干货 | 可解释的机器学习

编译 | AI研习社
原标题 | Interpretable Machine Learning
作者 | Parul Pandey
译者 | intelLigenJ(算法工程师)、鸢尾
注:本文的相关链接请访问文末【阅读原文】
图源Pexels的Pixabay
是时候摆脱黑盒模型,构建起对机器学习的信任了!
想象你是一个数据科学家,你想要在业余时间根据你朋友在facebook和twitter上发布的信息,来预估你朋友假期要去度假的地方。如果你预测对了,你朋友一定叹为观止,觉得你是锦鲤附身。如果你猜错了也没啥,只不过有点影响身为数据科学家的口碑而已。但如果你和其他人打了赌,就赌这个朋友暑假会去哪里,这时候预测错误的成本就有点高了。也就是说,当模型对错本身不造成很大影响的时候,解释性并不算是很重要的要素。不过当预测模型用于金融、公共事务等重大影响决策时,解释性就显得尤为重要了。
可解释的机器学习
理解(interpret)表示用可被认知(understandable)的说法去解释(explain)或呈现(present)。在机器学习的场景中,可解释性(interpretability)就表示模型能够使用人类可认知的说法进行解释和呈现。[Finale Doshi-Velez]

来自:可解释的机器学习
机器学习模型被许多人称为“黑盒”。这意味着虽然我们可以从中获得准确的预测,但我们无法清楚地解释或识别这些预测背后的逻辑。但是我们如何从模型中提取重要的见解呢?要记住哪些事项以及我们需要实现哪些功能或工具?这些是在提出模型可解释性问题时会想到的重要问题。
可解释性的重要性
总有人会问,为什么模型给出预测结果了还不满意,还要这么执意于知道模型是如何做出预测的?这和模型在真实世界中产生的影响有很大关系。对于仅仅被用来做电影推荐的模型而言,其影响性相较于做药物效果预估所使用的模型要小得多。
问题在于一个单一指标,就好比分类准确率,是不足以刻画真实世界中的大部分问题的。(Doshi-Velez and Kim 2017)
这里有一个可解释机器学习的大框架。在某种程度上,我们通过从真实世界(World)中获取一些原始数据(Data),并用这这些数据进行更深入的预测分析(Black Box Model)。而模型的解释性方法(Interpretability)只是在模型之上增加了一层,以便于人们(Humans)更好地理解预测过程。
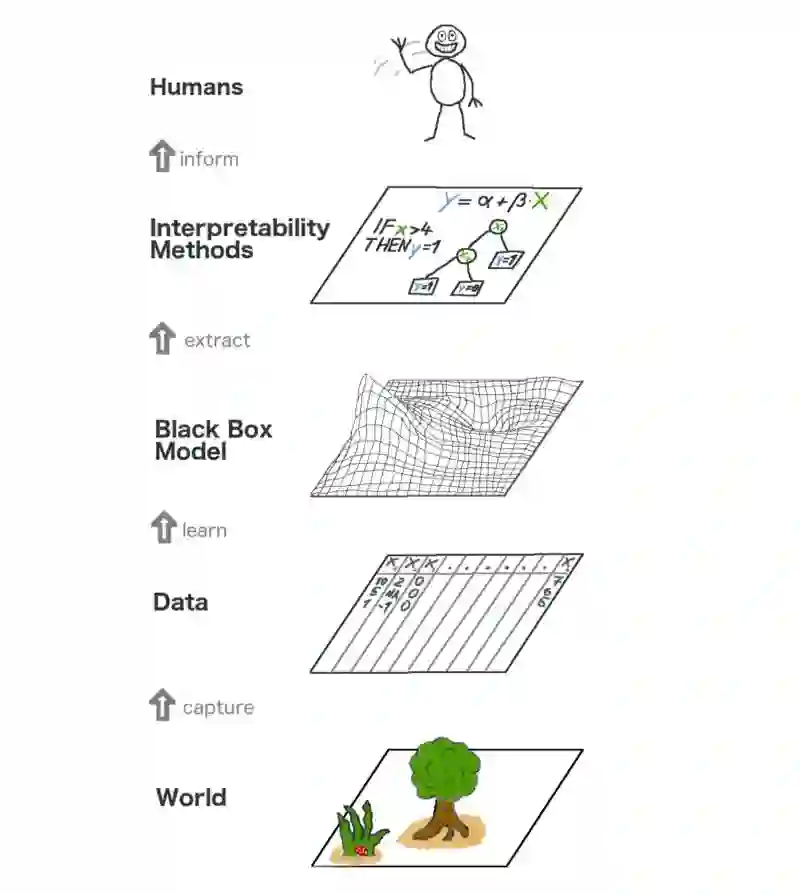
可解释机器学习的大框架
以下是一些由可解释性带来的好处:
可靠性
易于调试
启发特征工程思路
指导后续数据搜集
指导人为决策
建立信任
模型解释的具体技术
