AAAI 2018学术见闻——NLP篇
作者:哈工大SCIR博士生 朱海潮 王宇轩
一、会议概况介绍
AAAI2018(https://aaai.org/Conferences/AAAI-18/)于2018年2月2日到2018年2月7日在美国新奥尔良举办。本次会议共收到投稿3808篇,最终录用938篇论文,录用率为24.6%。
本次会议接受最多的投稿来自中国,多达1242篇,比去年增长58%,美国紧随其后,有934篇。对比去年两国投稿数量(中国785篇、美国776篇)可以明显感受到中国人工智能研究的飞速发展。但同时也应注意到,尽管投稿数远超美国,但是两国的论文录用数却基本持平(中国265篇,录用率21.3%、美国268篇,录用率28.4%),因此如何提高论文质量从而提升录用率,也是今后需要重视的问题。
此外,从研究领域来看,今年投稿及录用前三的领域分别是机器学习方法(Machine Learning Methods)、视觉(Vision)和自然语言处理及机器学习(NLP and Machine Learning)。与去年的前三名(机器学习、自然语言处理和应用)相比,视觉领域可谓异军突起,投稿率和录用率增幅分别达257%和285%。
由于AAAI会议囊括了人工智能领域几乎所有分支的内容,许多活动时间重复,因此本文主要介绍自然语言处理相关领域的学术见闻。
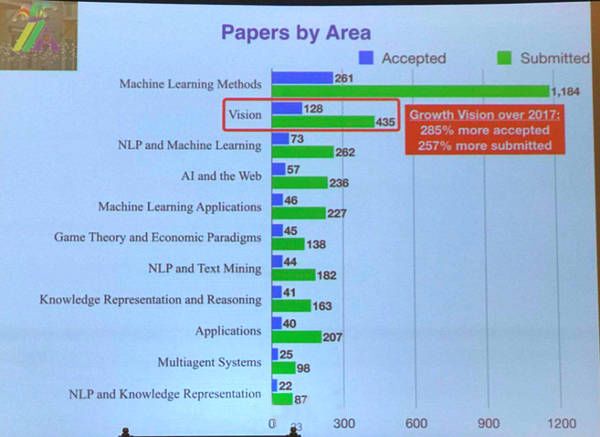
图1 本次会议接受论文按领域分布情况
二、讲习班简介
会议前两天(2月2日到3日)是讲习班时间,本次会议共有26个涵盖了人工智能各个领域的讲习班,由于许多讲习班是同时进行的,这里只对其中两个进行简介。关于讲习班更具体的信息及slides可以在https://aaai.org/Conferences/AAAI-18/aaai18tutorials/ 找到。
1、结构化预测的近期发展
该讲习班的主讲人是来自华盛顿州立大学的Jana Doppa助理教授、来自塔夫茨大学的Liping Liu助理教授和来自俄勒冈州立大学的博士生Chao Ma。结构化预测(structured prediction)方法被广泛地应用于自然语言处理、计算机视觉及生物信息学等研究领域。近年来结构化预测领域有许多新的研究进展,包括新的框架、算法、理论及分析等。三位主讲人在讲习班中系统地介绍了现存的各种解决结构化预测问题的框架,并着重讲解了该领域近年来的发展。例如:基于搜索的结构化预测、摊销推理(amortized inference)、PAC理论与推理、多任务结构化预测以及如何将深度学习方法应用到结构化预测中。最后,他们指出了该领域有可能的发展和研究方向。
2、网络表示学习
该讲习班的主讲人是来自清华大学的助理教授崔鹏。如今,大型复杂网络被应用在越来越多的实际场景中,网络数据也被公认为是复杂且具有挑战性的,有效处理图结构数据的最主要的挑战就是网络数据的表示,即如何合适地表示网络使后续的模式挖掘、分析预测等高阶任务更快的完成,同时不浪费过多的空间资源。在讲习班上,主讲人介绍了近年来在网络嵌入方面的研究成果,对若干重要概念(Graph Embedding vs Network Embedding)加以区分讲解,并讨论了一系列网络嵌入中的重要基本问题,如我们为什么要重新审视网络表示,网络嵌入的研究目标是什么,如何学习有效的网络嵌入方法,评价网络表示的若干基本要素,还有网络嵌入方面的未来若干主要研究方向。另外,崔鹏教授所在团队发表一篇网络嵌入的综述,可以作为本讲习班的一个扩展阅读,arXiv地址:https://arxiv.org/abs/1711.08752 。
三、特邀演讲介绍
本次会议特别邀请了人工智能领域七位重量级嘉宾做了主题演讲,这七位特邀嘉宾分别为 Subbarao Kambhampati教授、Yejin Choi助理教授、Cynthia Dwork教授、Zoubin Ghahramani教授、Joseph Halpern教授、Charles Isbell教授和Percy Liang助理教授。他们分别从自己研究领域出发,分享自身研究成果,为观众带来一场AI知识盛宴。
1、人类感知AI系统的挑战——Subbarao Kambhampati
