ECCV2022 Oral|CLIFF : 人体模型重建的新范式

极市导读
华为诺亚提出的刷榜3维人体重建领域的工作CLIFF,在 AGORA 排行榜(SMPL 算法赛道)上排名第一,来看看其精妙之处究竟何在! >>10月份视觉AI工程项目实训周已经开始招募!全程实战技术指导,算法实战+导师实时答疑+结营证书,添加小助手(cvmart8)报名参加。
论文链接:https://arxiv.org/abs/2208.00571
代码地址:https://github.com/huawei-noah/noah-research/tree/master/CLIFF
就在前两天,3维人体领域刷榜的的CLIFF(Carrying Location Information in Full Frames)在arxiv上放出了文章。作为ECCV今年的Oral文章,华为诺亚方舟实验室的这项工作用简答优雅的思路取得了相当好的效果,在各个3D人体数据集上都名列榜首,甚至胜过第二名不少。下面是github上放出来的演示动画:

人体模型即使被重映射回原图片,整体的动作和行为也显得十分流畅自然。这是如何实现的呢?下面就来领略一下这篇文章的魅力究竟在哪里吧。
一,研究动机
一个好的研究动机对文章的创新性有着举足轻重的影响。如果它能够发现前人所未发现的问题,并从该问题切入,提出行之有效的解决办法,那么这样的文章大多是有其价值所在的。CLIFF就从计算摄影学的角度,向人体三维重建领域提出了一个不容忽视的问题:三维人体的朝向到底怎么确定?如图,在下面的这个场景中,如果采用惯用的Top-Down算法,截取出人体周围(Bounding Box)回归后,该怎么判断人体的朝向的偏移角?
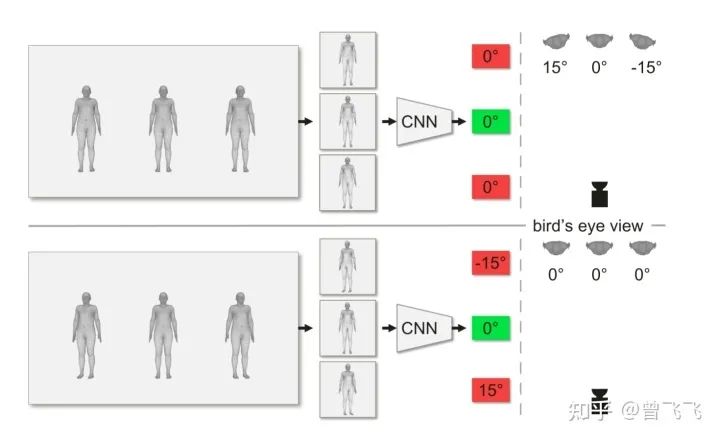
具体来说,上面那张图中假设的是左右的人体在三维世界中相对中心的人体有15°左右的偏移(注意看右上角的俯视图),但由于两个人站在相机的两翼上,因此照片的拍摄角度都是沿着相机为中心的半径方向。也就是说,图片上拎出单个人体来看,他们单独拍出来好像都是各自正对相机的。所以3个bounding box内的结果经过CNN回归后,偏移角回归出来都会是0°,这就和真实世界的15°偏移角产生了偏差。对应的,下面这张图三个人的朝向都是一致的(注意看右下角的俯视图),但因为左右两个人的朝向并不是沿着半径方向,所以拍出来的图片中单独看上去会朝外歪出去15°。所以Top-Down办法单独截取出人体的bounding box后,后续的流程并不知道这个bounding box是在原图的哪个位置截取出来的,只能根据截取出的图片本身不完整的信息,判断出左右两个人各自有15°的偏向角。这也和真实世界会产生偏差。一言以概之,就是说:
在三维世界映射到二维的时候,相机拍摄出来的物体朝向会向外侧扭曲,扭曲的程度则由物体在画面上的相对位置决定。
而Top-Down办法将每个人体单独用Bounding Box框出来后,回归时不知道其在原图片的哪个位置上,因此对物体的扭曲程度也就无从判断(Agnostic)了。这种对全局信息的无知显然是不利于回归的。
二,问题解决
明确了要解决的问题后,作者给出的解决思路也是相当简洁而优雅的。不是缺少全局信息吗?好,那我一方面在输入里就额外加上全局信息,另一方面损失函数再强迫模型学到全局信息,不就解决这个问题了吗?
模型整体的思路框架依然遵循2017年的经典框架HMR,为了更清楚地了解到CLIFF做出的改进,这里也简单提一下HMR的大概思路。