实践是检验真理的唯一标准。如果你想对这个领域有一个更真切的了解,你可以试试Kaggle上的机器学习解释性crash课程。这里头有足够多的理论和代码来帮助你将模型解释性的概念应用到真实世界的问题中去。
点击下面的连接来进入课程页面。不过如果你想先对课程内容有一个简单的了解,你可以先继续阅读本文。
https://www.kaggle.com/learn/machine-learning-explainability
洞悉模型
想要理解一个模型,我们需要洞悉如下的内容:
模型中最重要的特征
对于每一次预估决策,不同特征变量发挥的作用
每个特征在使用大量数据进行预估时发挥的作用
接下来,我们会探讨从模型中获取上述信息所使用的具体技术:
1. Permutation Importance
对于模型来说,哪一个特征才是最重要的?哪一个特征对于模型做决策有更大的影响?这个概念被称为特征重要度,而Permutation Importance正是目前被广泛采用计算特征重要度的方式。当我们的模型预测出了难以理解的结果时,我们可以通过这个指标来知道到底发生了什么。当然,如果我们需要向别人解释自己模型的预测时也可以用这种方法。
Permutation Importance对很多scikit-learn中涉及到的预估模型都有用。其背后的思想很简单:随机重排或打乱样本中的特定一列数据,其余列保持不变。如果模型的预测准确率显著下降,那就认为这个特征很重要。与之对应,如果重排和打乱这一列特征对模型准确率没有影响的话,那就认为这列对应的特征没有什么作用。
使用方法
试想我们现在做了一个预测足球队里谁会获得“足球先生”称号的模型,并且该模型并不是几个简单参数就能刻画的。当然,只有表现最好的球员才能获得此称号。
Permutation Importance是在模型完成拟合之后才进行计算的。所以,我们先用RandomForestClassifier在训练样本上拟合出一个分类模型,我们不妨称之为my_model。
我们使用ELI5库可以进行Permutation Importance的计算。ELI5是一个可以对各类机器学习模型进行可视化和调试Python库,并且针对各类模型都有统一的调用接口。ELI5中原生支持了多种机器学习框架,并且也提供了解释黑盒模型的方式。
通过eli5库来计算并展示特征重要度:
import eli5from eli5.sklearn import permutationImportanceperm = PermutationImportance(my_model, random_state=1).fit(val_X, val_y)eli5.show_weights(perm, feature_names = val_X.columns.tolist())