AAAI 2018主席,亚利桑那州立大学的Subbarao Kambhampati教授的演讲主题是《人类感知AI系统的挑战》(Challenges of Human-Aware AI Systems)。随着AI技术与我们日常生活越来越紧密的结合,使用AI系统协助人类工作的需求日益增加。要满足这些需求,AI系统需要更重视情感智能、社交智能等能帮助人类互相协同的智能方面。演讲中,Kambhampati教授介绍了设计具有人类认知功能的AI系统过程中遇到的挑战,包括对人类的心理状态进行建模、识别人类的意图、提供积极的帮助、采取具有可解释性的动作以及产生信任。此外,他还谈到人类感知AI系统的问题。探索这一问题可以扩大人工智能企业的研究范围,有效促进了真正的跨学科合作,甚至能够提高公众对人工智能技术的接受程度。

图2 Subbarao Kambhampati教授演讲现场
2、从纯粹的物理世界到内涵:用语言来学习和推理世界——Yejin Choi
华盛顿大学助理教授Yejin Choi的演讲主题是《从纯粹的物理世界到内涵:用语言来学习和推理世界》(From Naive Physics to Connotation: Learning and Reasoning about the World using Language)。常识性知识对于机器理解语言十分重要。然而这些常识往往不被言明,因而从语言交流中学习这些常识十分困难(例如人们往往不会在交流中直接说出类似于“房子比人大”这种常识)。Yejin Choi在演讲中介绍从语言中还原出这些日常知识的方法。方法的核心思想是:人们共有的隐性知识系统地影响着人们使用语言的方式,以语言使用方式为线索,真实世界的常识可以从语言中推理出来。(例如,从“我进入了房子”这句话就能推断出房子比我大。)在具体实施过程方面,她首先介绍了如何利用框架语义组织多种多样的常识,这些常识包括最简单的具体知识以及抽象的内涵知识。除了这种以框架语义表示为中心的方法外,她还介绍了利用神经网络的方法。最后,她讨论了这些方法所面临的挑战,并指出了该领域未来可能的研究方向。
图3 Yejin Choi助理教授演讲现场
3、我们应该如何评价AI的机器学习——Percy Liang
著名华人NLP专家,来自斯坦福大学的助理教授Percy Liang这次带来的演讲主题是《我们应该如何评价AI的机器学习》(How Should We Evaluate Machine Learning for AI?)。机器学习帮助人工智能取得的巨大成功,但它同时也带来了一种“训练-测试-评价”的范式。这种标准范式过分注重提高系统的平均表现,忽视系统在对抗样本上的表现,无法保证系统的鲁棒性。除此之外,这种范式对于交互式系统(对话系统)或没有正确答案的任务也无可奈何。Percy Liang在演讲中介绍了自然语言处理领域里一些其它的评价范式,并讨论了如何指导人工智能向有意义的方向发展。

图4 Percy Liang助理教授演讲现场
另外四位特邀嘉宾中,Cynthia Dwork教授讲了有关公平问题的研究,Zoubin Ghahramani教授讲了概率机器学习前沿动态,Joseph Halpern教授讲了关于真实推理问题的研究,Charles Isbell教授则讲了交互式机器学习研究中的问题和技巧。具体信息可以参考https://aaai.org/Conferences/AAAI-18/invited-speakers/。
在此次会议上,AAAI还专门推出了AI和人类协作新兴课题计划,其目的就是为了突出这些技术的挑战和机遇,同时展现新的人与AI伙伴关系的价值。因此,除七位特邀演讲嘉宾之外,还邀请了四位嘉宾,从他们的研究领域出发,分别从四个不同的角度对这一新兴课题进行阐述。具体信息可以参考https://aaai.org/Conferences/AAAI-18/haic/。
四、论文选介
1、最佳论文
本次会议的最佳论文(Outstanding Paper)奖一栏包括以下四篇文章:
1)最佳论文奖(Outstanding Paper):Chenjun Xiao, Jincheng Mei, Martin Müller. Memory-Augmented Monte Carlo Tree Search
