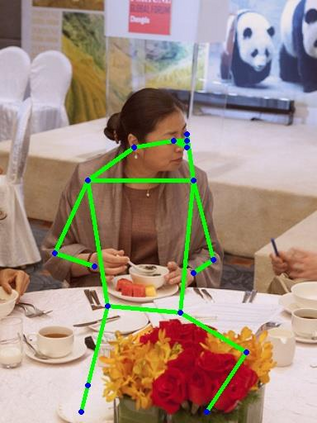
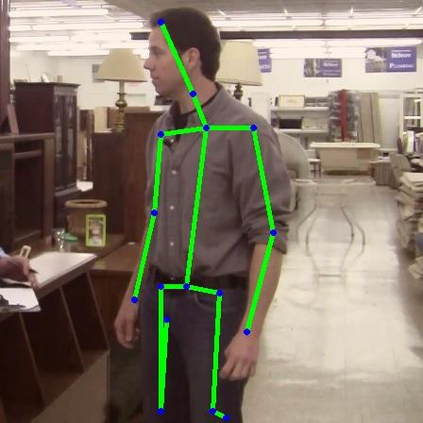
Human pose estimation - the process of recognizing human keypoints in a given image - is one of the most important tasks in computer vision and has a wide range of applications including movement diagnostics, surveillance, or self-driving vehicle. The accuracy of human keypoint prediction is increasingly improved thanks to the burgeoning development of deep learning. Most existing methods solved human pose estimation by generating heatmaps in which the ith heatmap indicates the location confidence of the ith keypoint. In this paper, we introduce novel network structures referred to as multiresolution representation learning for human keypoint prediction. At different resolutions in the learning process, our networks branch off and use extra layers to learn heatmap generation. We firstly consider the architectures for generating the multiresolution heatmaps after obtaining the lowest-resolution feature maps. Our second approach allows learning during the process of feature extraction in which the heatmaps are generated at each resolution of the feature extractor. The first and second approaches are referred to as multi-resolution heatmap learning and multi-resolution feature map learning respectively. Our architectures are simple yet effective, achieving good performance. We conducted experiments on two common benchmarks for human pose estimation: MS-COCO and MPII dataset.
翻译:人类表面估计——在给定图像中确认人类关键点的过程——是计算机视觉中最重要的任务之一,具有广泛的应用,包括运动诊断、监视或自驾车辆等,人类关键点预测的准确性由于深层次学习的迅速发展而日益提高。大多数现有方法通过产生热映射,使Ith热映射显示Ith关键点的位置信任度,解决了人类关键点的估计。在本文件中,我们引入了被称为“多分辨率代表学习”的新网络结构,以用于人类关键点预测。在学习过程中的不同决议中,我们的网络分支关闭,使用额外的层学习热映射生成。我们首先考虑在获得最低分辨率特征图后生成多分辨率热映射的架构。我们的第二个方法允许在地貌提取过程中学习,在地貌提取的每一次分辨率图中生成热映射图。第一和第二方法分别称为“多分辨率热映射学习”和多分辨率特征图学习。我们的架构简单而有效,实现了良好的性能。我们首先考虑在获得最低分辨率特征图后生成多分辨率色谱数据的两个共同基准:MS-CO。