模型解释
最上面的特征是最重要的特征,最下面则是最不重要的特征。在这个case中,进球数(Goal Scored)是最重要的特征。
±后面的数字表示多次随机重排之间的差异值
有些特征重要度权重是负数,表示随机重排这些特征之后,模型的表现甚至更好了
练习
现在,我们可以用一个完整的例子来检验一下你对该方法的理解,你可以点击下面的连接来进入Kaggle的页面:
https://www.kaggle.com/dansbecker/permutation-importance
2. Partial Dependency Plots
Partial Dependency Plots(后续用PDP或PD简称)会展示一个或两个特征对于模型预测的边际效益(J. H. Friedman 2001)。PDP可以展示一个特征是如何影响预测的。与此同时,我们可以通过绘制特征和预测目标之间的一维关系图或二维关系图来了解特征与目标之间的关系。
使用方法
PDP也是在模型拟合完成之后开始计算的。用刚刚足球球员的例子来说,模型使用了很多特征,类似传球数、射门次数、进球数等等。我们从中抽取一个样本球员来进行说明,比如该球员占全队50%的持球时长、传球过100次、射门10次并进球1次。
我们先训练模型,然后用模型预测出该球员获得“足球先生”的概率。然后我们选择一个特征,并变换球员该特征值下的特征输入。比如我们调整刚刚抽取的那名球员,将其进球数分别设置成一次、两次、三次,然后画出预测概率随着进球数变化的走势图。
Python中使用partial dependence plot toolbox来画PDP图,该工具简称PDPbox。
from matplotlib import pyplot as pltfrom pdpbox import pdp, get_dataset, info_plots# Create the data that we will plotpdp_goals = pdp.pdp_isolate(model=my_model, dataset=val_X, model_features=feature_names, feature= Goal Scored )# plot itpdp.pdp_plot(pdp_goals, Goal Scored )plt.show()
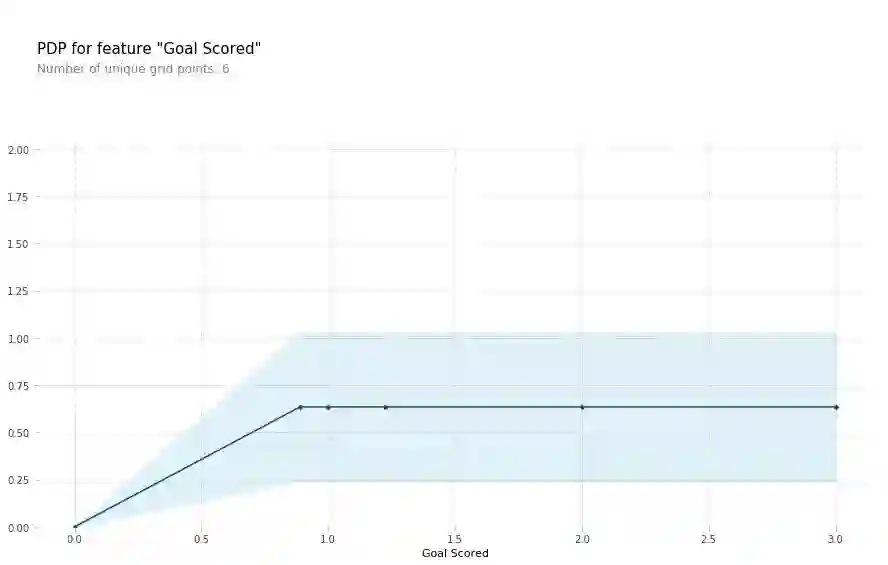
模型解释
Y轴表示预测相较于基准线或最左值的增加值
蓝色区域表示置信区间
从上图针对进球数的PDP分析看,随着进球数增多,球员获得“足球先生”的概率也会逐步增加,但增加到一定程度之后就收敛了。
我们同样可以使用二维图上画出针对两个特征的PDP分析图:
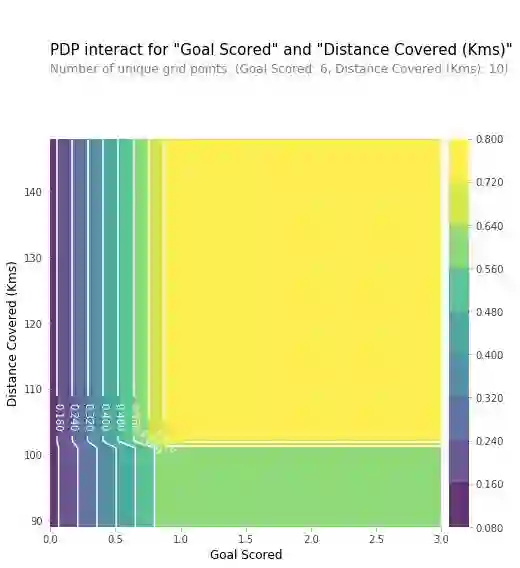
练习