2)最佳学生论文奖(Outstanding Student Paper):Jakob N. Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, Shimon Whiteson. Counterfactual Multi-Agent Policy Gradients
3)最佳论文奖提名(Outstanding Paper, Honorable Mention):Juan D. Correa, Jin Tian, Elias Bareinboim. Generalized Adjustment Under Confounding and Selection Biases
4)最佳学生论文奖提名(Outstanding Student Paper, Honorable Mention):Rachel Freedman, Jana Schaich Borg, Walter Sinnott-Armstrong, John P. Dickerson, Vincent Conitzer. Adapting a Kidney Exchange Algorithm to Align with Human Values
其中最佳论文奖的一作二作都是中国留学生,他们的导师Martin Müller是计算机围棋领域的顶级专家,主要研究领域包括:博弈树搜索和规划中的蒙特卡洛方法、大规模并行搜索、组合博弈论等。而AlphaGo的主要设计者David Silver和Aja Huang都曾师从于他。本文提出了一种记忆增强的蒙特卡洛树搜索算法,其核心思想是为蒙特卡洛树搜索增加一个记忆结构用来保存特定状态的信息,然后通过组合该记忆结构中相似状态的估计值对近似值进行估计。围棋任务上的实验表明该算法的性能在相同模拟次数情况下优于普通蒙特卡洛树搜索算法。
本次会议共录用自然语言处理领域论文73篇,其中句法语义分析、问答系统、表示学习、情感分析、文本生成、机器翻译和对话系统等领域录用数量相对较多。这里从每个领域中选取一篇有代表性的论文进行介绍。
2、句法语义分析
* Xiaochang Peng, Daniel Gildea, Giorgio Satta. AMR Parsing with Cache Transition Systems
AMR(Abstract Meaning Representation)是句子的一种语义表示,每个句子的含义都用一个有向图来表示,图5给出了一个AMR的例子。本文提出了一种新的转移系统,使得原本用于分析依存树结构的基于转移的分析方法能用于分析这种AMR语义图。具体来说,在原来转移系统的栈(stack)和缓存(buffer)之外,作者新增了一个具有固定长度的cache结构用于暂时保存图中节点,其中的所有节点都能与缓存中第一个节点之间产生弧,也就解决了分析图结构的问题。
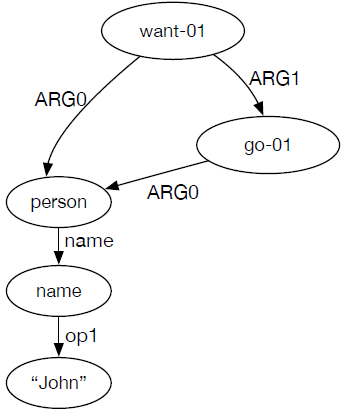
图5 AMR语义图结构
近年来随着研究者们对语义结构的日益重视,出现了越来越多图结构的语义语料库,相应的对语义图的分析方法研究也越来越多。本次会议上除了这篇文章之外,也有对依存语义图的分析方法的研究工作:
* Yuxuan Wang, Wanxiang Che, Jiang Guo, Ting Liu. A Neural Transition-Based Approach for Semantic Dependency Graph Parsing
当然,也有一些对传统短语结构树或者依存树的分析方法的研究工作:
* Lemao Liu, Muhua Zhu, Shuming Shi. Improving Sequence-to-Sequence Constituency Parsing
* Yi Zhou, Junying Zhou, Lu Liu, Jiangtao Feng, Haoyuan Peng, Xiaoqing Zheng. RNN-Based Sequence-Preserved Attention for Dependency Parsing
3、问答系统
* Lei Sha, Jin-ge Yao, Sujian Li, Baobao Chang, Zhifang Sui. A Multi-View Fusion Neural Network for Answer Selection.
