怎样从零开始训练一个AI车手?
允中 发自 凹非寺
量子位 | 公众号 QbitAI
△这篇文章我们做了一期b站视频,欢迎三连~
如何快速理解强化学习的概念?
驯只猫就行。
比如下面这位爷,巨皮。

整天就是跑酷、尿炕、抓沙发,搞到人头皮发麻、心态爆炸。
直到你忍不了了,决定对它进行残酷的猫德教育。方案是:
以后在家,每当它表现出一次守猫德的行为,就奖励一根猫条;
而每当它皮一次,你就立刻扑过去,咬它的头……

这样反复拉扯两个月之后,你的猫再也不敢皮了——
这个过程里发生的事情,就是“强化学习”:
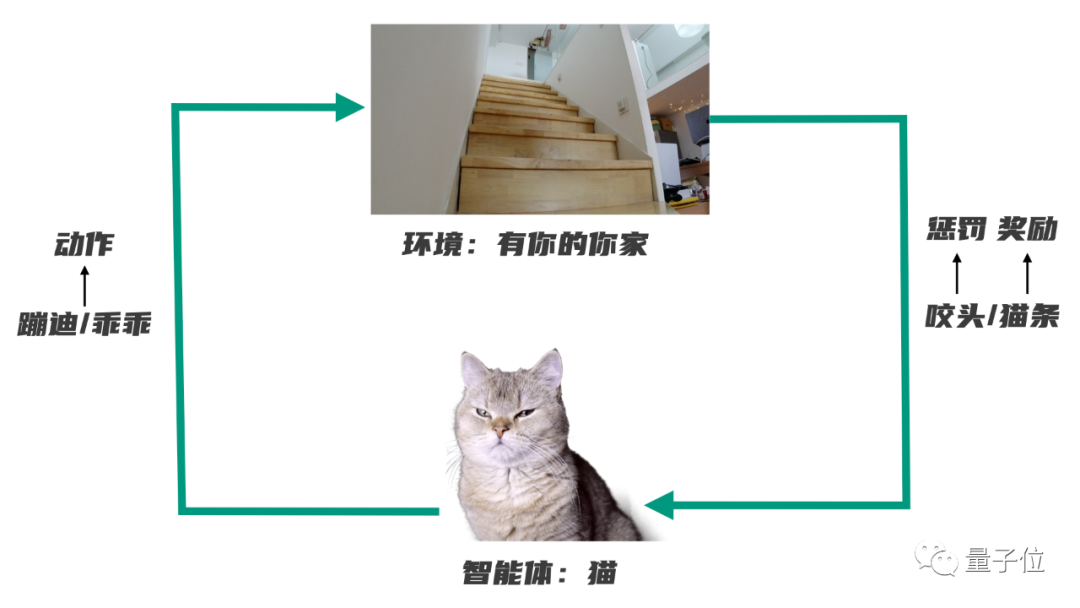
一个智能体(你的猫)在与环境(有你的你家)互动的过程中,在奖励(猫条)和惩罚(咬头)机制的刺激下,逐渐学会了一套能够最大化自身收益的行为模式(安静,躺平)。
所以其实,养猫跟搞人工智能,道理是一样的。

