地表最强的GPT-3,是在推理,还是胡言乱语?

来源:AI TIME 论道
GPT-3发布以来,衍生了翻译、答题、创作小说、数据分析、数学推理、玩游戏、画图表、制作简历等诸多玩法。深度学习之父Geoffrey Hinton表示“从GPT-3惊人的性能可以推测生命、宇宙和万物的答案只是4万亿个参数而已”。纽约大学教授Gary Marcus与Ernest Davis联手在《麻省理工科技评论》发表题为《傲慢自大的 GPT-3:自己都不知道自己在说什么》的文章,一起讨论GPT-3。
那么,GPT-3 的本质是什么?GPT-3将带来哪些冲击与影响……为了探寻本质、扫清迷雾,AI TIME特别邀请学术界与产业界的大佬,于11月26日14:00在1911餐厅相聚,一起论道GPT-3的希望和局限。

本次活动邀请了京东AI研究院常务副院长何晓冬;北京大学研究员、博士生导师严睿;清华大学计算机系副教授黄民烈、清华大学计算机系副教授刘知远;百度杰出架构师、百度文心(ERNIE)负责人孙宇;CCF YOCSEF学术委员会委员、智源研究院学术秘书李文珏;AI TIME负责人何芸。

一、 GPT-3的本质
为什么一个语言模型能够同时完成阅读理解、自动问答、机器翻译、算术运算和代码生成等多种任务?
这是GPT-3一直坚持的哲学思想:将所有自然语言处理的任务转换为语言模型任务,也就是对所有任务进行统一建模,将任务描述与任务输入视为语言模型的历史上下文,而输出则为语言模型需要预测的未来信息。如下图所示,无论是做情感分类、自动问答,还是完成算术运算、机器翻译任务,都可以形式化为语言生成问题。
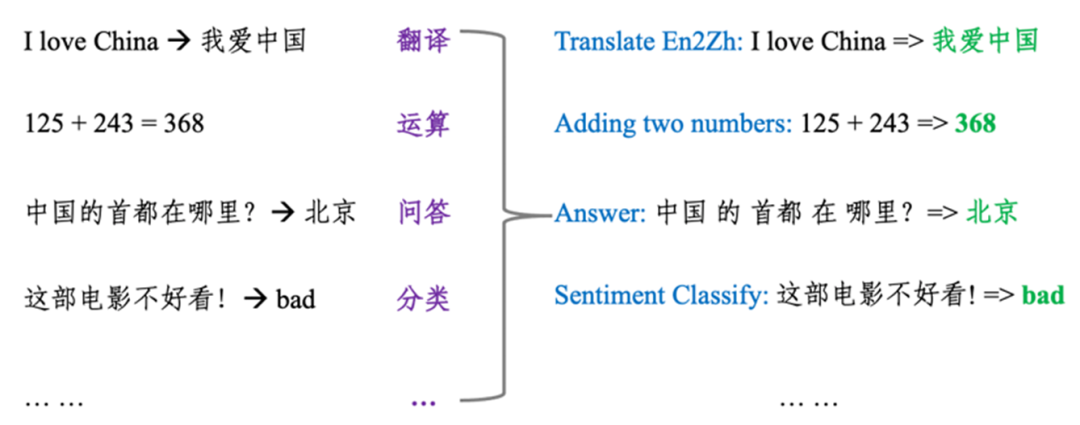
GPT-3是单纯的暴力美学,还是真的会给AI带来新的变化,给NLP领域带来质变呢?