社区问答(CQA)任务要求根据给定的问答从候选集合中选择最恰当的答案,之前的基于神经网络的方法通过计算attention的方式来收集、组合有用的信息,这种single-view的方法不能从多个方面来审视问题和候选答案,进而导致信息的丢失。本文提出了Multi-View Fusion Neural Network从多个view来表示答案。图6为inquiry type、inquiry main verb、inquiry semantic三个view的示意图,图7为co-attention view的示意图。
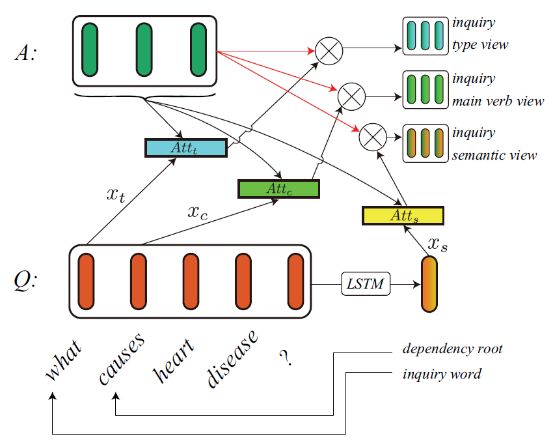
图6 inquiry views示意图
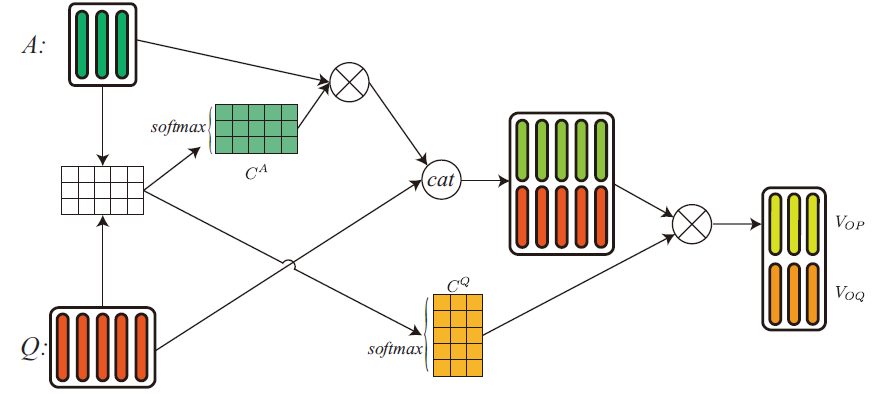
图7 co-attention view示意图
然后本文提出Fusion RNN来融合基于所有view的答案表示,Fusion RNN的结构如图8所示,在结构设计上借鉴了残差网络的思想。模型在WikiQA和SemEval-2016 CQA任务上取得了超过SOTA的结果。
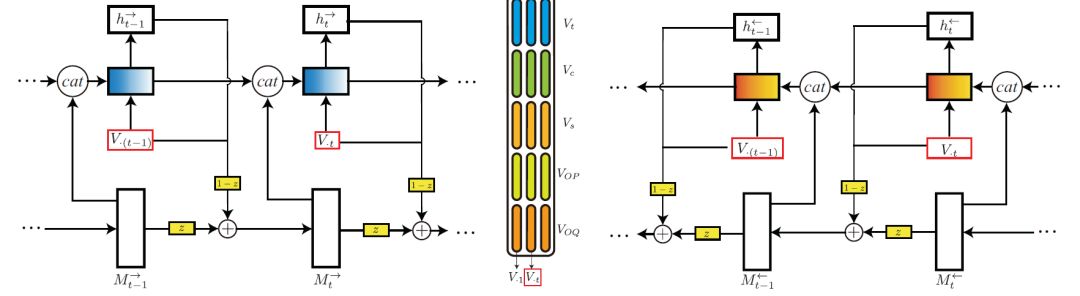
图8 Fusion RNN示意图
此外,机器阅读理解可以被视为基于给定上下的问答任务,为今年来十分热门的一个研究任务,推荐本次会议录用的以下几篇论文作为扩展阅读内容:
* Chuanqi Tan*, Furu Wei, Nan Yang, Bowen Du, Weifeng Lv, Ming Zhou. S-Net: From Answer Extraction to Answer Synthesis for Machine Reading Comprehension.
* Tom Kenter*, Llion Jones, Daniel Hewlett. Byte-level Machine Reading across Morphologically Varied Languages.
* Haichao Zhu, Furu Wei, Bing Qin*, Ting Liu. Hierarchical Attention Flow for Multiple-choice Reading Comprehension.
* Xiao Zhang*, Xiao Zhang, Ying Su, Zhiyang He, Xien Liu, Ji Wu. Medical Exam Question Answering with Large-scale Reading Comprehension.
