推荐算法注意点和DeepFM工程化实现


缘起
DeepFM 算法介绍详见 [1],在 DeepFM 工程化的时候,遇到了特征稀疏、一列多值和共享权重的情况,主要参考石塔西的实现。那我为什么要继续炒冷饭呢?因为石塔西实现的 TensorFlow 框架用的是高阶 api,显得灵活性低一些。

项目背景
推荐模式

算法架构
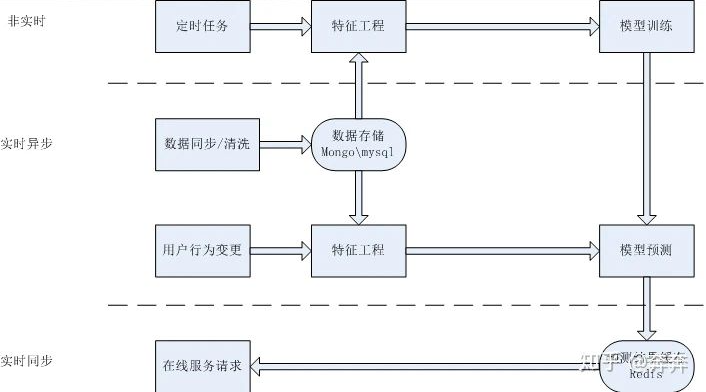
▲ 工程架构

样本

▲ 一条请求数据返回的样本列表点击情况

特征工程

DeepFM
原文采用 tf_utils.to_sparse_input_and_drop_ignore_values(dense_Xs[k]) 将稠密文件矩阵转成稀疏矩阵。按照输出的格式采用 sparse_element(下面代码中有)方法和 tf.compat.v1.SparseTensorValue 构建起一行一行的读入方式便于线上实时预测使用:
class FeaturePredictV2(object):
@classmethod
def sparse_element(cls,suffix, flag, max_tokens):
#构造稀疏特征,按照行处理成需要的格式
values_lst = []
indices_lst = []
row_length = len(suffix)
for i in range(row_length):
for j in range(len(suffix[i])):
values_lst.append(suffix[i][j])
indices_lst.append([i, j])
indices = np.array(indices_lst, dtype=np.int)
values = np.array(values_lst, dtype=np.int32) if flag else np.array(values_lst, dtype=np.float32)
dense_shape = np.array([row_length, max_tokens])
return [indices, values, dense_shape]
@classmethod
def get_processed_data(cls,data_pre):
#数据读入并处理
X = {}
name_list = [t[0] for t in COLUMNS_MAX_TOKENS]
df = pd.DataFrame(data_pre, columns=name_list)
for colname, max_tokens in COLUMNS_MAX_TOKENS:
kvpairs = [i.split(",")[:max_tokens] for i in df[colname]]
ids = []
vals = []
for lines in kvpairs:
id = []
val = []
try:
for line in lines:
splited = line.split(":")
id.append(splited[0])
val.append(splited[1])
except Exception as err:
print('get_processed_data error {}'.format(sys.exc_info()))
print(err)
traceback.print_exc()
ids.append(id)
vals.append(val)
ids_elements = cls.sparse_element(ids, 1, max_tokens)
vals_elements = cls.sparse_element(vals, 0, max_tokens)
X[colname + "_ids"] = tf.compat.v1.SparseTensorValue(ids_elements[0], ids_elements[1], ids_elements[2])
X[colname + "_values"] = tf.compat.v1.SparseTensorValue(vals_elements[0], vals_elements[1], vals_elements[2])
return X
if __name__ == '__main__':
data_pre = []
with open('data/train/train_st.dat') as f:
for line in f.readlines()[:3]:
line_list = line.split(" ")[1:]
processed_line = [i.rstrip("\n") for i in line_list]
# print(processed_line)
data_pre.append(processed_line)
print(FeaturePredictV2.get_processed_data(data_pre))模型训练部分保存 auc 最高的部分:主要是构图和保存模型两段代码。
构图部分如下,将原代码中高阶 API 的核心部分用低阶 API 重新写成,将 sess、init、features、labels、train_graph、cost、predictions、embedding_table 灵活提取出来,可以供整个过程的使用。
def build_model(self, params):
"""
构图
:param name:
:param params:
:return:
"""
train_graph = tf.Graph()
with train_graph.as_default():
features = {}
for c, max_tokens in COLUMNS_MAX_TOKENS:
features[c + "_ids"] = tf.compat.v1.sparse_placeholder(tf.int32, shape=[None, max_tokens])
features[c + "_values"] = tf.compat.v1.sparse_placeholder(tf.float32, shape=[None, max_tokens])
labels = tf.compat.v1.placeholder(tf.int32, shape=[None, 1])
x = tf.compat.v1.placeholder(tf.int32)
y = tf.compat.v1.placeholder(tf.int32)
for featname, featvalues in features.items():
if not isinstance(featvalues, tf.SparseTensor):
raise TypeError("feature[{}] isn't SparseTensor".format(featname))
embedding_table = self.build_embedding_table(params)
linear_logits = self.output_logits_from_linear(features, embedding_table, params)
bi_interact_logits, fields_embeddings = self.output_logits_from_bi_interaction(features, embedding_table,
params)
dnn_logits = tf.cond(tf.less(x, y), lambda: self.f1(fields_embeddings, params),
lambda: self.f2(fields_embeddings, params))
general_bias = tf.compat.v1.get_variable(name='general_bias', shape=[1], initializer=tf.constant_initializer(0.0))