GPT-3的本质是大数据,基于Transformer这样的模型。它是革命性的成就,展现了算法+工程的美学。宏观来看,科学技术的演进遵循“艺术→科学→大规模的、稳定的、可增长的工程实践”的发展路径,而GPT-3在某种程度上展现了AI工程取得突破的希望,将推动AI领域的工程化,加速AI整体的发展,给社会带来积极影响。何晓冬首先表述了自己对GPT-3和NLP的观点。
GPT-3的本质是一个概率模型,是条件、概率的关联,距离非常基础地解决NLP问题还有非常遥远的距离,距离理解也还存在距离。黄民烈从理解的角度剖析了GPT-3的本质。
GPT-3和之前的预训练模型最大的不同在于不再需要微调,只需非常少的样例就可以完成相应的任务。刘知远认为GPT-3会给整个研究领域带来非常多新的灵感。
GPT-3本质是在大规模数据下通过大算力做出来的一个概率语言模型。它是非常大的突破,是质变的东西,GPT-3通过弱监督、自监督的方法学习海量的数据,摆脱了之前专家系统、机器学习系统、深度学习系统对人工知识、人工标注数据的依赖,但是离解决AI问题还有很长的路要走。孙宇从GPT-3的特点及其对NLP和AI的价值做了解释。
GPT-3进步的本质可能源于它“见多识广”。正因为它见得多,所以能够基于关联预测、判断的也更多。但它不对自己的判断负责,也不能对它所说内容的实质有任何的判断。因而说GPT-3是量变而不是质变。不过,量变过程让我们看到 “模型越大,能力会更接近人”这条康庄大道还没走到头,没有看到新的瓶颈。严睿从GPT-3与人类视野的角度进行了解析。
二、 GPT-3的应用、产业前景
GPT-3在翻译、答题、创作小说、与人对话、生成代码等方面展现出了非常好的效果。在未来,GPT-3对AI应用的范式将产生哪些影响?对产业将带来哪些帮助?
如果中文有这么一个模型的话,可以做非常多的事情,届时,只要能够在相应的领域里做一些必要的适配,就可以完成创作小说、答题、进行对话等任务。刘知远提出不仅可以关注预训练模型如何让自然语言理解效果更好,还可以多关注GPT-3等模型的广阔应用前景。
GPT-3最大的问题是“它不知道它知道什么,它也不知道它不知道什么”。黄民烈首先指出GPT-3的局限性,他比较看好GPT-3在内容创作中的应用,但他认为它不太擅长逻辑推理。
GPT-3做内容创作很有产业前景,但不能放心地让它去做推理,因为模型本身有缺陷。虽然存在问题,但何晓冬认为GPT-3有希望在很多地方进行提升。如果AI是一台车,GPT-3可以作为这台车的底盘,虽然很不完美,没有“变速箱”也没有“方向盘”,但有了这个底盘后,其余的内容是可以逐步添上去的。如果能把符号推理装在GPT-3这个底盘上,再做一些融合性的工作,将会带来下一个震惊世界的里程碑。
很长时间以来NLP都是在为各条技术线做支撑,但是现在的NLP仍然缺乏直接面向终端用户进行价值输出的工具,而GPT-3提供了这样一种形式。严睿认为把NLP的能力、AI的能力开放给更多的终端用户进行再加工、再创造,或者直接开放给用户去使用也许是一种新的产业形态。
首先,问答可能就是搜索引擎的下一代。GPT-3有可能成为下一代基于问答的搜索引擎的基础。其次,GPT-3可以革新一些情感陪伴产品,如智能音箱等。再次,如果NLP支持的规模做到足够大,带来的价值和意义足够大,也会有很大的商业价值。孙宇认为当下NLP技术在产业里落地还不是非常好,主要的原因在于NLP的技术不是那么标准化,各个行业的人如果没有AI背景很难使用AI技术。有了预训练模型以后,可能只需要针对各个应用场景提供少量的领域知识、领域数据,就可以解决具体的AI问题。GPT-3为NLP技术在产业中标准化落地提供了一个非常大的可能性,降低了NLP技术的使用门槛,对于推进产业的智能化变革非常有帮助。
三、 GPT-3将走向何方
目前,GPT-3确实取得了长足进展,但也存在缺陷和问题,发展面对着挑战和风险。此外, GPT-3在解决中文问题上也存在不足。面对上述问题,我们该如何去应对?