4、表示学习
* Noah Weber*, Niranjan Balasubrama, Nathanael Chambers. Event Representations with Tensor-based Compositions.
鲁棒和灵活的事件表示方法对许多语言理解的核心领域有重要意义,之前基于脚本的方法被用来表示事件序列,然而获取一个有效表示来建模类似脚本的事件序列非常有挑战性,需要同时捕捉事件和场景语义。本文提出了一种新的基于tensor的组合方法来表示事件,能够捕捉事件和事件实体间更加细微的语义交互,得到的表示在多个事件相关的任务上都非常有效。并且,藉由这种连续的向量表示,本文提出了一种简单的Schema(类似脚本的关于特定场景的知识)生成方法,得到比之前基于离散表示的方法更好的结果。
具体地,本文提出了两个tensor-based组合模型:
Predicate Tensor Model结构如图9所示,首先函数h组合谓词(predicate)的embedding和两个参数张量W(图9中蓝色张量W)、U来生成谓词张量W(图9中粉色张量W),然后函数g则将谓词张量和subject,object的embedding组合为最后的事件向量表示。
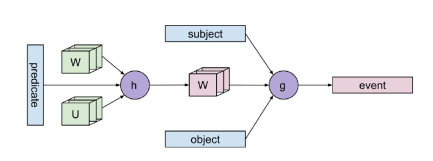
图9 Predicate Tensor Model示意图
但有时不需要共同建模谓词和其所有论元才能确定使用的上下文,比如知道football是throw的一个论元就可以确定该事件归属体育类。因此,本文提出了Role Factored Tensor Model,函数f根据参数张量T分别将谓词与subject和object组合得到,然后分别经变化并相加后得到最终的事件表示。Role Factored Tensor Model比Predicate Tensor Model使用了更少的参数,并且能够泛化到有任意数量论元的事件。
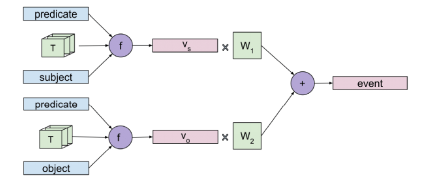
图10 Role Factored Tensor Model示意图
本次会议还有几篇关于更基本的词向量学习的论文:
* Qian Liu, Heyan Huang*, Guangquan Zhang, Yang Gao, Junyu Xuan, Jie Lu. Semantic Structure-Based Word Embedding by Incorporating Concept Convergence and Word Divergence
* Peng Fu*, Zheng Lin, Fengcheng Yuan, Weiping Wang, Dan Meng. Learning Sentiment-Specific Word Embedding via Global Sentiment Representation
* Danushka Bollegala*, Yuichi Yoshida, Ken-ichi Kawarabayashi. Using k-way Co-occurrences for Learning Word Embeddings
* Chen Li, Jianxin Li*, Yangqiu Song, Ziwei Lin. Training and Evaluating Improved Dependency-Based Word Embeddings.
* Mikel Artetxe*, Gorka Labaka, Eneko Agirre. Generalizing and Improving Bilingual Word Embedding Mappings with a Multi-Step Framework of Linear Transformations
5、情感分析
* Yukun Ma, Haiyun Peng, Erik Cambria. Targeted Aspect-Based Sentiment Analysis via Embedding Commonsense Knowledge into an Attentive LSTM