强化学习最著名的代表当然是AlphaGo:几万盘棋,左右互搏,最后无师自通成了独步天下的围棋之神。
如果把AlphaGo看作上面例子里的猫,那在训练里,决定它能否获得“猫条”的每盘棋最终的对弈结果——赢了就有好东西吃,输了就要被吃(bushi)。
另外,DeepMind开发出过一个能在57款雅达利游戏上都超越人类玩家的智能体,背后依靠的同样是强化学习算法。
不过这里的奖励和惩罚机制就要根据不同的游戏来具体设计了。比如玩最简单的吃豆人,就可以对每次吃到豆子的行为进行奖励,对撞到幽灵gg的状况给予惩罚。
而除了在游戏领域天空海阔之外,强化学习,其实还能拿来搞自动驾驶。
如何训练AI司机
为了更方便地说明这件事怎么实现,这里我们借用一个道具:来自亚马逊云科技的Amazon DeepRacer。

一辆看上去很概念的小车,跟真车的比例是1比18。车上安装了处理器、摄像头,甚至还可以配置激光雷达,为的就是实现自动驾驶——
当然,前提就是我们先在车上部署训练好的强化学习算法。
算法的训练需要在虚拟环境中进行,为此Amazon DeepRacer配套了一个管理控制台,里面包含一个3D赛车模拟器,能让人更直观地看到模型的训练效果。
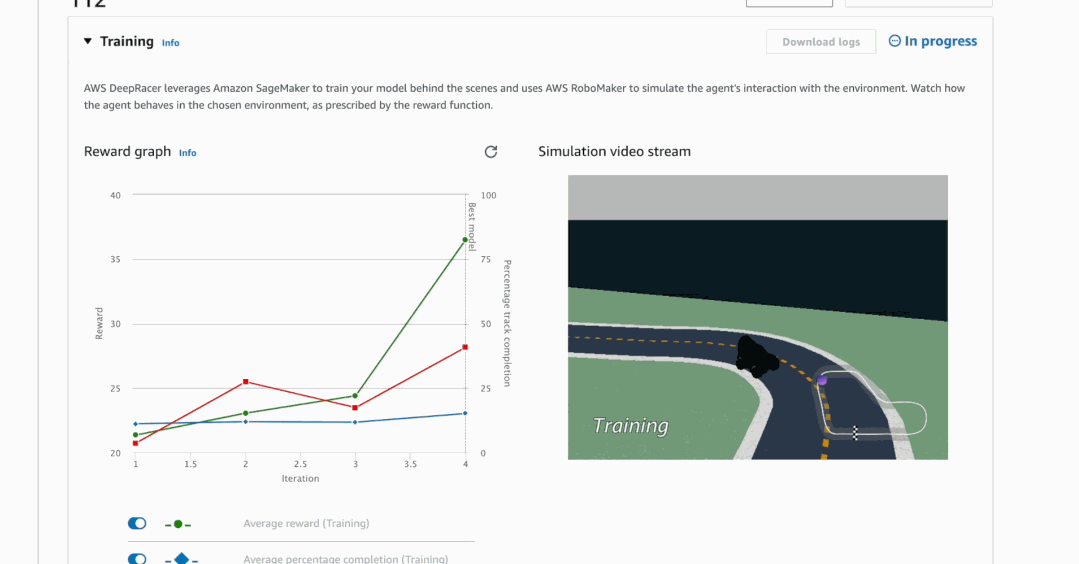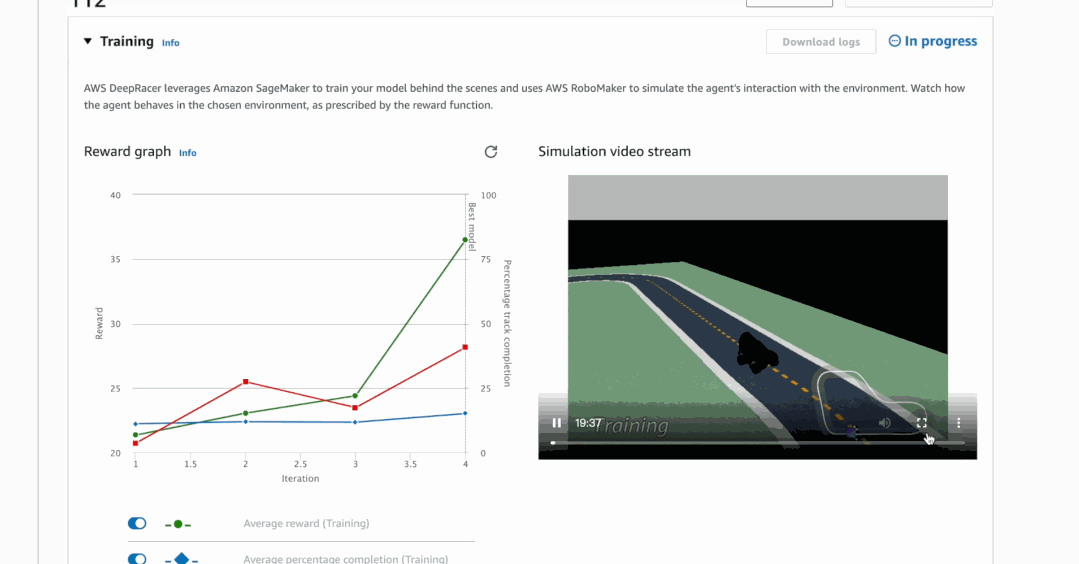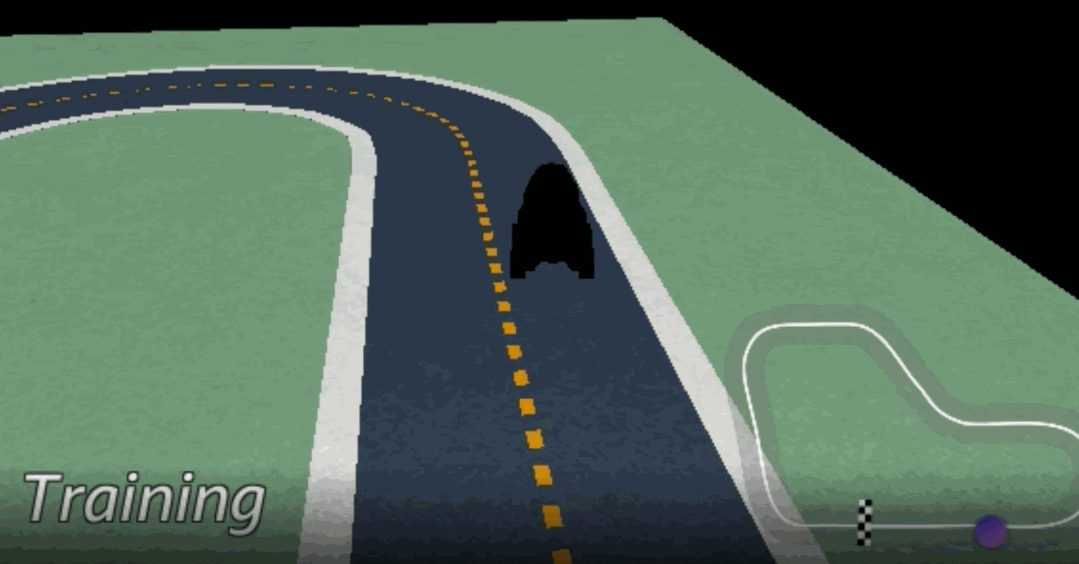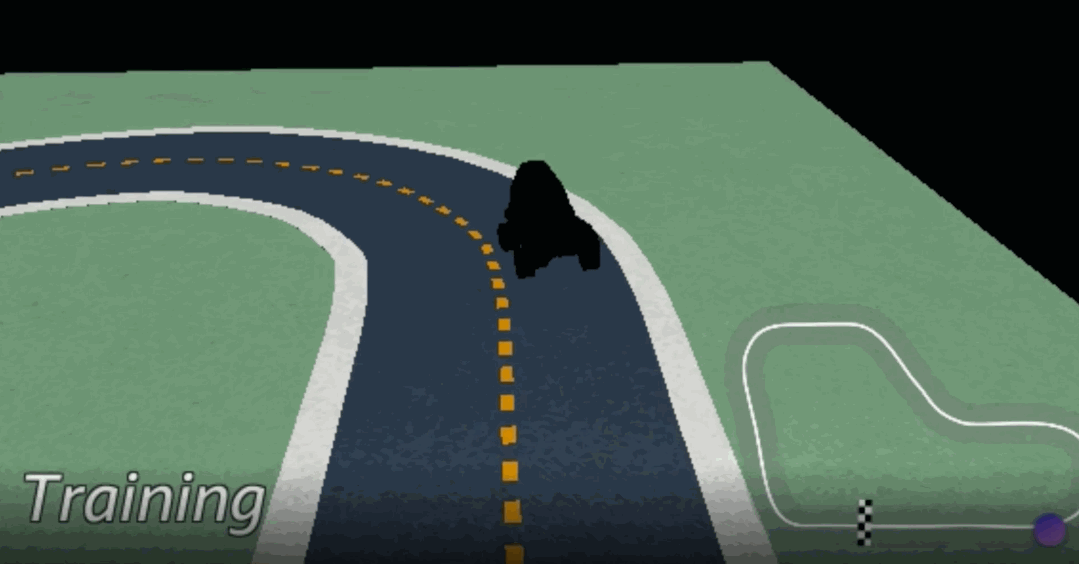
有了这套东西,我们就能自己尝试从零开始训练一个AI司机。
具体怎么做呢?重点来了:
假设这是模拟器里的一条完全笔直的赛道,以及虚拟环境里的Amazon DeepRacer赛车。