刘知远认为以GPT-3为代表的预训练模型的科研和商业需求很大,要探索和解决的问题也很多。一方面,中文的自然语言处理性能需要有大模型的支持,这个无论是在商业上还是在研究上都有类似的需求,特别是前沿研究无法避开预训练模型开展研究。同时,以GPT-3为代表的预训练模型已经发展到一定规模,大部分研究组的算力资源很难维持计算需求。如果没有一个面向中文的高质量预训练模型作为基础,会极大地影响国内自然语言处理前沿研究的开展,因此亟需国内商业机构或公益组织开源发布或共享中文预训练模型。
GPT-3是算法?是资源?何晓冬首先提出了这个观念上的问题:如果把GPT-3看作是资源,应该把它的API放到网上,让所有研究者都可以用,这对工业界可能有价值;如果把GPT-3当作算法或学术论文,可以在上面做更多的迭代,像使用BERT一样重新训练模型。
针对何晓冬的问题,刘知远以使用Google Translate的API辅助做一些跨语言问答任务为例引入,指出GPT-3意味着NLP研究需要从单机单卡时代跨越到多机多卡时代。
孙宇以从小模型上创新的方法到大模型上的迁移性为切入点,对是否一定要在1730亿参数这样的规模上做实验、做分析表示了不同看法,并担心研究方向会被带偏,基于GPT-3这么大的模型进行创新、实验会非常影响研究的速度。
做研究到底做什么?黄民烈提到了在情感领域的SentiLARE模型上的工作,并指出要聚焦在解决问题上,一个新的趋势是不要为了去刷SOTA而工作,SOTA只是一个方面。还谈了自己在清源CPM中遇到的处理中文的两个问题:
第一个问题:中文的数据不足,主要体现在:中文数据很脏;中文的数据量不大且很难获取;中文数据的多样性很差。
第二个问题:中文确实有一些特点,包括在建模上也不能完全照搬英文的那一套。在中文上还是有很多值得去做的工作,做清源CPM也是想去尝试解决这样一些问题,尤其在数据、模型等方面做一些尝试。
GPT-3和预训练模型在工业界和学术界都已经是不可忽视的现象级存在。严睿从学术界角度提出:学校的服务器和计算资源都有限,有各种条件的限制,很难在每一个工作上都去使用大模型和大数据,能够在一个小的领域里翩翩起舞是研究者应有的素质。在低资源的、小数据、算力不足的情况下仍然能够使方法、性能或结果有提升是很重要的。希望未来会有越来越多人抛开成见,去判断更深层次的想法有没有本质改变。
针对严睿的观点,刘知远提到预训练模型是大势所趋,并以机器翻译在国内的发展为例进行了剖析。假如小而美的模型无法融入预训练模型这种主流框架, 那么它的价值会大打折扣。
基于刘知远的观点,严睿进一步分析指出需要找到研究的出路,即要找出一个场景来说这个工作有价值,而不是根据是否应用了预训练模型而一概而论。
黄民烈补充到:场景和评价是紧密相关的,大家都在刷Benchmark的数据集,不停地拟合数据集,而不是真正地解决任务,这是不好的。目前,大家已经在做一些改变了,今年ACL的最佳论文等都是评价相关的,这说明大家也在思考这个事情,数据集上的SOTA并不是那么重要,而要思考模型真正的泛化性、鲁棒性,以及模型真正的能力在哪里。
对学生来说,论文进不进ACL是个灵魂的问题,但成熟的学者要求应该更高一点。何晓冬首先指出了学生与学者在学术生涯的不同阶段的不同要求,进而指出好的工作一般都能超过一个合格水平,不会处在一个有争议的水平区间,不用太纠结。他相信整个学术社区还会继续往上走,很多新的思想都还会起来。
严睿表示预训练、GPT-3及相关趋势是可行的,自己想呼吁的只是不要因为没有用GPT-3而否定了工作的价值,也不要因为采用了预训练及GPT-3就认为结果的提升来自大数据和大模型。应该客观来看工作成果在某种场景、社区是否存在贡献,而这个贡献的评判其实是综合的、全方位的,不是只看指标。
四、 算力是否是最有效的方法?