基于aspect的情感分析和基于target的情感分析是目前情感分析领域中两个重要问题。一句话可能对多个不同的事物表达不同的情感倾向,基于aspect的情感分析将一句话中的情感分成多个aspect,从而能预测出一句话中对不同事物的不同情感。而基于target的情感分析的目的则是分析出一句话对上下文中出现的给定目标(target)的情感倾向。本文提出了一种利用常识知识同时解决这两个问题的方法。作者在LSTM结构的基础上使用了多级注意力机制(hierarchical attention mechanism),分别计算了target级的注意力表示和句子级的注意力表示用以预测情感极性。此外,他们还对LSTM的结构做了改进,从而将常识知识的表示向量加入网络结构中。
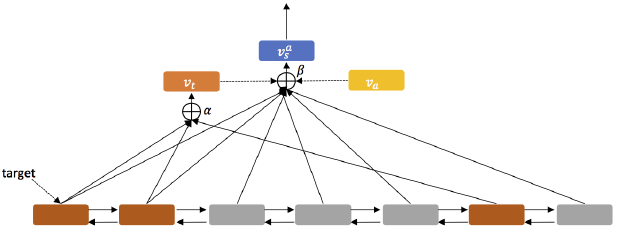
图11 Attentive神经网络结构
图11是本文提出模型的基本网络结构,首先将句中每个词的词向量作为双向LSTM的输入,然后用每个词位置的隐层输出来表示对应词。其中棕色表示target词,这些词的表示被用来计算target级注意力表示向量。之后该表示向量与不同的aspect向量组合得到句子级注意力表示向量。最后将该句子级向量输入一个多分类器获得该句子对应aspect的情感倾向。
本次会议的情感分析方面论文还有几篇也是解决基于aspect的情感分析问题的,可以看出随着该领域近年来的快速发展,研究目标已经越来越细化,不局限于分析一个句子表现的整体情感倾向,而要分析对不同目标表现出的不同情感。
* Bailin Wang, Wei Lu. Learning Latent Opinions for Aspect-level Sentiment Classification
* Jun Yang, Runqi Yang, Chong-Jun Wang, Jun-Yuan Xie. Multi-Entity Aspect-Based Sentiment Analysis with Context, Entity and Aspect Memory
* Yi Tay, Anh Tuan Luu, Siu Cheung Hui. Learning to Attend via Word-Aspect Associative Fusion for Aspect-based Sentiment Analysis
6、文本生成
* Lei Sha*, Lili Mou, Tianyu Liu, Pascal Poupart, Sujian Li, Baobao Chang, Zhifang Sui. Order-Planning Neural Text Generation From Structured Data
把结构化数据转换成文本对问答和对话等自然语言处理任务有重要意义。对于table-to-text任务,内容生成的顺序往往有一定的规律,如国籍经常出现在职业前(British writer),因此本文提出order-planning文本生成模型显示建模内容生成的顺序。具体模型如图12所示,Encoder将表格的域(Field)和值(Content)一起作为LSTM-RNN的输入。Decoder解码的过程中使用的hybrid attention由content-based attention和link-base attention组成,首先对Encoder中LSTM-RNN的输出计算content-based attention ,link-based attention用于显示建模内容生成顺序,使用上一时刻的hybrid attention 和Link Matrix()来得到当前时刻的link-based attention ,其中指示域出现在域后的可能性。最后通过自适应的gate机制来组合得到。同时,模型的decoding时也引入了生成模型中常用的copy机制来更好的根据表格内容生成文本。提出的模型在WIKIBIO数据集上取得了目前最好的结果,并且做了充分的分离实验和样例分析。
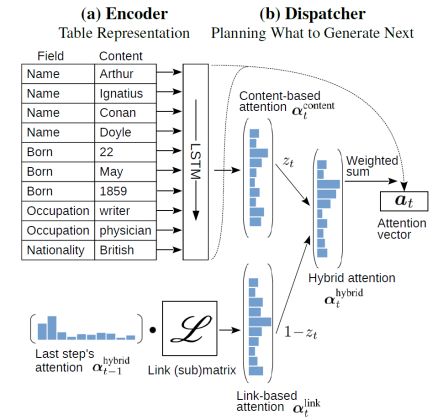
图12 Hybrid Attention示意图
在本次会议中还有另外两篇专注Table-to-Text生成任务的文章,将结构化数据转换为自然语言形式的文本是近来比较热门的任务之一。
* Tianyu Liu*, Kexiang Wang, Lei Sha, Zhifang Sui, Baobao Chang. Table-to-text Generation by Structure-aware Seq2seq Learning.