我们的目标是让赛车以最短的时间冲刺到终点——那么对于这条赛道而言,最好的选择就是让车尽量沿着中线跑,避免因绕路或出界而导致增加时长。
为此,我们可以把赛道切分成多个网格,然后给这些网格赋予不同的分数:

靠近中间的,给更高的分;在两侧的,稍微意思一下;超出赛道范围的部分属于无效区域,如果碰到,就要从头再来。
开跑之后,一开始,赛车并不知道哪一条是最佳路线,只是在像无头苍蝇一样四处乱撞,很多时候还会冲出赛道。

但后面,随着试错的次数越来越多,在奖励函数的“指挥”下,赛车会逐渐探索出一条能够获得最高累积分数的路线。
理想状况下,一段时间的训练、迭代之后,算法就会学会“直线”最快这条真理。

而再把算法部署到车上,我们就能收获一辆会跑直线的赛车。
当然跑直线只是一种最简单的情形,实际的赛道一般都更加复杂,很多时候沿中心线跑也并不是最快的路线,为此我们就需要调整训练的策略和奖励函数的设计。
实际操作中,具体函数的编写同样通过Amazon DeepRacer的管理控制台完成。
在写函数之前,我们可以在上面调整模型的超参数,然后定义它的行动空间,规定赛车行驶的速度和转向时的角度,甚至……还能选择赛车的皮肤,等等。
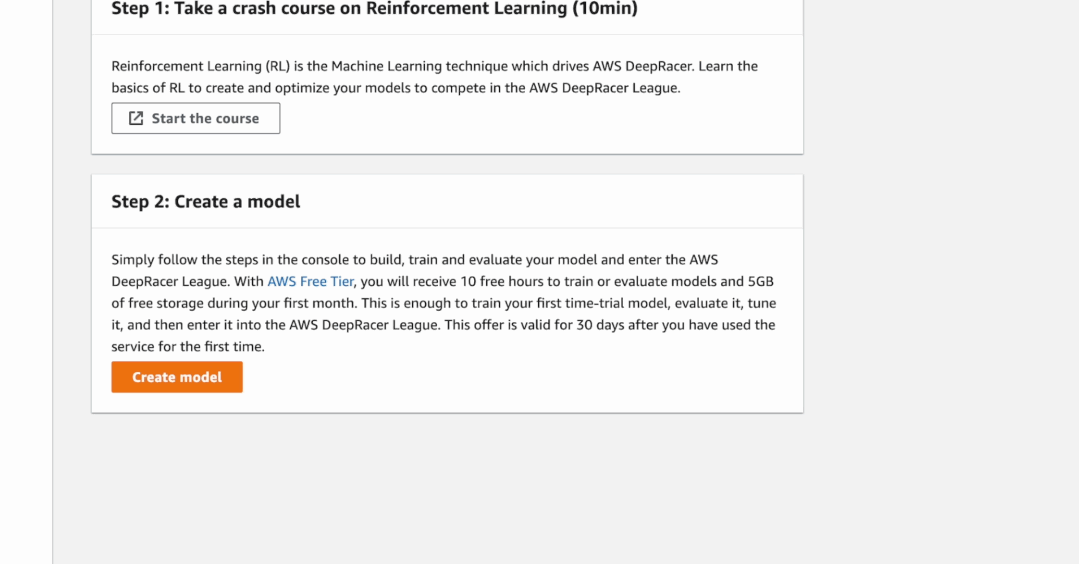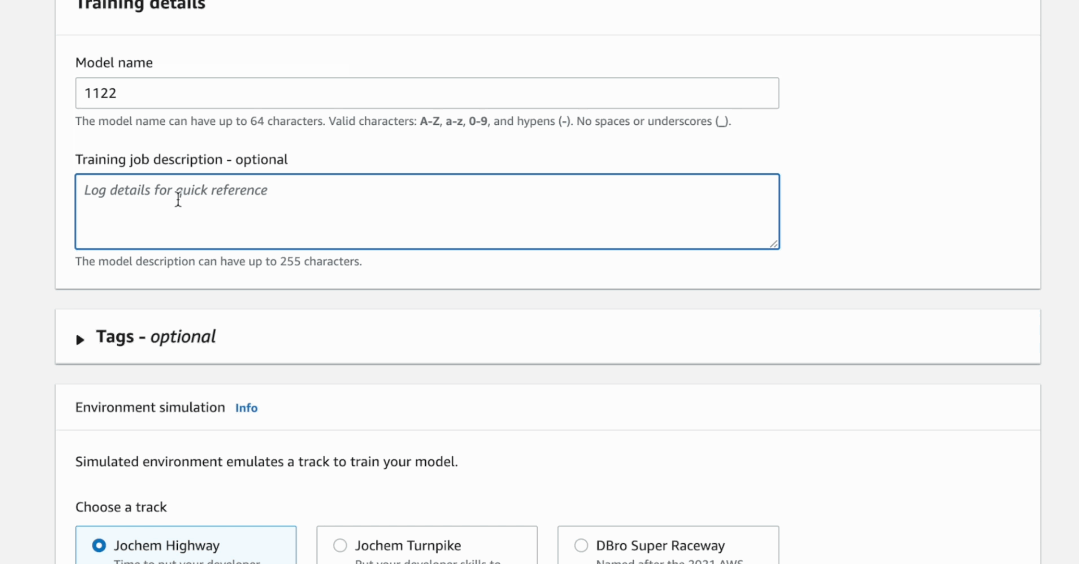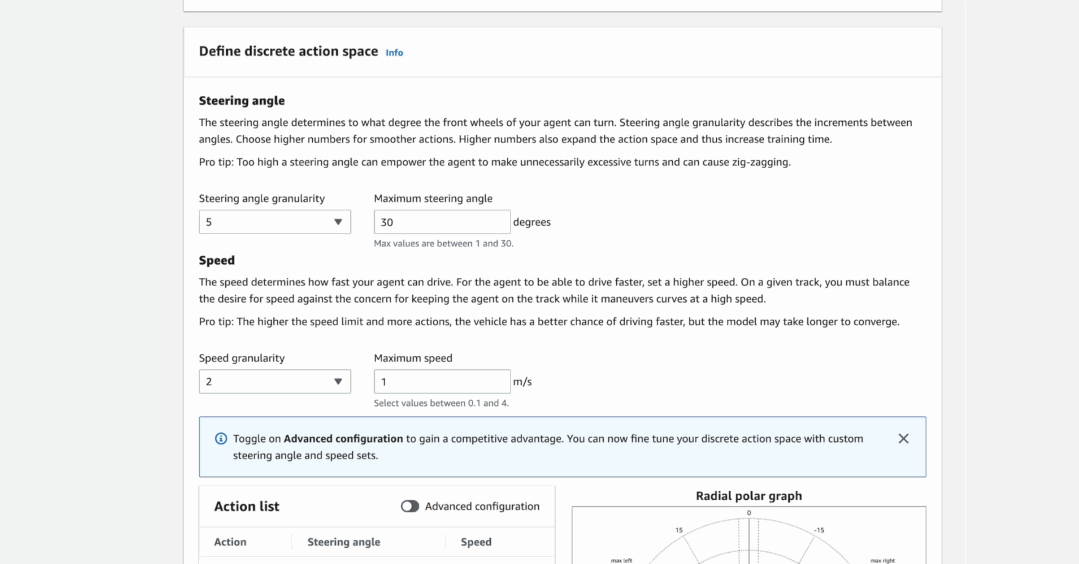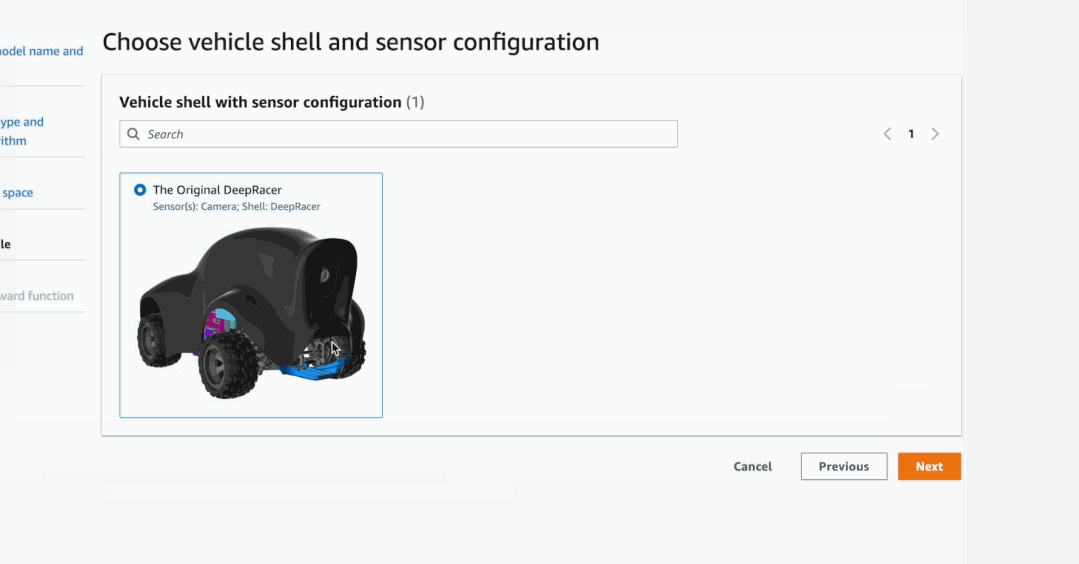
Amazon DeepRacer这一整套服务,蛮像一套入门强化学习的可视化教学工具,新手跟着提示也能一步步做下来,大家如果有兴趣,不妨自己试试。
挑战吉尼斯?