GPT-3出现以后,国际上也出现了比较多的争论,牛津大学Shimon Whiteson教授与强化学习之父Richard S. Sutton教授的争论也引发圈内一大波人的思考:
Richard S. Sutton教授的观点如下:

Shimon Whiteson教授的观点如下:
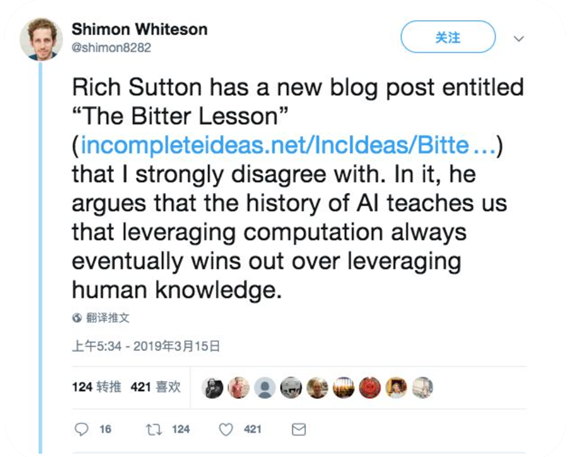
针对上述思辨,黄民烈非常认同Sutton的观点。Search and learning能够去做扩展的一个非常基础的因素,早期的专家系统存在不能扩展、不能解决知识之间的冲突等问题,因此不能做很好的不确定性推理,最终没有取得很大的成功。而GPT-3非常好地利用了数据、学习的能力、算力,是非常有希望的,但未来真正的通用AI脱离知识是不行的。
GPT-3这种通用的方法可能在技术上非常高效,做概率的关联也非常高效,但在解决一些基础推理问题的时候不太有效。这个时候我们的知识、规则、更高层次的推理起着非常重要的作用。Gary Marcus有一个神经符号推理的想法,考虑将我们的真实语言连接到认知模型上,而认知模型可能是知识图谱,这种东西关联在一起可能实现通用智能的路径,但是这也说不好,因为还需要解决可扩展的问题,如果只解决小范围的问题,也没有什么用。
如果用物理学来类比AI的话,我们可能还处在牛顿之前那个时期,还没有到牛顿之后的时期。何晓冬提到在没有足够的观察、没有积累足够的实际观测数据时去谈理论可能会走偏,比如当年亚里士多德这种天才虽然提出过很多深邃的见解,但他在物理学方面很多观点也是有其局限性。目前AI领域还没有一个理论像牛顿三大定律一样,能够告诉AI怎么走。现在还没有看到真正能够帮助我们直接设计一个AI机器出来的知识,相关知识是不是被扔掉了,也许我们连足够的观察都还没积累起来。
以Geoff Hinton为代表的这一整套代表大数据、大计算的体系在当下之所以能够成功,并不是因为Hinton比其他科学家更聪明,当然Hinton能发明深度学习算法一定非常聪明,但在某种程度上来说他也更幸运,幸运在我们这个世界在过去大半个世纪通过半导体技术实现了计算力的指数级增长,我们在过去几十年一直很享受这个过程。大数据也是一份幸运,由于互联网的原因,数据也在一直呈指数级增长。由于这两种基本资源的增长,Hinton等人在过去发明的东西突然有用武之地了。之后的十年可能还是这个路线,更远以后不好说,因为以后可能会有新的资源出现。
人类对知识的理解还处于探索的阶段。孙宇认为什么是知识目前还没有定义好,知识是人类认知的过程,如推理、因果关系,也可能是一些观察、注意力机制。现在统领了整个NLP发展的Transformer模型也来源于对观察的认知。哪怕100%的知识里面有1%的知识能够被用来改进这些模型的效果,其实它也是有用的。当然,算力也是不可或缺的。
趋势是很重要的,数据、算力是大趋势,承载主要的进步,但不代表应该放弃应用人类知识的尝试。严睿认为在大的主流下应该会有不同的突破方向,知识肯定是其中一种。
目前AI领域的任务都太简单,所以让人感觉单纯通过学习、数据就可以搞定。刘知远认为我们现在之所以觉得基于大数据或大算力的模型取得了非常大的进展,主要是因为现在的这些任务都还是比较简单的,与人的智能水平还有比较大的距离。Whiteson与Sutton的观点可能在某个侧面是准确的,从长远来看,真的要实现像人一样思考、具有人的智能能力模型还有很长的路要走,光靠数据远远不够。
“我们没有找到正确利用知识的方式,特别是使得它更加扩展的方法,这后面有很多需要做的。有一些任务不需要知识,有一些任务很需要知识,做推理的时候,知识很重要,因为人有大量的知识,这个知识有可能在长期进化过程中固化在大脑里边,这些说不清楚,需要认知科学相应的研究做支撑。”黄民烈总结道。
五、 GPT-3能否给AI续命?是否会造成科研垄断?