* Junwei Bao*, Duyu Tang, Nan Duan, Zhao Yan, yuanhua Lv, Ming Zhou, Tiejun Zhao. Table-to-Text: Describing Table Region with Natural Language
7、对话系统
* Xiaoyu Shen*, Hui Su, Vera Demberg, Shuzi Niu. Improving Variational Encoder-Decoders in Dialogue Generation
Varitional encoder-decoder (VED)已经被广泛应用于对话生成,但与用于编码和解码的强大RNN结构,隐向量分布通常由一个简单的多的模型来近似,导致了KL弥散和难以训练的问题。在本篇论文中,作者将训练过程拆分为两个阶段:第一个阶段负责学习通过自编码(AE)将离散的文本转换为连续的embedding;第二个阶段学习通过重构编码得到的embedding来泛化隐含表示。这样一来,通过单独训练一个VED模型来对高斯噪声进行变化,进而采样得到隐变量,能够得到一个更加灵活的分布。在与当前流行的对话模型对比的实验中,本文提出的模型在自动评测和人工评价上均取得了显著提升。
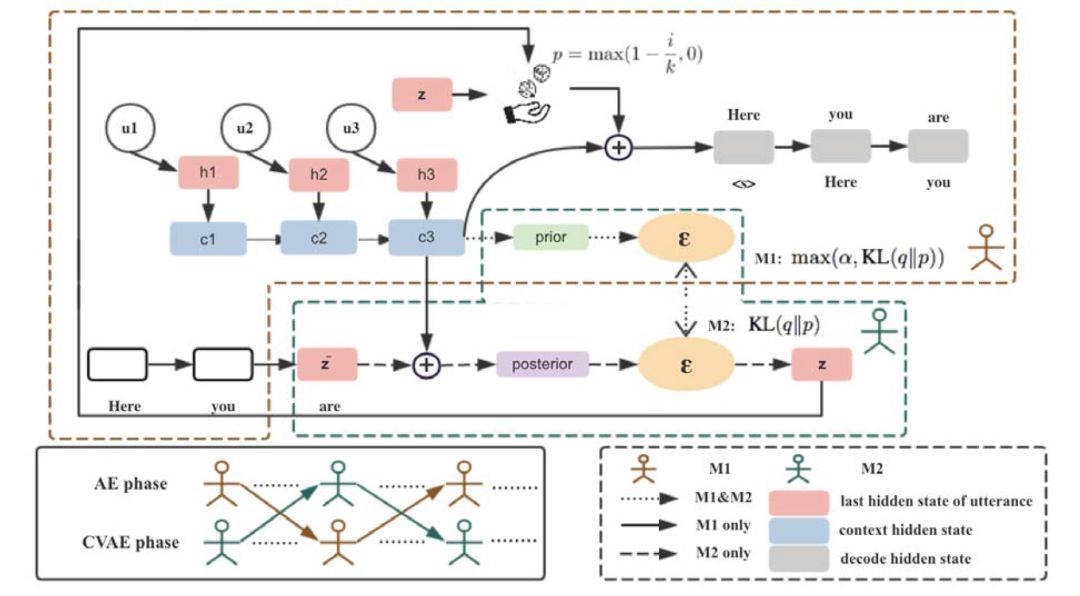
图13 模型示意图
相比抽取式的回复生成方法,生成式的方法近来受到越来越多的关注,本次会议中如下几篇论文为有关研究生成式回复生成的文章:
* Nurul Lubis*, Sakriani Sakti, Koichiro Yoshino, Satoshi Nakamura. Eliciting Positive Emotion through Affect-Sensitive Dialogue Response Generation: A Neural Network Approach
* Weinan Zhang*, Lingzhi Li, Dongyan Cao, Ting Liu. Exploring Implicit Feedback for Open Domain Conversation Generation
* Yu Wu*, Wei Wu, Zhoujun Li, Can Xu, Dejian Yang. Neural Response Generation with Dynamic Vocabularies
8、机器翻译
* Kehai Chen*, Rui Wang, Masao Utiyama, eiichiro sumita, Tiejun Zhao. Syntax-Directed Attention for Neural Machine Translation