https://www.kaggle.com/dansbecker/partial-plots
3. SHAP Values
SHAP(SHapley Additive exPlanation)有助于细分预测以显示每个特征的影响。它基于Shapley values,这是一种用于博弈论的技术,用于确定协作游戏中每个玩家促成其成功的贡献有多少¹。通常情况下,在准确性和可解释性之间取得正确的权衡可能是一个困难的平衡行为,但SHAP值可以同时提供这两者。
操作
再一次,以足球为例,我们想要预测一个球队有一名球员赢得“最佳球员”的概率。SHAP values解释了给定特性具有特定值的影响,并与我们在该特性具有某些基线值时所做的预测进行比较。
SHAP values 使用Shap库进行计算。从PyPI或conda安装Shap 库很简单.
Shap值显示给定的特性对我们的预测有多大的改变(与我们在该特性的某个基线值上进行预测相比)。假设我们想知道当球队进了3个球而不是某个固定的底线时预测是什么。如果我们能够解决这个问题,我们可以对其他功能执行相同的步骤如下:
sum(SHAP values for all features) = pred_for_team - pred_for_baseline_values因此,预测可以分解为如下图:

这里是一个更大视图的链接
解释
上面的解释显示了推动模型输出从基本值(我们传递的训练数据集中的平均模型输出)到模型输出的每个特性。将预测推高的特征用红色表示,将预测推低的特征用蓝色表示。
这里的base_value是0.4979,而我们的预测值是0.7。
得分= 2对预测增加的影响最大,
而控球率对预测减少的影响最大。
练习
有一个比我在这里解释的更深层次的SHAP values理论,你可通过下面的链接了解得更全面:
https://www.kaggle.com/dansbecker/shap-values
4. SHAP Values 的高级用法
聚合许多SHAP Values有助于更详细的了解模型。
SHAP 摘要图绘制
为了了解模型中哪些特性最重要,我们可以为每个示例绘制每个特性的SHAP values 。摘要图说明哪些特性是最重要的,以及它们对数据集的影响范围。

摘要图
关于每个点:
垂直位置显示了它所描述的特征
颜色显示数据集中这一行的特征值是高还是低
水平位置显示该值的影响是导致较高的预测还是较低的预测。
左上方的点是一个进球很少的球队,预测降低了0.25。
SHAP Dependence Contribution图
虽然SHAP摘要图给出了每个特性的一般概述,但是SHAP dependence图显示了模型输出如何随特性值而变化。SHAP dependence contribution图提供了与PDP类似的见解,但添加了更多的细节.

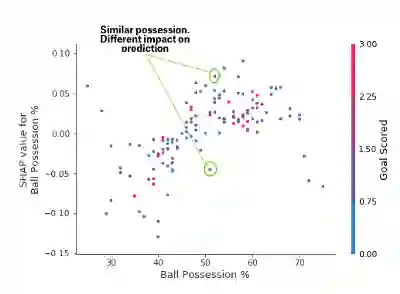

依赖贡献细节
上述依赖性贡献表明,拥有球会增加球队让球员赢得奖励的机会。但如果他们只得到一个进球,那么这个趋势就会逆转而且如果他们得分那么少,那么裁判可能会因为得分而惩罚他们。
练习
https://www.kaggle.com/dansbecker/advanced-uses-of-shap-values
总结
机器学习不再是黑盒了。如果我们无法向其他人解释结果,那么怎样使用才是好模型。可解释性与创建模型同样重要。为了在人群中获得更广泛的认可,机器学习系统能够为其决策提供令人满意的解释至关重要。
正如阿尔伯特·爱因斯坦所说:“如果你不能简单地解释它,你就不能很好地理解它。”
参考文献:
可解释的机器学习:制作黑盒模型的指南可解释.Christoph Molnar
机器学习可解释性微课程:Kaggle
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1627
本篇编辑 | 王立鱼
英语原文:
https://towardsdatascience.com/interpretable-machine-learning-1dec0f2f3e6b
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送7张900元门票优惠码,门票原价1999元,打开以下任一链接即可使用,券后仅1099元,限量7张,先到先得,送完即止。
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e4b8b
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e4823
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e453c
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e4214
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e3ed9
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e3c43
https://gair.leiphone.com/gair/coupon/s/5d1b08d0e399e