# logits = linear_logits + bi_interact_logits
logits = linear_logits + bi_interact_logits + dnn_logits
logits = tf.nn.bias_add(logits, general_bias) # bias_add,获取broadcasting的便利
# del features
logits = tf.reshape(logits, shape=[-1])
predictions = tf.sigmoid(logits)
labels = tf.cast(labels, tf.float32)
labels = tf.reshape(labels, shape=[-1])
cost = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels))
optimizer = params['optimizer'].minimize(cost, global_step=tf.compat.v1.train.get_global_step())
# auc =tf.compat.v1.metrics.auc(labels, predictions)
sess = tf.compat.v1.Session(graph=train_graph)
init = tf.group(tf.compat.v1.global_variables_initializer(), tf.compat.v1.local_variables_initializer())
return Struct(sess=sess, init=init, features=features, labels=labels, train_graph=train_graph, cost=cost,
predictions=predictions, x=x, y=y,
optimizer=optimizer, embedding_table=embedding_table) def train(self, train_data, test_data, save_path=model_dir):
train_len_data = len(train_data)
train_total_batch = train_len_data // self.batch_size
print("train_data length:{},toal_batch of training data:{}".format(train_len_data, train_total_batch))
test_len_data = len(test_data)
test_total_batch = test_len_data // self.batch_size
print("test_data length:{},toal_batch of testing data:{}".format(test_len_data, test_total_batch))
self.model = self.build_model(self.param)
self.model.sess.run(self.model.init)
max_score = 0.0
fl_train = Feature_load(self.train_eval, self.num_epochs, self.batch_size, self.train_shuffle)
train_input = fl_train.input_fn(train_data)
fl_eval = Feature_load(self.train_eval, self.num_epochs, self.batch_size, self.test_shuffle)
test_input = fl_eval.input_fn(test_data)
for epoch in range(self.num_epochs):
loss_static = []
all_predictions=[]
all_labels=[]
for i in range(train_total_batch):
train_feed_dict = self.get_input_data(train_input, True)
# loss, _ = self.model.sess.run([self.model.cost, self.model.optimizer], feed_dict=train_feed_dict)
loss, _,predictions,labels = self.model.sess.run([self.model.cost, self.model.optimizer, self.model.predictions,self.model.labels],
feed_dict=train_feed_dict)
# print(auc)
loss_static.append(loss)
all_predictions.extend(predictions)
all_labels.extend(labels)
avg_loss = float(sum(loss_static)) / len(loss_static)
r = EvaMgr(['AUC'])
test_auc_entity=r.evaluate(all_labels,all_predictions)
test_auc =test_auc_entity['AUC']
print("Epoch:{}/{}".format(epoch, self.num_epochs),
"Train loss:{:.3f} Train AUC:{:.3f}".format(avg_loss,test_auc))
eva, avg_test_loss = self.evaluate(test_total_batch, test_input, ['AUC', 'Acc', 'NE'])
score = eva['AUC']
print("Epoch:{}/{} Test loss:{:.3f} Test AUC: {:.3f}".format(epoch, self.num_epochs, avg_test_loss, score))
print(eva)
if score > max_score:
max_score = score
print('saving model,acc:' + str(score))
if not os.path.exists(save_path):
os.mkdir(save_path)
self.save(saved_model)以上的三段代码还需要其他才能跑起来,读者可以自行构造一些数据并结合石塔西公开的代码,由于公司限制不能公开全部代码,但是把主要的思路和改造部分贴了出来,供大家参考。

重排序

探索位

线上下线一致性验证
2. 在线指标需要积累一定的数据才能统计,此时才发现问题,实际上有 bug 的代码已经运行了一段时间。
2. 在上线之前,分别使用离线部分和在线部分的代码对相同的样本进行预测,如果样本的浮点数得分完全相同(小数点后若干位),则可以认为在线部分没有 bug。

评价指标
2. 平均点击率 UV = 总点击 UV/总展示 UV
3. 平均点击数 = 总点击 PV/总展示 UV
4. 平均观看时长 = 总播放时长/播放 UV

效果
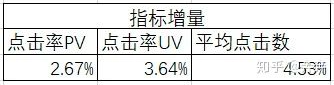
▲ 点击率增量指标

深入一步

参考文献
[3] https://zhuanlan.zhihu.com/p/48057256
[4] https://zhuanlan.zhihu.com/p/183760759
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