GPT-3应该不会造成垄断,因为AI的主要资源来自计算和数据,二者的价格在可预见的未来还会呈指数级便宜下去,所以在这个领域是非常活跃的,并不容易出现垄断和固化。何晓冬首先表达了自己的观点,并以互联网的发展为例进行了阐释。
学术界的高校应该要有危机感。刘知远根据自己参会的经验总结出了很明显的趋势:企业愿意去哪些会,意味着哪些领域的问题是这些公司特别需要的。从BERT、GPT-3的诞生机构也可以看出来,高校在做研究时要及时调整方向,凡是公司擅长做的事情,高校就不应该去花太多的精力在那个上面,高校应该做特别前沿的研究。
黄民烈对此表示赞同,并指出科研出现了“贫者愈贫,富者愈富”的现象。因为企业中的人有数学功底,工程能力很强,有算力,也有数据,所以能做GPT-3这类工作,这些东西在高校基本做不出来,这是一个很大的问题。谷歌有几个特别有名的工作在高校根本做不出来,因为没有这个条件。
一名好的学者一定要把目标放高远。何晓冬从工作价值的角度提出了自己的建议,并建议科研工作者无论是做论文,还是做系统,都要思考是不是有充分的影响力。好的工作永远是稀少的, GPT-3出来以后好的工作所占的比例也没有太大波动。高校可以瞄准做五年十年以后会爆发的东西。
产业界在深度学习时代相对来说有优势,因为有大规模的数据、算力、工程系统、架构等有一系列的优势,所以近十年来NLP的突破性工作很多都是谷歌、微软这些巨头搞出来的。孙宇首先分析了NLP的研究现状,并指出:如果沿着深度学习这个方向研究的话,高校和公司可以有更多的合作,企业可以解决工程性问题,以及怎么应用,而高校可以解决为什么有效这类更基础性的问题。
何晓冬补充提到:随后十年如果算力、数据还是现有趋势发展的话,算法需要能够从算力和数据中得到优势。也许不用神经网络了,也许不用现在流行的激活函数了,但肯定需要大容量模型做这个事情,模型容量足够大才能从便宜的算力和数据中受益。
“Life will find its way out”(生命总会找到出路的)。严睿认为垄断不会形成,学术界的研究者们,无论是在高校,还是在企业,作为乐于自我挑战的一群人,大家总会找到一个细分的领域,或者一个可能在未来爆发的点钻研下去。这是搞科研的这个群体应该干的事情,所以预计不太会有科研垄断的现象出现。
Q&A
Q1:我一直以为创造能力、创造性是AI一个标志,但是GPT-3等及其他AI算法,还都是类似于概率模型这样一个东西。那么,以后是否会出现一种创造性的模型真正能够描述、解释各种现象与逻辑?
黄民烈提到自己正在写的新书《现代自然语言生成》有关创造性的讨论,认为现在去看的话,生成故事、散文、诗歌等是需要一些创造性的,但是现在模型距离人类水平的创造性还挺远的。并以小学三年级《蜘蛛开店》课文为例指出:目前,用AI生成涉及知识、常识和有趣性的故事还存在较大困难。
与黄民烈意见不同,何晓冬相信GPT-3 的下一代也许可以做出这样的事,因为如果模型足够大,记忆、知识和推理很可能是可以统一的。如果记忆力足够强,包括检索记忆的能力也足够强,也可能会有意想不到的效果。

Q2:下一代新的模型的创新来源点在哪?
人类的学习不是说只学语言文本,还要在真实环境中和大家交流。所以,孙宇认为下一代模型的创新点可能是跨模态的,即不只是语言的大数据,可能还会把互联网上的图片、视频等通过深度学习的语义表示进行统一的建模,以后跨模态可能会成为非常大的突破。
跨模态确实还是有很多机会的,何晓冬表示,如果把百亿级的图片、视频中的所有的物体和关系进行识别,如果把整个物理世界通过跨模态摘出来做预训练,可以做很多,甚至有可能把常识问题给顺便解决了。因为写成文字的知识都是比较高级、比较专业的知识,常识往往都不会被写下来,因为常识就是生活的常态,但往往会记录在海量的日常生活中的照片与视频里。
审稿:何晓冬、严睿、黄民烈、刘知远、孙宇
整理:田志远
排版:岳白雪