当然,既然说了是赛车,自然要追求速度,越快越好。
而如果你想测试一下,自己“培养”出来的AI司机到底够不够快的话……
亚马逊云科技官方还搞了比赛,让把大家训练的AI司机全都拉出来,比一比,看看谁才是真正的秋名山车神。

这个联赛是一个全球范围内的正经比赛。18年开始办第一届,办到现在,总共有超过10万人参加。从线上模拟到线下实体比赛,都有。
比赛在全球的机器学习开发者圈子里已颇有名气。去年,还跟F1搞过联名,喊来了当时雷诺车队的车手里卡多,跟大伙一块开车。
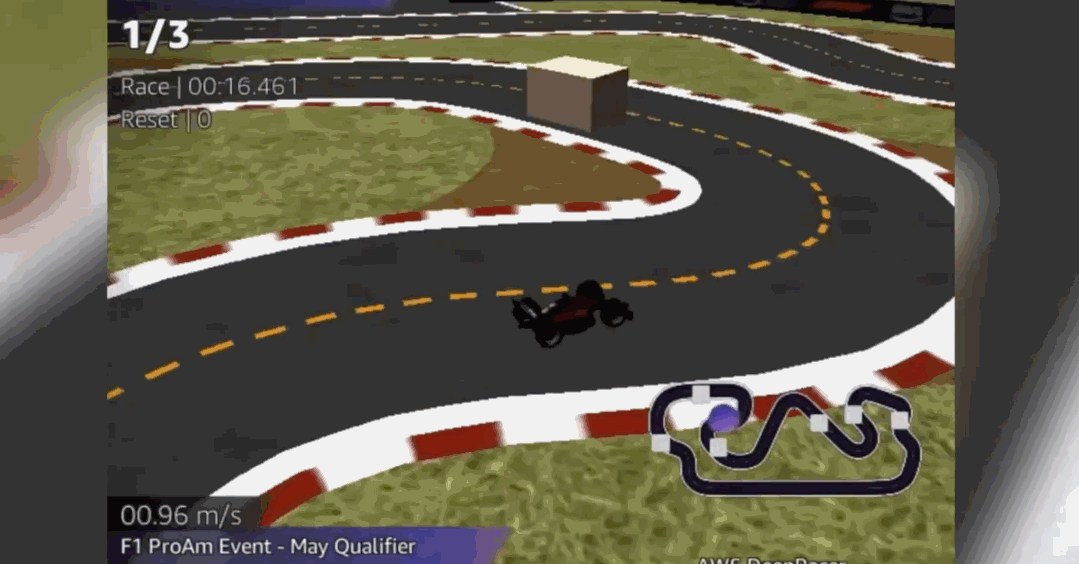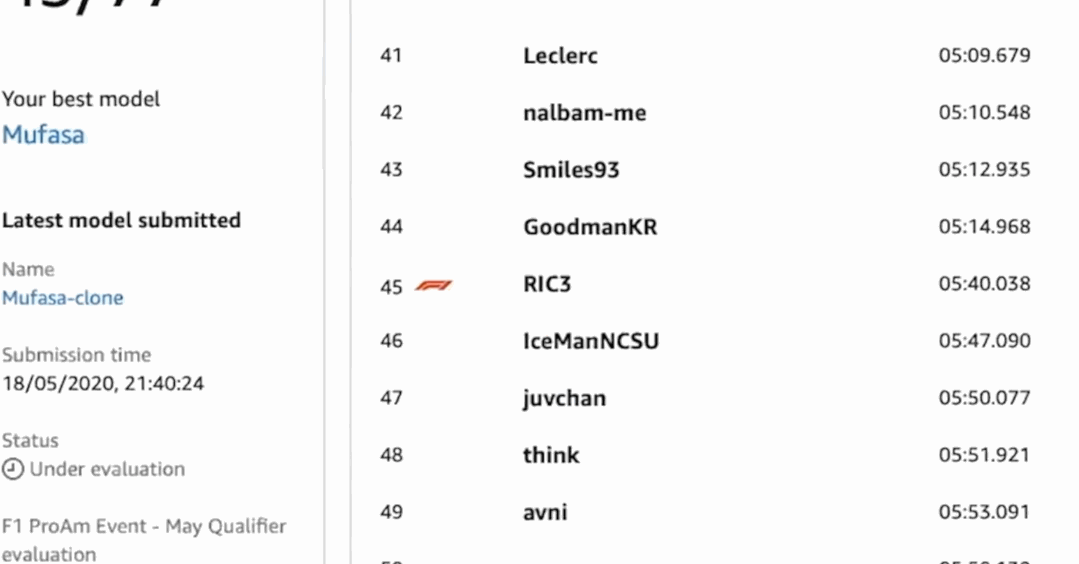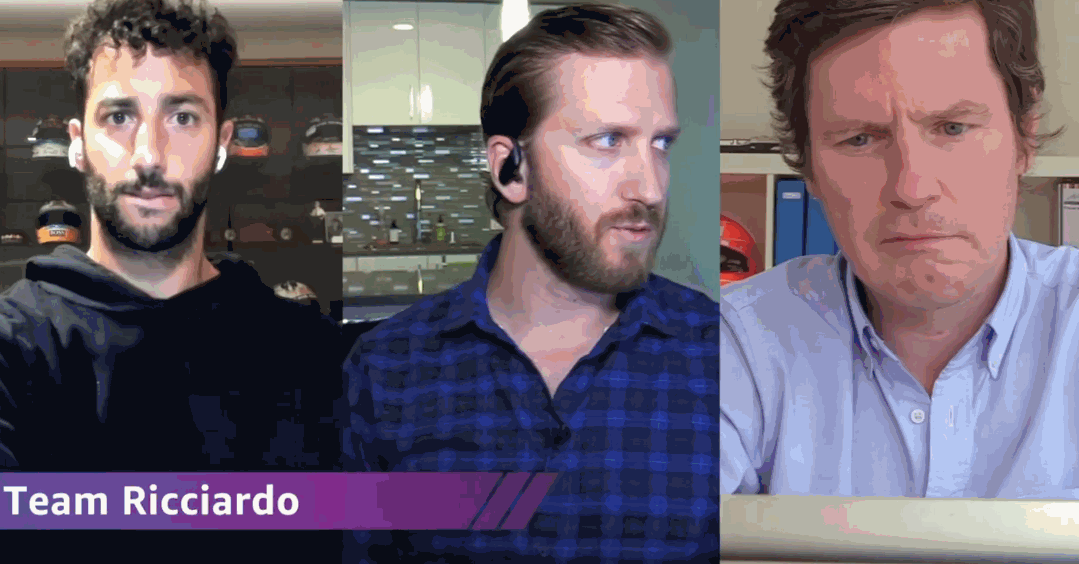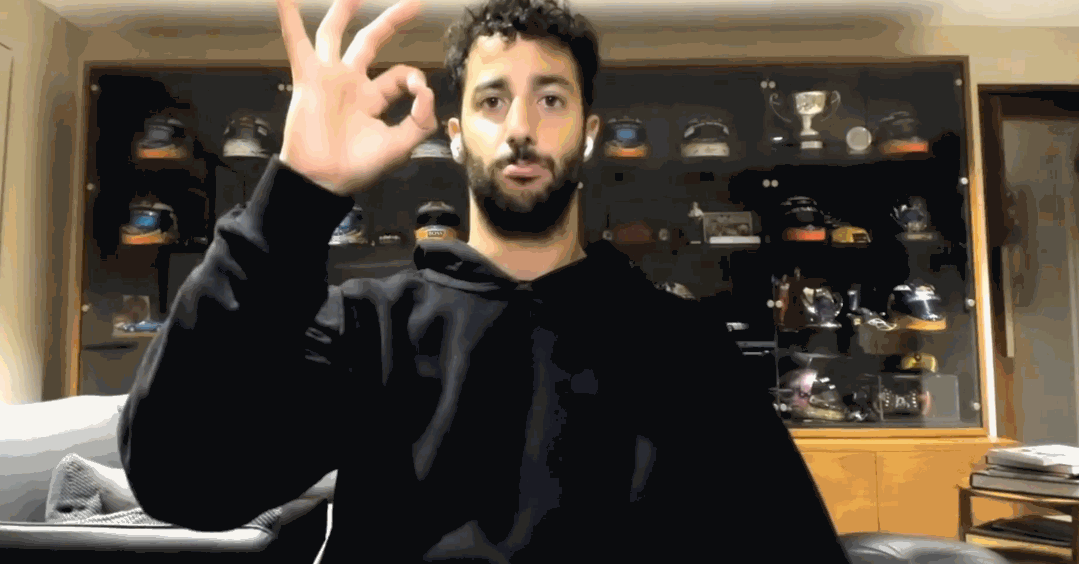