简单来说, HMR就是先截取出人体的Bounding Box, 再用某个CNN的backbone加以回归(比如 Resnet)。回归出人体的SMPL参数 后, 就可以计算第一个Loss, 即SMPL参数Loss:
用SMPL参数很容易能回归出人体Mesh面的顶点坐标V, V再简单处理一下就得到了人体的三维关节点坐标 , 这样就能计算第二个Loss, 即3维关节点Loss:
最后, HMR backbone的全连接层同时还会输出3D坐标到2D坐标的转换系数, 分别是横轴、纵轴偏移 以及缩放系数 。拿到了这三个量, 我们就能把3D的坐标映射回2D了。具体来说, 对于每一个关节点的3D坐标 ,能写出对应的2D坐标: ,其中 是刚刚回归出来的偏移量, 用初中基本的几何光学和相似三角形知识就可以求出, 表达式为 。表达式中的2来自于bounding box 的实际高度 (因为人的高度取1.8m),224为bounding box处理后的像素高度224pixel, 为相机焦距, 为回归出的图像缩放系数。这个式子长得就是个相似三角形的模样, 实际上也很好推导, 感兴趣的可以自己画一下摄影的光学图算一算。这样, 最后一个2D坐标的Loss也就能求出来了:
这就是HMR的全部思路啦,是不是很简单。其中最值得注意的是最后一项 代表的是关节点在bounding box裁剪出来的局部图片上的位置,而不是关节点在原始图片上的2D坐标位置。而CLIFF更需要的是全局信息的监督,所以在这一个上损失函数会和HMR有所区别。
现在说完HMR, 那CLIFF做出了那些改变呢?刚刚也说了,为了解决人体朝向的扭曲问题,一方面CLIFF会在输入里就额外加上全局信息。左下角的黄色框框里就是新增的输入 ,分别代表bounding box的中心横坐标,中心纵坐标,以及box的正方形边长,具体语义在左边的full image中也有标注。这样就相当于给了模型一个关于图片全局的位置信息,方便模型判断朝向的扭曲程度。
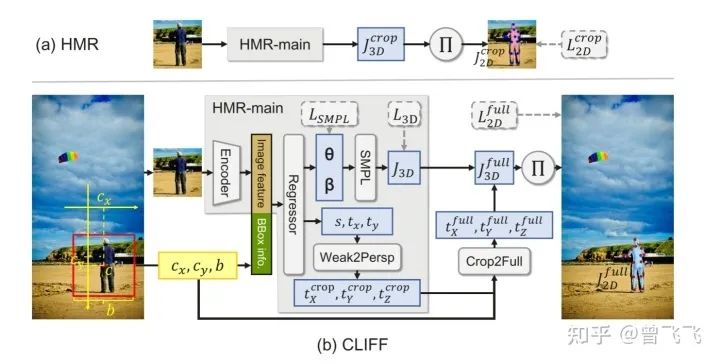
另一方面, 除了输入全局信息以外, CLIFF也设置了损失函数再去强迫模型掌握全局信息。具体来说就是右上角的 取代了原先HMR的最后一个损失函数 。刚刚也强调过, HMR监督的 代表的是关节点在裁剪后图片上的位置, 那么对应的, CLIFF监督的 就是关节点在原始图片 (full image) 上的位置。模型为了缩小这一项损失函数, 必须掌握图片的全局信息, 这样才能准确无误地将局部的裁剪图片映射回原始图片。具体实现的过程就是在重映射回full image的时候由相机内参和网络中回归出的局部偏移量 , 求解出全局的偏移量 , 再用损失函数 监督全局信息的学习, 这就能够让模型更好地掌握全局信息。
三,最终效果
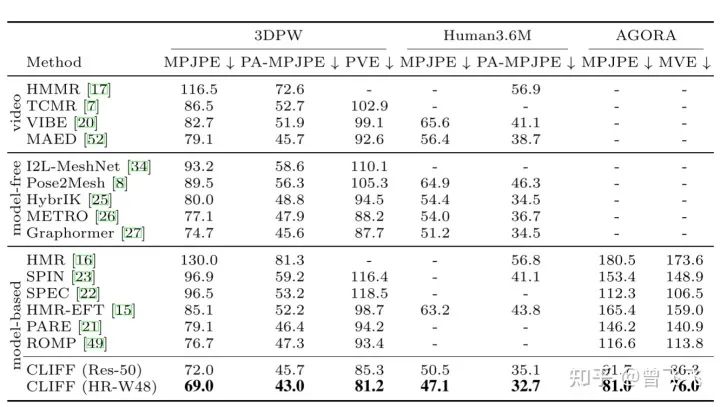
最后的最后,简单讲讲CLIFF的结果吧。其在几个主要的3D人体数据集上都取得相当不错的效果。而Ablation Study on Human3.6m则显示出上面两个创新点各自的benefit主要在哪里:
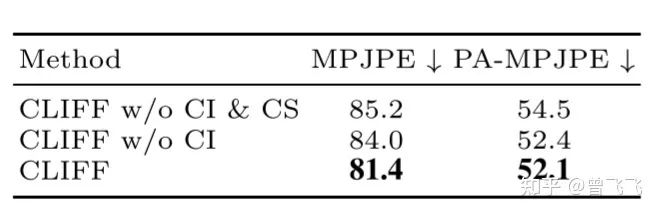
CI代表的是CLIFF input,就是我们上面介绍的第一个改动。可以看出,将全局信息作为模型的输入后,模型的PA-MPJPE(代表关节局部误差,不考虑全局的缩放旋转等因素)有了明显的下降,这是因为模型的输入更丰富,考虑了全局的信息,可以更准确地估计人体特征。而CS代表CLIFF Supervision,就是我们介绍的第二个改动 。该项损失函数加入后降低了模型的MPJPE误差(考虑缩放旋转等因素地全局误差)。这是因为模型显式地被要求掌握全局的知识,因此全局误差有了比较大的下降。
四,小结
华为的这篇工作刷新了多个榜单的SOTA,因此绝对是值得一读的。不过,CLIFF能取得如此好的成绩,也离不开其对数据集的扩充,也就是文中提到的制作伪监督数据集。这方面的工作可以参考Facebook的开山之作EFT(https://link.zhihu.com/?target=https%3A//github.com/facebookresearch/eft),CLIFF几乎没有对其做出太多理论上的改进,所以本篇文章也就不将其纳入文章创新点的介绍啦。如果有同学希望介绍的话可以留言一下,抽空我也把EFT的介绍写掉。
最后的最后,码字不易,喜欢的话可以点个赞或者收藏,作者会很开心的。后续作者也会更新更多关于姿态动作领域的内容,感兴趣的话也可以关注一下哦~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
极市&深大CV技术交流群已创建,欢迎深大校友加入,在群内自由交流学术心得,分享学术讯息,共建良好的技术交流氛围。
“
点击阅读原文进入CV社区
收获更多技术干货


