → 题库 → 面试大题 → 机器学习(128题)
97、请详细说说图像特征提取
解析:
计算机视觉是一门研究如何使机器“看”的科学,让计算机学会处理和理解图像。这门学问有时需要借助机器学习。
本节介绍一些机器学习在计算机视觉领域应用的基础技术。通过像素值提取特征数字图像通常是一张光栅图或像素图,将颜色映射到网格坐标里。一张图片可以看成是一个每个元素都是颜色值的矩阵。表示图像基本特征就是将矩阵每行连起来变成一个行向量。
光学文字识别(Optical character recognition,OCR)是机器学习的经典问题。下面我们用这个技术来识别手写数字。
本题完整解析:七月在线官网 → 面试题库 → 面试大题 → 机器学习(129题),或七月在线APP → 题库 → 面试大题 → 机器学习(129题)
98、了解xgboost么,请详细说说它的原理
解析:
前言 xgboost一直在竞赛江湖里被传为神器,比如时不时某个kaggle/天池比赛中,某人用xgboost于千军万马中斩获冠军。
而我们的机器学习课程里也必讲xgboost,如寒所说:“RF和GBDT是工业界大爱的模型,Xgboost 是大杀器包裹,Kaggle各种Top排行榜曾一度呈现Xgboost一统江湖的局面,另外某次滴滴比赛第一名的改进也少不了Xgboost的功劳”。
此外,公司七月在线从2016年上半年起,就开始组织学员参加各种比赛,以在实际竞赛项目中成长(毕竟,搞AI不可能没实战,而参加比赛历经数据处理、特征选择、模型调优、代码调参,是一个极好的真刀真枪的实战机会,对能力的提升和找/换工作的帮助都非常大)。
AI大潮之下,今年特别多从传统IT转行转岗转型AI的朋友,很多朋友都咨询如何转行AI,我一般都会着重强调学习AI或找/换AI的四大金刚:课程 + 题库 + OJ + kaggle/天池。包括集训营的毕业考核更会融合kaggle或天池比赛。
本题完整解析:七月在线官网 → 面试题库 → 面试大题 → 机器学习(130题),或七月在线APP → 题库 → 面试大题 → 机器学习(130题)
99、请详细说说梯度提升树(GBDT)的原理
解析:
本文是小编我能找到的对GBDT最通俗的介绍了。
GBDT主要由三个概念组成:Regression Decistion Tree(即DT),Gradient Boosting(即GB),Shrinkage (算法的一个重要演进分枝,目前大部分源码都按该版本实现)。搞定这三个概念后就能明白GBDT是如何工作的,要继续理解它如何用于搜索排序则需要额外理解RankNet概念,之后便功德圆满。下文将逐个碎片介绍,最终把整张图拼出来。
一、 DT:回归树 Regression Decision Tree 提起决策树(DT, Decision Tree) 绝大部分人首先想到的就是C4.5分类决策树。但如果一开始就把GBDT中的树想成分类树,那就是一条歪路走到黑,一路各种坑,最终摔得都要咯血了还是一头雾水。但,这说的就是LZ自己啊有木有。咳嗯,所以说千万不要以为GBDT是很多棵分类树。
本题完整解析:七月在线官网 → 面试题库 → 面试大题 → 机器学习(131题),或七月在线APP → 题库 → 面试大题 → 机器学习(131题)
100、请说说Adaboost 算法的原理与推导
解析:
本题解析来源于July在CSDN上的Adaboost笔记《Adaboost 算法的原理与推导》:https://blog.csdn.net/v_july_v/article/details/40718799
0 引言
一直想写Adaboost来着,但迟迟未能动笔。其算法思想虽然简单:听取多人意见,最后综合决策,但一般书上对其算法的流程描述实在是过于晦涩。昨日11月1日下午,在我组织的机器学习班 第8次课上讲决策树与Adaboost,其中,Adaboost讲得酣畅淋漓,讲完后,我知道,可以写本篇博客了。
无心啰嗦,本文结合机器学习班决策树与Adaboost 的PPT,跟邹讲Adaboost指数损失函数推导的PPT(第85~第98页)、以及李航的《统计学习方法》等参考资料写就,可以定义为一篇课程笔记、读书笔记或学习心得,有何问题或意见,欢迎于本文评论下随时不吝指出,thanks。
本题完整解析:七月在线官网 → 面试题库 → 面试大题 → 机器学习(132题),或七月在线APP → 题库 → 面试大题 → 机器学习(132题)
题目来源:七月在线官网(www.julyedu.com)——面试题库——面试大题——机器学习,或是下载七月在线APP在线刷题。
以上就是整理的100道机器学习面试题,如果还不够,上七月在线APP,将近4000道题的等你来刷
最后,祝愿大家都能找到心仪的工作,拿到高薪offer ~


今日学习推荐
【机器学习集训营第八期】
火热报名中
2019年4月15日开课
前50人特惠价:14399
报名加送18VIP[包2018全年在线课程和全年GPU]
且两人及两人以上组团还能各减500元
有意的亲们抓紧时间喽
咨询/报名/组团可添加微信客服
julyedukefu_02
扫描下方二维码
免费试听
☟

长按识别二维码


●励志!充满干货的AI面经:纯电力员工如何成功转行NLP并薪资翻倍
点
咨询,查看课程,请点击“阅读原文”