注意力机制(attention mechanism)对于神经机器翻译(NMT)来说具有决定性作用。传统NMT中使用的注意力机制的权重往往是距离目标词线性距离越远就越小,却忽略了句法距离的限制。本文扩展了NMT中的传统的局部注意力机制,用句法距离代替线性距离决定权重。从而提高了系统性能。此外,他们还将该方法与全局注意力机制结合,进一步提高了系统性能。
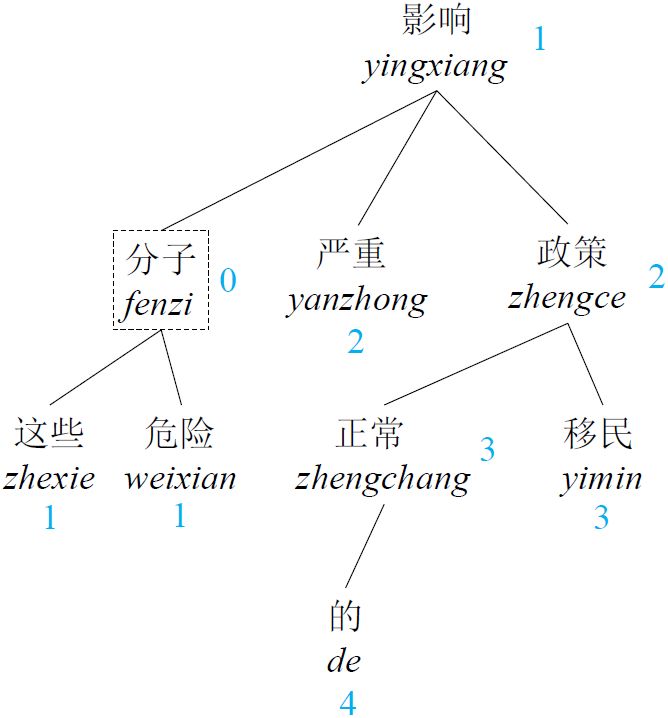
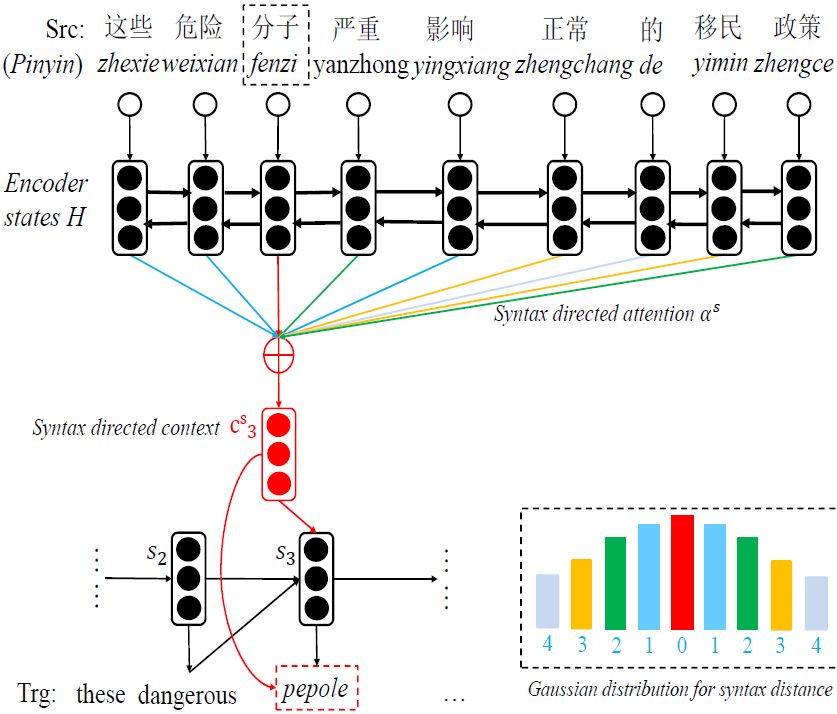
图14 句法距离注意力机制示意图
图14中上图是原句的句法树结构,上面用蓝色标出了每个词在树结构上与当前词“分子”的距离。下图用不同颜色表示了每个词与当前词“分子”在句法树上的距离,具体见下方柱形图(例如:绿色表示句法距离为2)。
本次会议录取的机器翻译领域论文较多,也有独立的session,这些工作中有利用了多语言数据的,也有提出了新的网络结构的:
* Zhirui Zhang, Shujie Liu, Mu Li, Ming Zhou, Enhong Chen. Joint Training for Neural Machine Translation Models with Monolingual Data
* Chen-Tse Tsai, Dan Roth. Learning Better Name Translation for Cross-Lingual Wikification
* Shenjian Zhao, Zhihua Zhang. Attention-via-Attention Neural Machine Translation
* Jinsong Su, Shan Wu, Deyi Xiong, Yaojie Lu, Xianpei Han, Biao Zhang. Variational Recurrent Neural Machine Translation
五、总结
虽然本文主要只从自然处理相关领域的视角介绍了AAAI 2018会议,但管中窥豹可见一斑,从这些介绍中就能看出AAAI会议的盛况及其在人工智能领域越来越大的影响力,同时也能发现越来越多华人的身影活跃在人工智能研究的世界舞台上。AAAI 2019将在美国夏威夷州火奴鲁鲁市举办,期待中国学者能在人工智能领域获得更卓越的成果。
本期责任编辑: 刘一佳
本期编辑: 吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。



