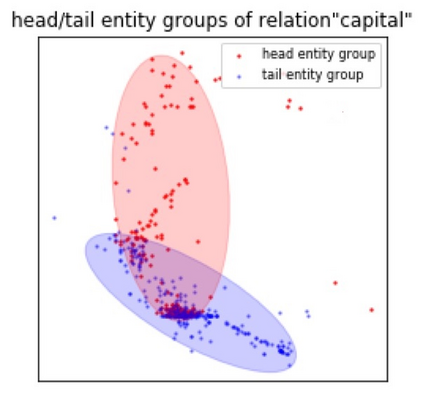
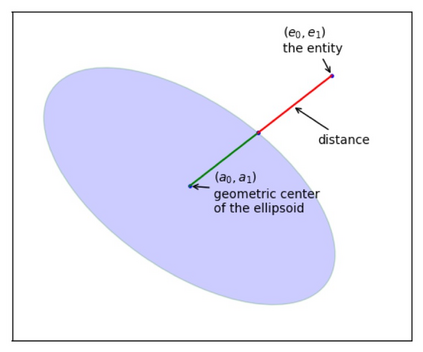
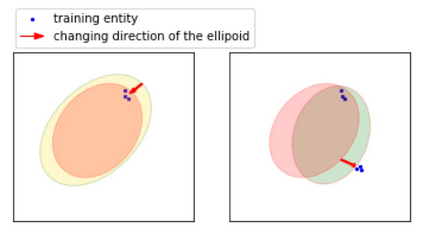
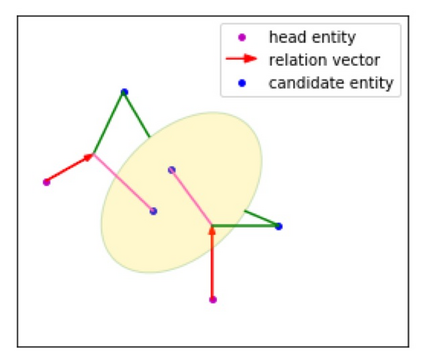
Embedding entities and relations into a continuous multi-dimensional vector space have become the dominant method for knowledge graph embedding in representation learning. However, most existing models ignore to represent hierarchical knowledge, such as the similarities and dissimilarities of entities in one domain. We proposed to learn a Domain Representations over existing knowledge graph embedding models, such that entities that have similar attributes are organized into the same domain. Such hierarchical knowledge of domains can give further evidence in link prediction. Experimental results show that domain embeddings give a significant improvement over the most recent state-of-art baseline knowledge graph embedding models.
翻译:将实体和关系嵌入一个连续的多维矢量空间已成为在代表性学习中嵌入知识图集的主要方法,但是,大多数现有模型忽略了等级知识,例如一个领域的实体的相似性和差异性。我们提议在现有知识图集嵌入模型上学习域表,这样,具有类似属性的实体就被组织到同一领域。这种对域的等级知识可以在链接预测中提供进一步的证据。实验结果表明,域图嵌入比最新的最先进的基线知识图嵌入模型有显著改进。