而中国区也为中国的开发者建立了专门的Amazon DeepRacer联赛。
今年中国区联赛分为了两个赛季,每个赛季的月赛根据赛道的难易程度和模型训练难度的不同,分成了大众组和专业组。月赛组别排名靠前的选手,会有机会晋级到下一组别或参加线下比赛。

当然,比赛都有奖品。耳机、键盘、音箱……什么乱七八糟的都有;
而如果你一不小心拿了个赛季总冠军的话,那恭喜你,你可以白嫖一张去拉斯维加斯的机票(还有酒店、大会门票)。
Amazon DeepRacer联赛的报名是免费的,也没有职业要求。只不过如果你没满16周岁就来卷,就得需要监护人允许了……
今年的比赛还在进行中,现在在官网上注册了账号,就会自动获得亚马逊云服务上10个小时的训练时间,并且可以申请价值30美元的“点卡”。
与之同时,亚马逊云科技官方还在搞一个“挑战吉尼斯世界纪录”的活动,目标是突破4387这个参赛人数数字,申请成为全世界“最大规模的机器学习竞赛”。

今年的每个参赛选手都会成为纪录的一部分——甚至,每人都有机会得到一张吉尼斯世界纪录的挑战证书。
至于这次挑战的最终结果,会在十月份公布。
到时,今年的亚马逊云科技线上中国峰会将在10月开启,会上除了公布Amazon DeepRacer吉尼斯挑战结果,还会有云计算领域的众多大咖做分享,以及相关的技术成果展示。
目前,线上峰会已经开启报名,海报和链接在此:

报名链接(或点击阅读原文):
https://summit.awsevents.cn/2022/signin?source=gh/ZsR4xii4TX2Vs20QVMuBJ8myz/eb2C54wsCCG96M=&tab=1&type=2
— 完 —
点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~



